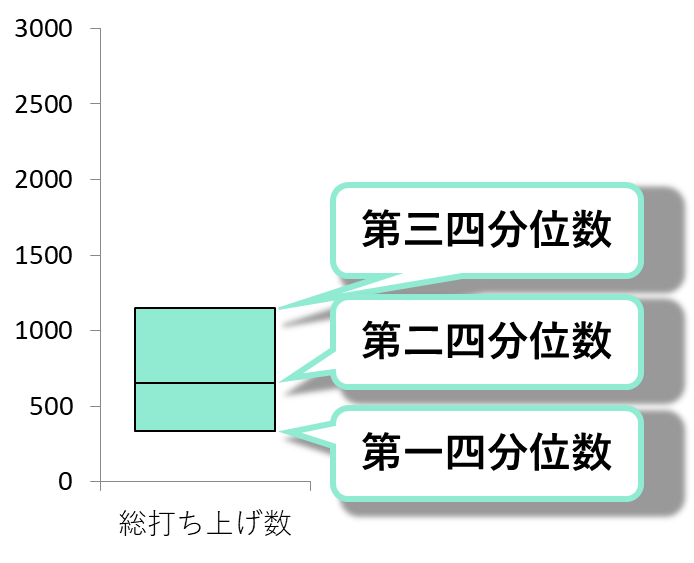
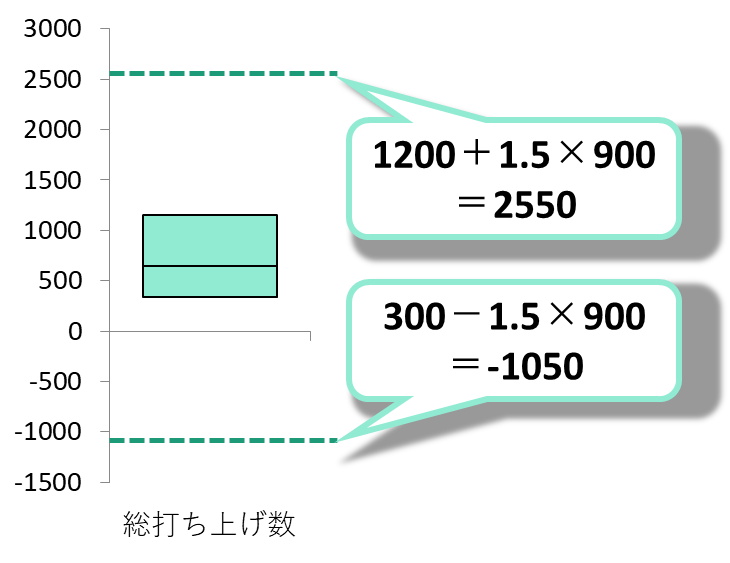
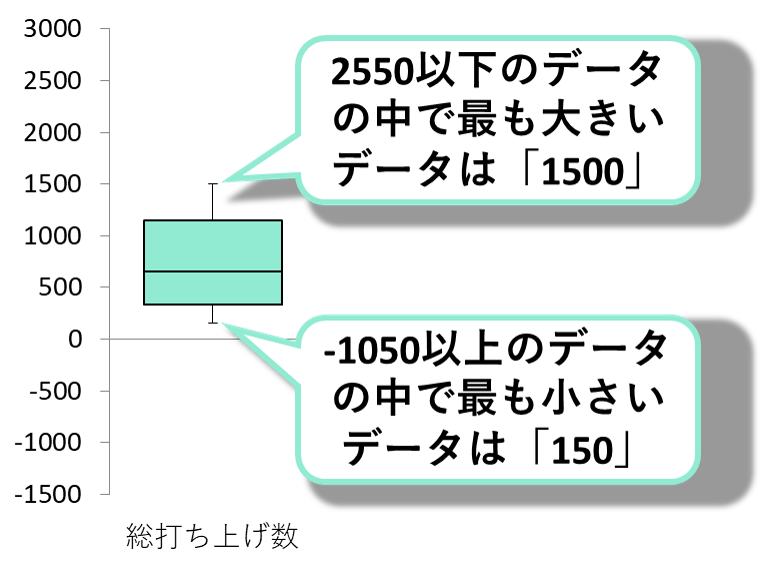
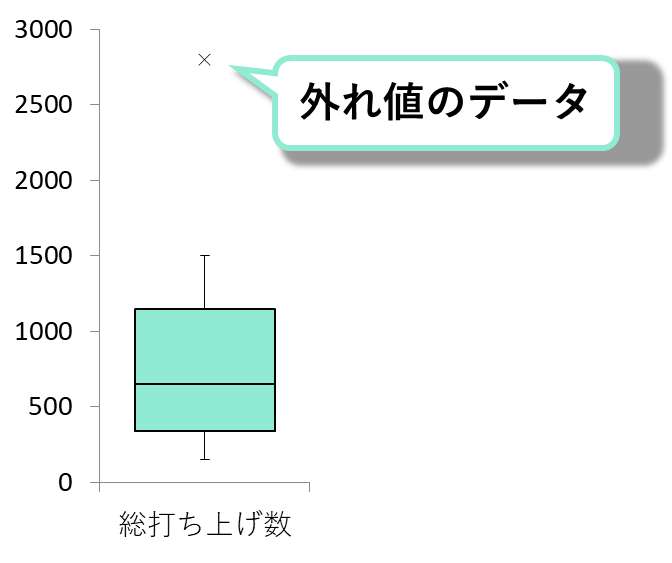
フィッシャーの3原則
実験を行う際には実験計画を立てる必要があります。実験計画とは、よい結果を得るために最も効果的な実験を計画し、その実験で得られたデータに対して最適な解析手法を採択する手順のことです。実験計画を立てずに闇雲に実験を行ってしまうと、お金や時間や労力がかかってしまうだけではなく、信頼できる結果が得られない可能性があります。
そのため、R.A. Fisherがこの実験計画法に関して3つの原則を確立しました。この原則は次の3つから成ります。
- 反復(replication)
- 無作為化(randomization)
- 局所管理(local control)
■反復
複数の処理を比較する際に、それぞれの処理に対して同じ条件で2回以上の繰り返し実験(評価)を行うことです。1回の測定では、測定値に違いがあっても「系統誤差(処理の違いによる差)」なのか、それとも「偶然誤差(たまたま生じる誤差)」なのかは判断できません。反復実験を行って偶然誤差のばらつきが分かれば真の平均のとりうる範囲を推測でき、この範囲よりも系統誤差が大きければ処理によって違いがあるという判断ができます。つまり反復によって、偶然誤差の大きさを評価することができるわけです。
例えば比較したい処理がA、B、Cの3つあり、1日に6回の実験ができる場合、「反復」は次に示すように3日間で各処理を6回ずつ行うことを指します。
| 1日目 | 2日目 | 3日目 | |
|---|---|---|---|
| 処理 | AAAAAA | BBBBBB | CCCCCC |
■無作為化
実験の順序や場所などが複数ある場合に、比較したい処理群を無作為に(ランダムに)割り付けることです。目的とする要因以外に結果に影響を与える要因がある場合に、無作為化によってその影響の偏りをできるだけ小さくすることができます。つまり、系統誤差を偶然誤差に取り込むことができるわけです。
上で挙げた反復実験に「無作為化」を加えた実験デザインは次のようになります。「無作為化」はA、B、Cの処理を行う順番をランダムに割り付けることを指します。
| 1日目 | 2日目 | 3日目 | |
|---|---|---|---|
| 処理 | ACCBAA | CBABBC | BABCCA |
■局所管理
実験を行う時間や場所を区切ってブロックを作り、そのブロック内でのバックグラウンドができるだけ均一になるように管理することです。局所管理により系統誤差を小さくすることができます。
上で挙げた反復実験+無作為化割り付けに「局所管理」を加えた実験デザインは次のようになります。「局所管理」は実験を行う時間を午前と午後の2つのブロックに分けることを指します。
| 1日目 | 2日目 | 3日目 | |
|---|---|---|---|
| 処理(午前) | ACC | CBA | BAB |
| 処理(午後) | BAA | BBC | CCA |
■乱塊法
フィッシャーの3原則である「反復」と「無作為化」に加えて「局所管理」も盛り込んだ実験デザインを「乱塊法」といいます。乱塊法とは、実験計画において実験全体を無作為化するのではなく、局所管理の考えに基づくブロック内に1セットの実験を集めて無作為化を行う方法のことです。
これまで挙げたA、B、Cの3つの実験を乱塊法によって割り付けすると次のようになります。
| 1日目 | 2日目 | 3日目 | |
|---|---|---|---|
| 処理(午前) | ACB | CBA | CAB |
| 処理(午後) | BAC | BAC | CBA |
'지식 > 경제수학' 카테고리의 다른 글
| [경제통계] 귀무가설과 대립가설, Z검정, P-value과 유의수준 비교에 따른 귀무가설 기각 (0) | 2023.09.21 |
|---|---|
| 코램그래프와 자기상관 (0) | 2018.10.06 |
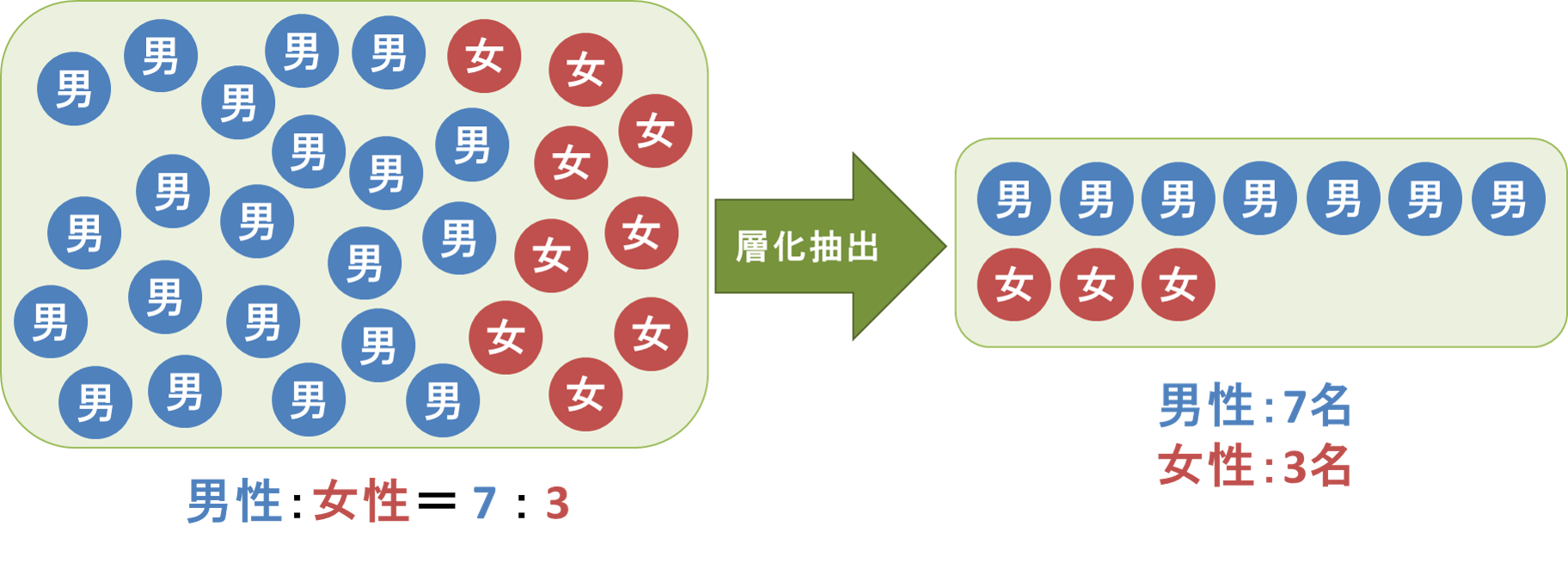
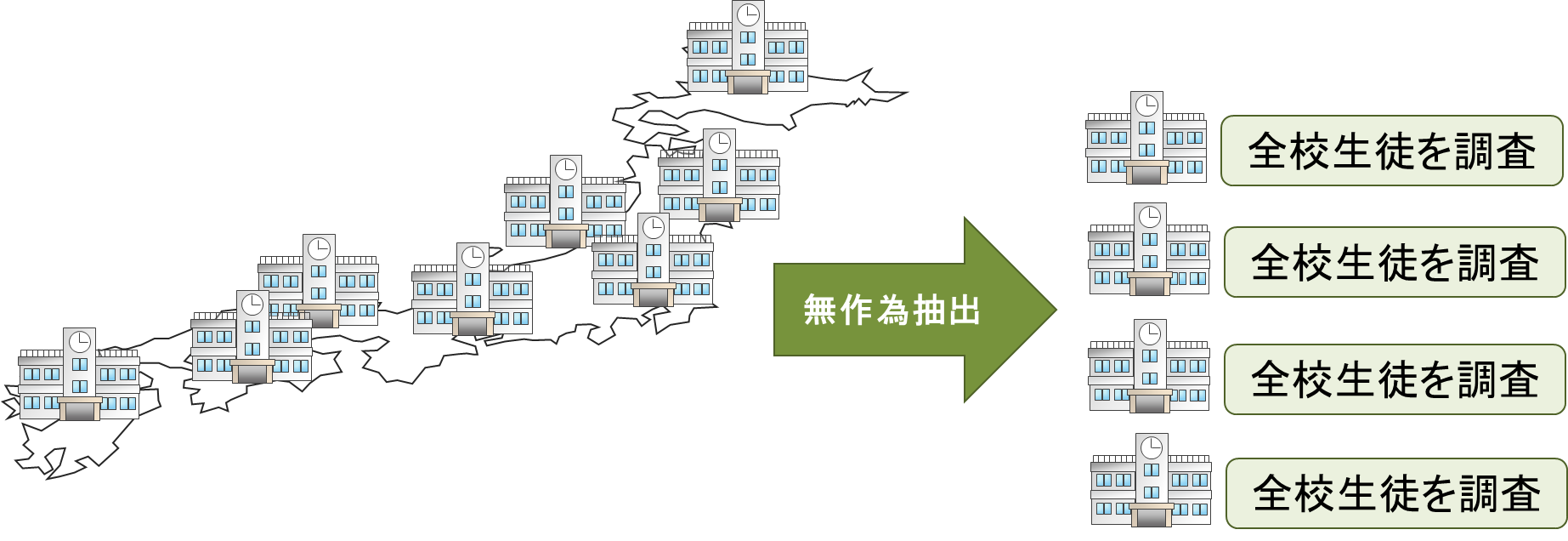
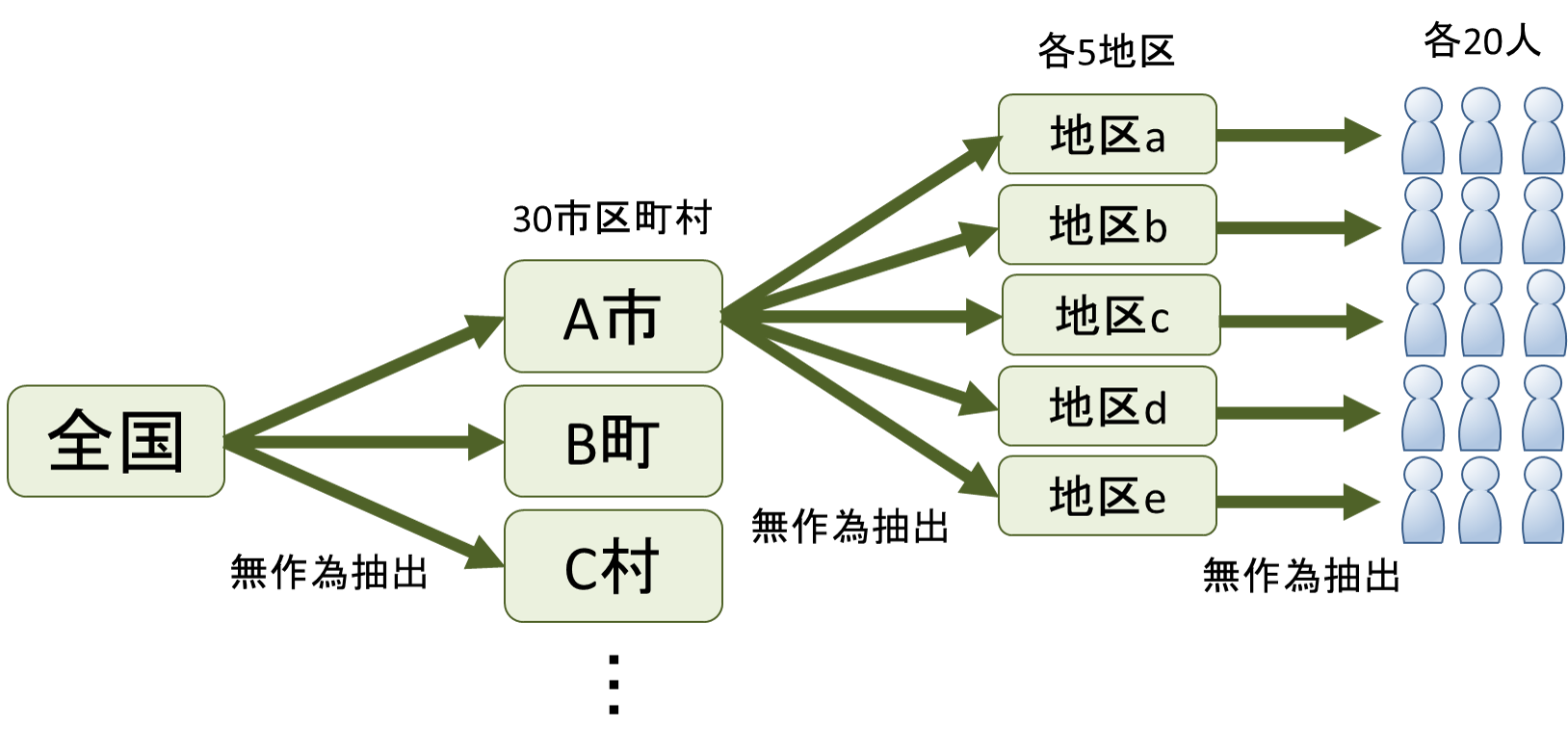
| 추출의 방법(층화추출법,클러스터추출법,다단추출법,계통추출법) (0) | 2018.09.20 |
| 로렌츠곡선과 지니계수 (0) | 2018.09.19 |
| 편상관계수 (0) | 2018.09.19 |






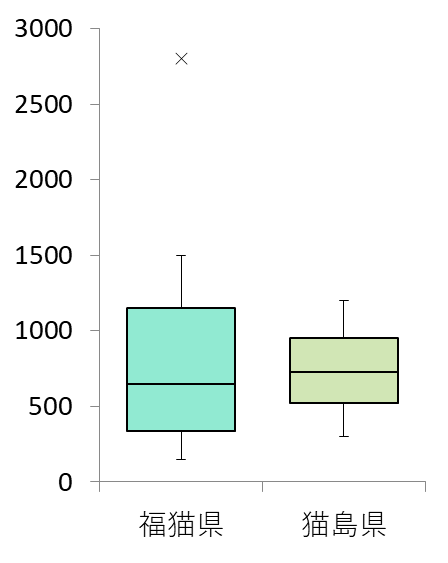
 となります。このようにして作成した度数分布表が次の表です。
となります。このようにして作成した度数分布表が次の表です。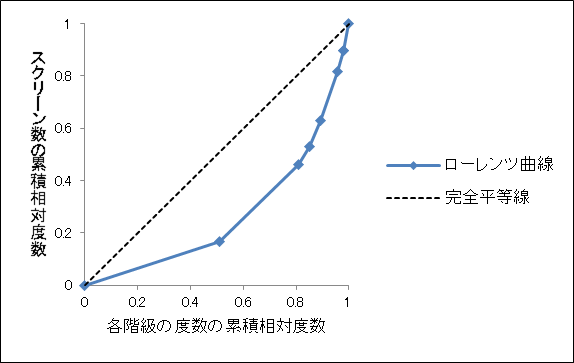
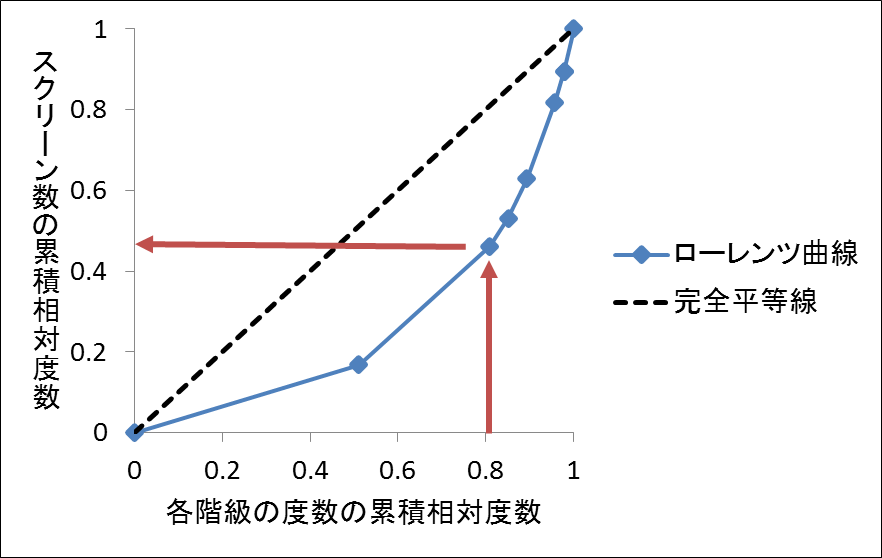
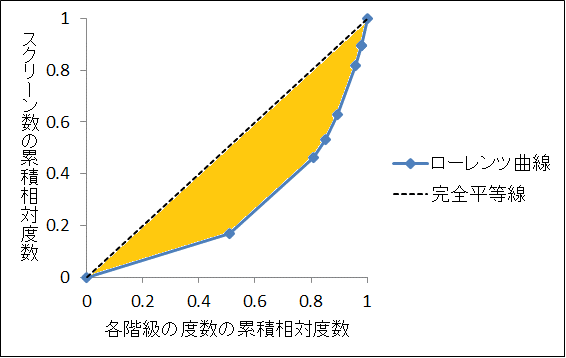
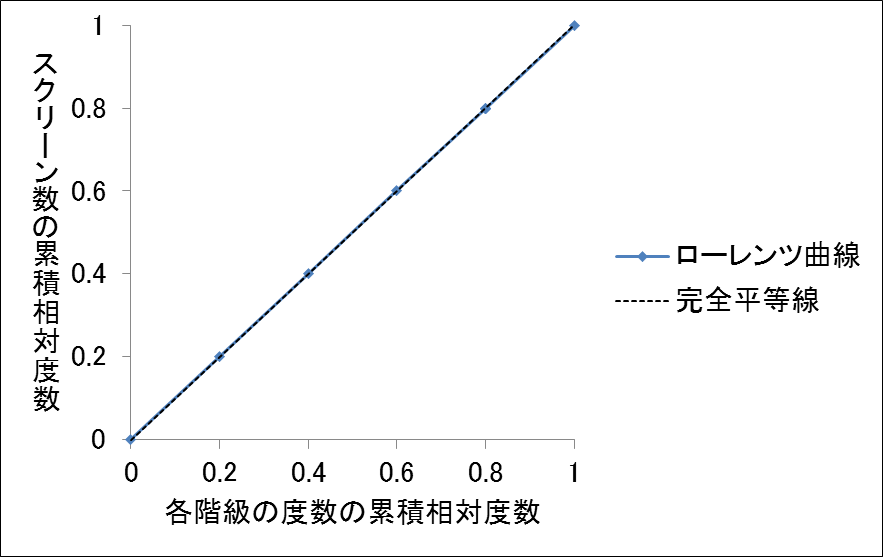
 当たりの薬局数を表したものです。このデータを用いて
当たりの薬局数を表したものです。このデータを用いて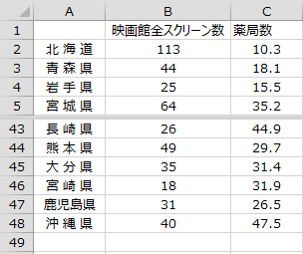
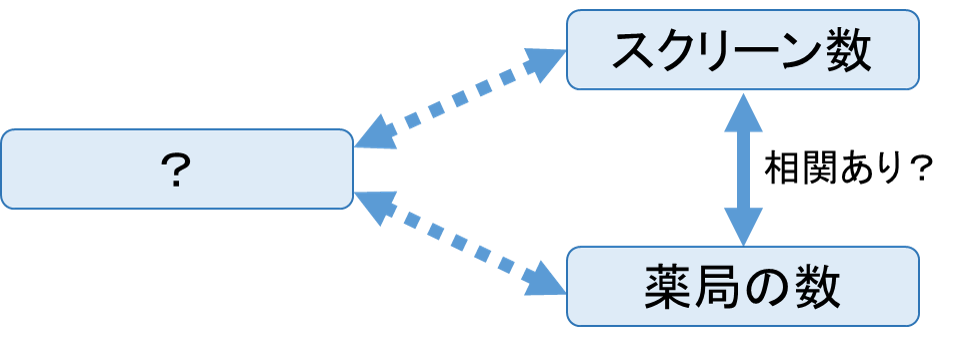
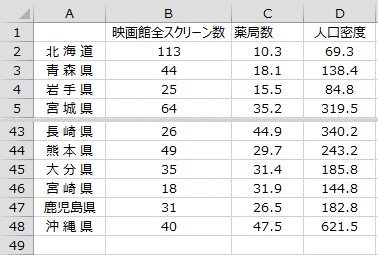
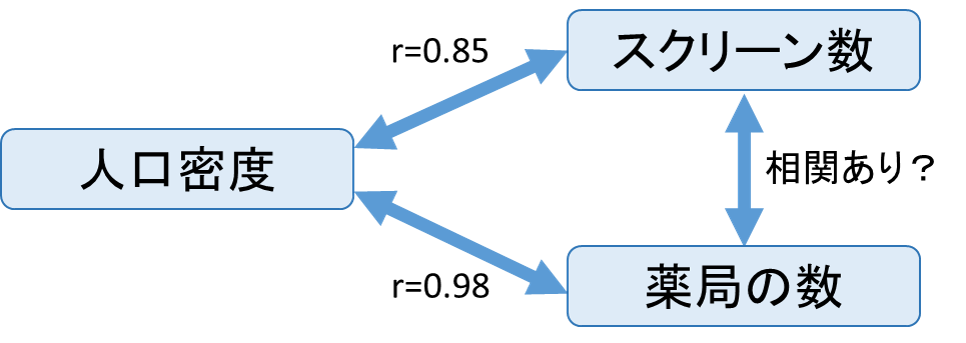
 、yとzの相関係数を
、yとzの相関係数を 、zとxの相関係数を
、zとxの相関係数を とします。これらを用いると、zの影響を除いたxとyの偏相関係数
とします。これらを用いると、zの影響を除いたxとyの偏相関係数 を次の式から求められます。
を次の式から求められます。
 、
、 、
、 となるので、偏相関係数
となるので、偏相関係数
 :基準年の価格
:基準年の価格  :基準年の数量
:基準年の数量 :比較年の価格
:比較年の価格  :比較年の数量
:比較年の数量