[https://yeomko.tistory.com/37]
우리는 지금까지 데이터를 특정한 확률 분포를 가진 확률 변수로 모형화 하였습니다. 그리고 모집단의 표본에서 얻은 통계량을 통해 모집단의 통계적 특성을 추측해보았습니다. 이러한 과정을 논리적으로 전개하기 위해서 필요한 것이 가설과 검정입니다.
가설(hypothesis)란 확률 분포에 대한 어떠한 주장이며 이를 증명하는 행위를 검정(testing)이라 합니다. 특히 확률 분포의 모수 값에 대한 가설을 검정하는 것을 모수 검정(parameter testing)이라 부릅니다.
귀무 가설과 대립가설
귀무가설, 영가설이라고도 불리며 영어로는 null hypothesis다. 곧 이슈가 제시하는 가설을 그대로 따른다는 의미다. 예를 들어, 어떤 기사에서 성인 남성 평균 수명시간이 8시간이라고 했다. 그러나 연구자는 성인남성은 8시간보다 더 적게 잘 것이라는 가설을 갖고 있다. 이때 영가설은 "성인 남성 수면시간은 8시간이다"이고, 귀무가설은 8시간미만 혹은 8시간 초과가 될 수 있다.. 기본적으로 참으로 추정되며 이를 거부하기 위해서는 증거가 반드시 필요합니다. 예를들어 형사가 용의자를 잡았을 경우에도 무죄 추정의 원칙에 따라서 '이 용의자는 무죄일 것이다' 라는 가설을 먼저 세우게 됩니다.[1] 귀무 가설을 세울 때에는 특별한 증거가 없다면 참으로 여겨지는 가설을 귀무 가설로 세우게 됩니다.
대립 가설(alternative hypothesis)는 귀무 가설과 대립되는 가설을 말합니다. 위 예시를 대입해보면 '이 용의자가 범인일 것이다!'가 됩니다. 일반적으로 연구자는 연구를 통해 귀무 가설을 검증하게 되고, 이를 통해서 대립 가설이 입증되기를 기대합니다. 즉, 용의자가 무죄일 것이다를 전제로 하고 이를 깨기 위해 열심히 증거를 찾게 되는 것입니다.
귀무 가설과 대립 가설을 기호로 표현하면 아래와 같습니다.

가설 설정의 규칙
통계적 가설을 세울 때에는 다음의 규칙을 따라야 합니다.[3]
1. 귀무 가설은 모수를 특정한 값으로 표현한다. H0:θ=θ0
2. 대립 가설은 귀무 가설에서 지적한 모수의 값이 아닌 어떤 영역으로 나타내는데, 양쪽을 다 고려하는 양측 검정과 한쪽만 고려하는 단측 검정이 있다.

검정과 검정 오류
가설은 맞다, 틀리다로 이분법적으로 답을 내릴 수 있는 문제가 아닌 정도의 문제입니다. 귀무 가설이 틀릴 확률이 얼마이므로 이를 기각한다 / 기각하지 못한다와 같은 형태로 표현할 수 있습니다. 이렇듯 우리는 가설이 틀릴 가능성에 초점을 맞추고 검정을 진행하게 되는데 이 때, 가설이 틀릴 가능성에 대해서 제 1종 오류와 제 2종 오류로 구분합니다.
제 1종 오류(type 1 error)란 귀무 가설이 맞는데도 이를 잘못 기각하여 발생하는 오류입니다. 용의자가 무죄가 맞지만 잘못하여 유죄 판결을 내리는 것과 같습니다. 제 2종 오류(type 2 error)란 대립 가설이 사실임에도 불구하고 귀무가설을 기각하지 못하는 오류를 말합니다. 용의자가 범인이 맞지만 무죄가 아니라는 것을 입증해내지 못하는 것을 말합니다.
제 1종 오류가 발생할 확률을 α라고 표기하고 검정의 유의수준(significance level)이라 합니다. 반대로 제 2종 오류가 발생할 확률을 β라고 표기합니다. 대립 가설이 사실일 때 귀무 가설을 기각할 확률 (1- β)를 검정력이라고 표현합니다. 표로 나타내면 아래와 같습니다.

가설의 검정에서는 이 두 가지 오류인 α, β를 최소로 하는 임계값 c를 결정하고 기각역을 설정하는 것이 중요합니다. 하지만 임계값을 높게 설정하면 β가 커지고, 그렇다고 낮게 설정하면 α가 커지는 모순 관계에 놓여 있습니다. 그렇기 때문에 α를 고정시키고, 이를 만족 시키는 기각역 중에 β를 최소화하는 기각역을 선택하게 되고, 그렇기 때문에 1- β를 검정력이라고 부르는 것입니다. 고정시키는 α 값은 학문 분야에 따라서 다른데 사회과학 분야는 보통 0.05, 자연 과학 분야는 0.01이라는 가이드라인을 제시한다고 합니다.

출처: 정보통신용어해설
이제 귀무 가설을 기각하여 일만 남았으며, 우리는 두 가지 방법을 사용할 수 있습니다.
· p-value 사용하기
· 기각역(rejection area) 사용하기
개념만 말로 설명하기엔 다소 까다로울 수 있으므로 예제를 하나 풀어보면서 진행하도록 하겠습니다.

이때 h자동차가 주장하는 "하이브리드 차량 평균 연비는 16.5km다"가 귀무가설이 됩니다. "오케이 니네가 주장하는대로 일단 믿어볼게" 라는게 귀무가설입니다. 근데 연구자들은 아무리봐도 16.5km보다 적을 것 같습니다. 따라서 대립가설은 16.5km/L보다 적다라는 대립가설을 세웁니다.
이 하이브리드 자동차의 연비는 정규분포를 따른다고 가정하면, Z분포를 통한 검정을 수행할 수 있습니다. 표본 10개를 샘플링해서 조사해봤더니 연비가 15km/L밖에 안나옵니다. 이 15km/L를 z분포로 변경하면 아래와 같습니다.
15km/L는 Z분포로 환산하면 -3.16이 나오고 이 확률은 0.0008입니다.

이때 유의수준 0.05를 Z분포의 단측검증으로 바꿔보면 -1.645가 나오고 이를 기존 정규분포로 환산하면 15.72km/L가 나옵니다. 유의수준이란 "너네가 평균 연비 16.5km/L라고 주장했는데, 그거 맞다고 가정하고 샘플링 조사를 좀 해볼게. 그런데 샘플링을 전부하는건 아니니까 샘플링 오류를 생각해서 임계치를 Z분포의 하위 5%라고 가정하면, 아무리 못해도 15.72km는 나와야 그나마 좀 믿을만하다? 그 이하는 나가리야?!" 라고 주장하는 것입니다. 유의수준이란 용서해줄 수 있는 임계치라는 뜻입니다.
그런데 위의 샘플링에선 15km/L밖에 나오지 않았으니, 용서해줄 수 있는 수준 = 임계치 = 유의수준 15.72km/L보다 훨씬더 적은 숫자가 나왔습니다. 즉, P-Value가 유의수준 α보다 적으면 귀무가설을 기각하게 됩니다.
'지식 > 경제수학' 카테고리의 다른 글
| 코램그래프와 자기상관 (0) | 2018.10.06 |
|---|---|
| 피셔3원칙 (0) | 2018.09.20 |
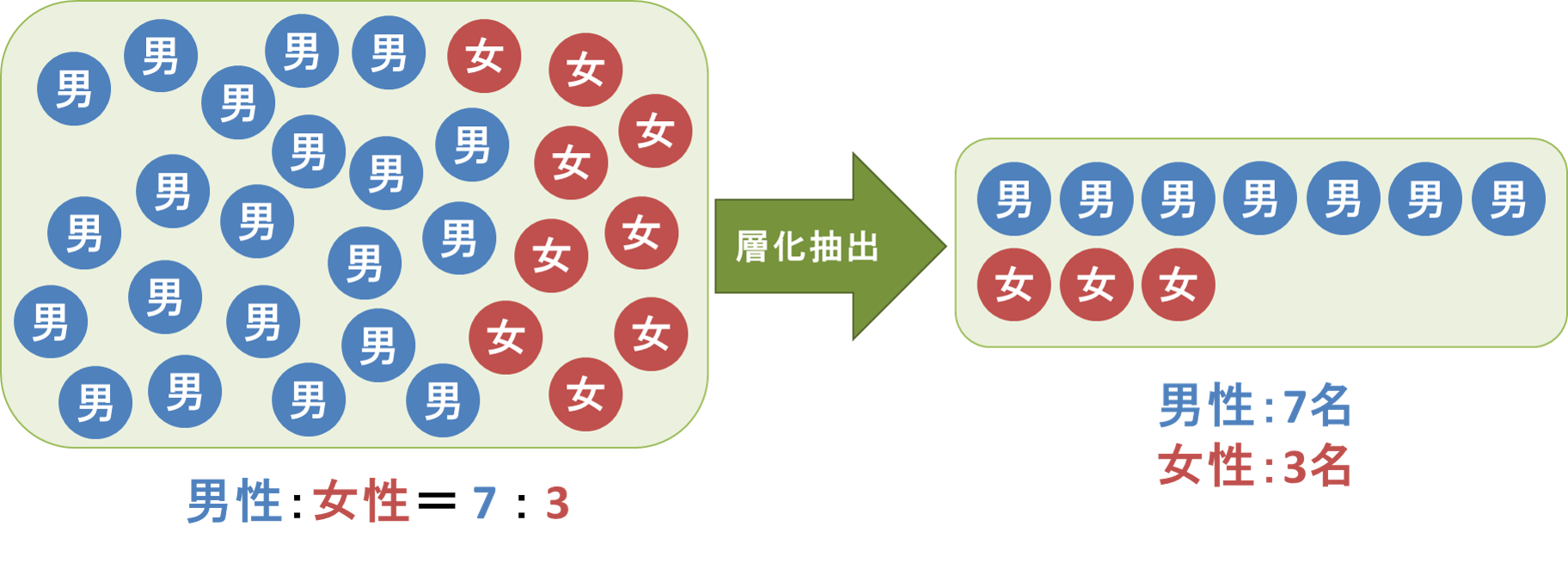
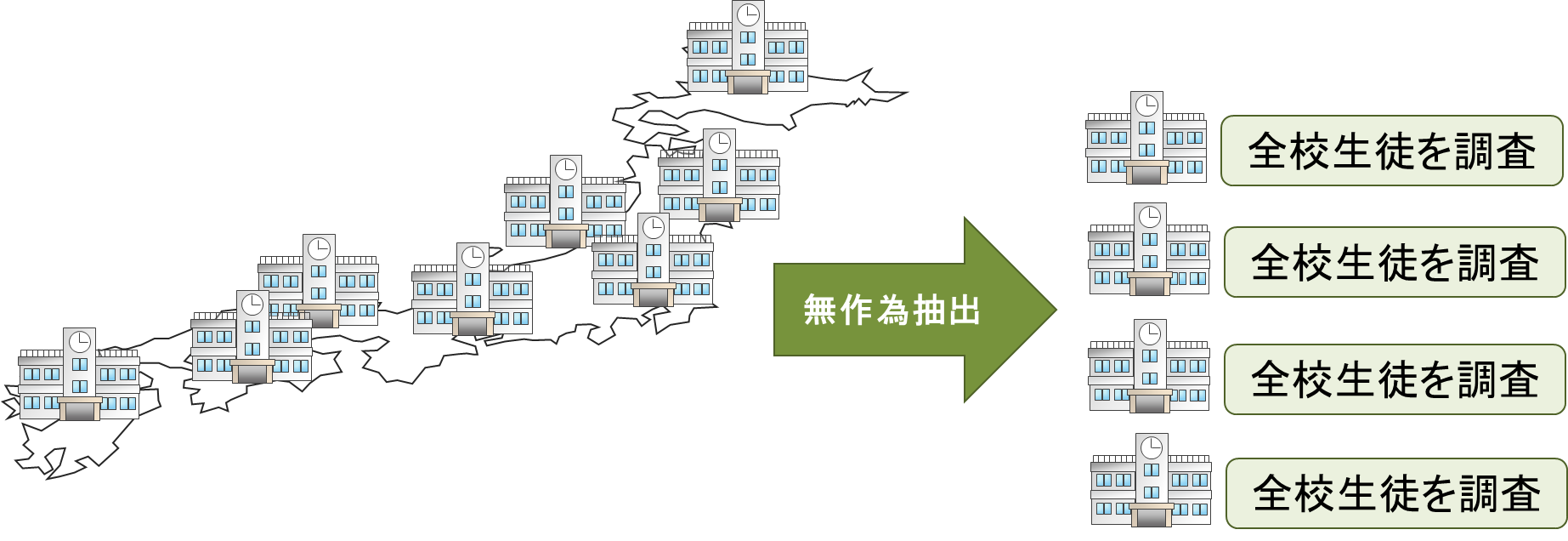
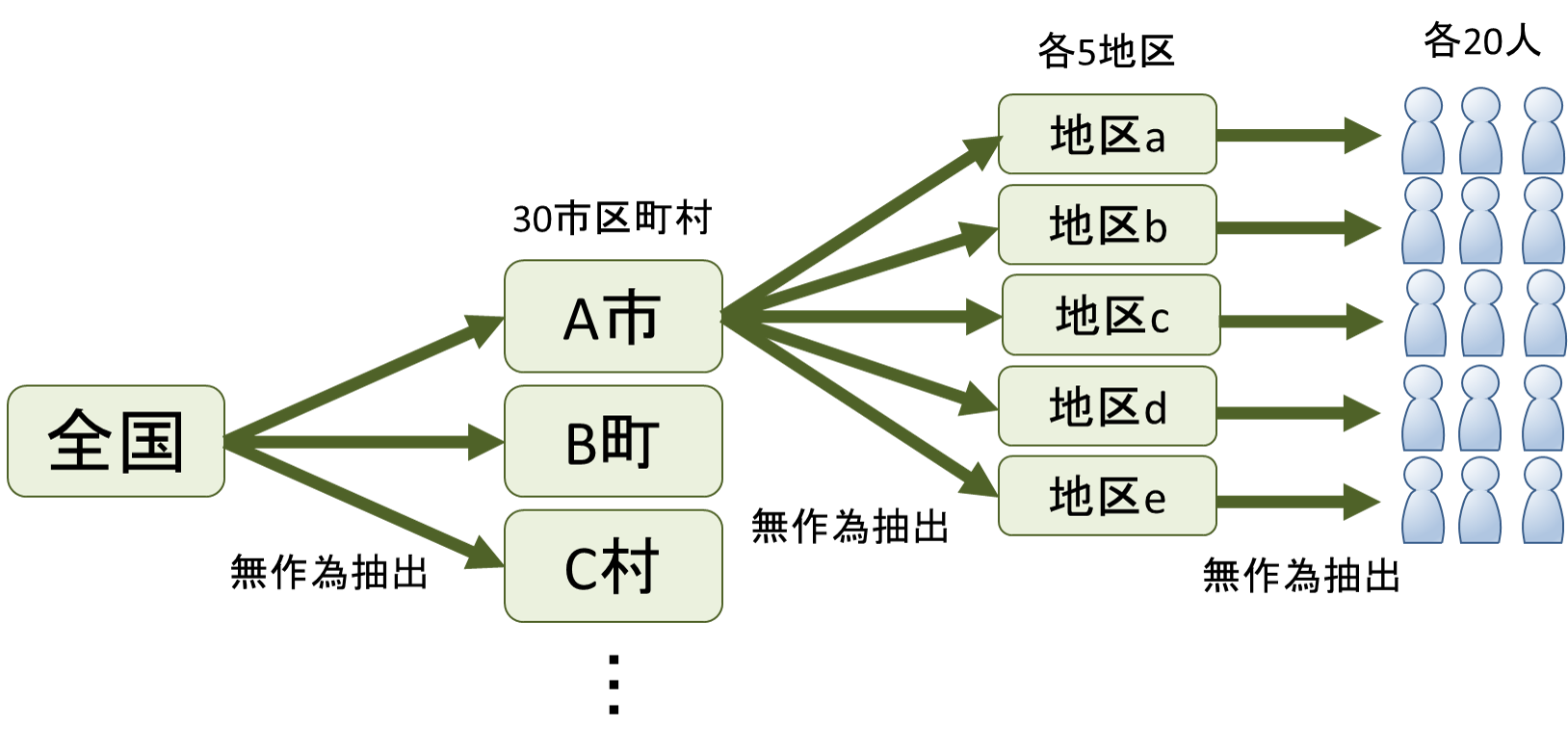
| 추출의 방법(층화추출법,클러스터추출법,다단추출법,계통추출법) (0) | 2018.09.20 |
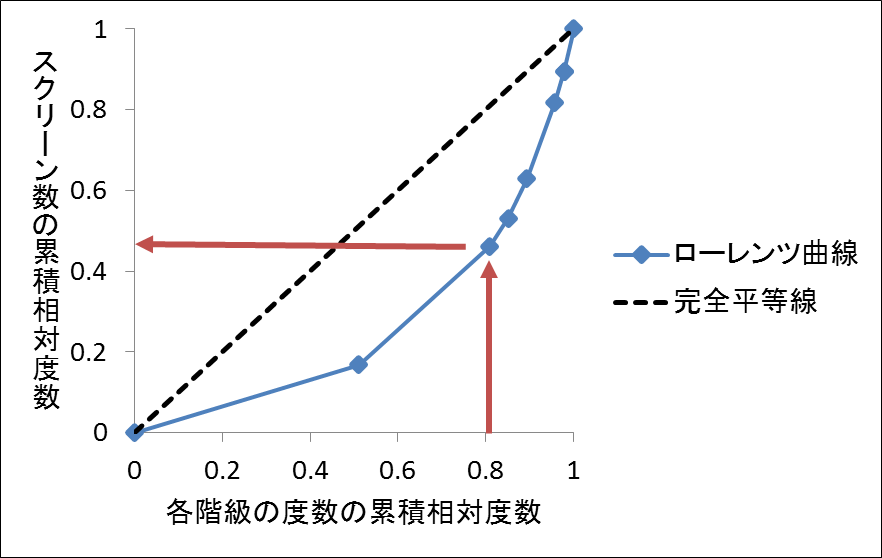
| 로렌츠곡선과 지니계수 (0) | 2018.09.19 |
| 편상관계수 (0) | 2018.09.19 |






 となります。このようにして作成した度数分布表が次の表です。
となります。このようにして作成した度数分布表が次の表です。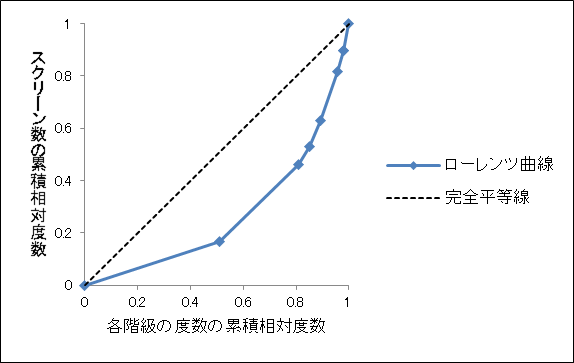
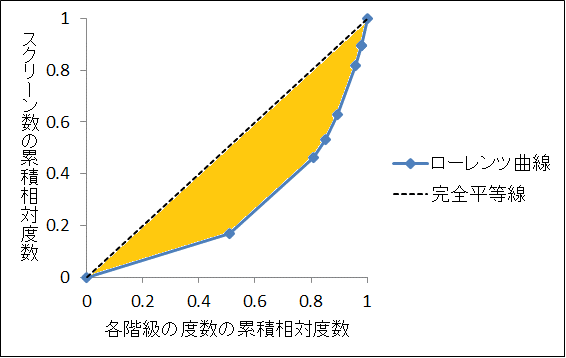
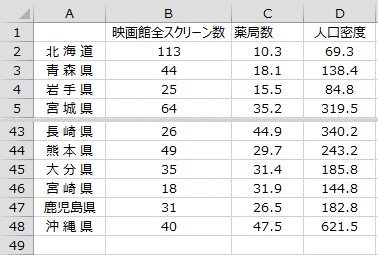
 当たりの薬局数を表したものです。このデータを用いて
当たりの薬局数を表したものです。このデータを用いて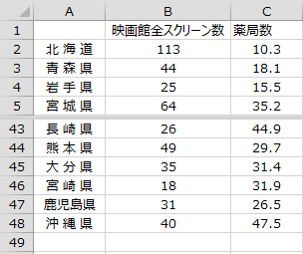
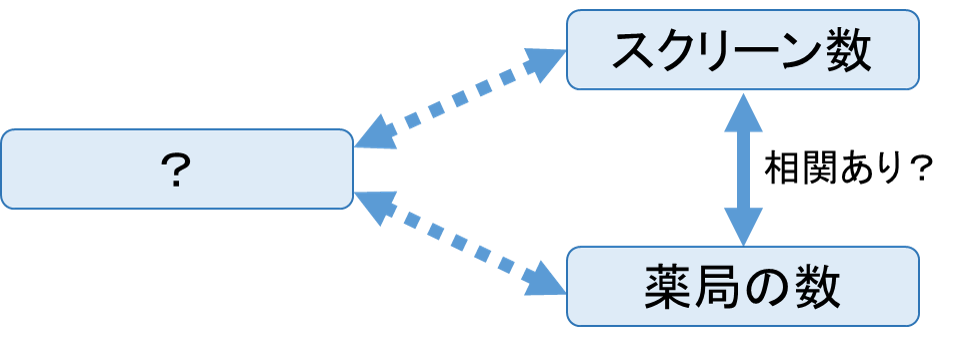
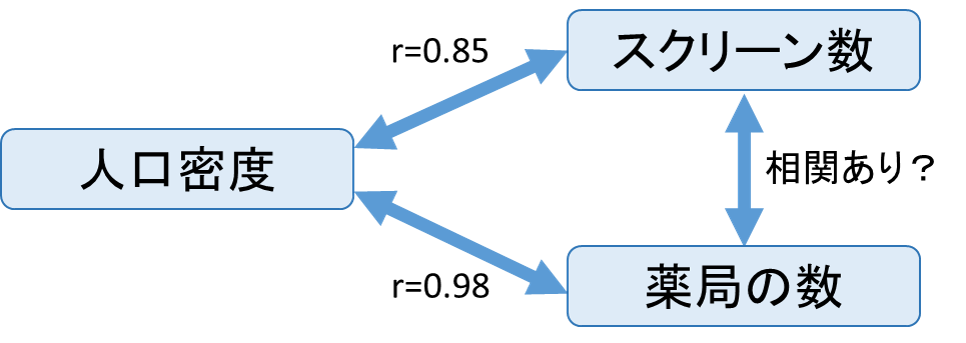
 、yとzの相関係数を
、yとzの相関係数を 、zとxの相関係数を
、zとxの相関係数を とします。これらを用いると、zの影響を除いたxとyの偏相関係数
とします。これらを用いると、zの影響を除いたxとyの偏相関係数 を次の式から求められます。
を次の式から求められます。
 、
、 、
、 となるので、偏相関係数
となるので、偏相関係数
 :基準年の価格
:基準年の価格  :基準年の数量
:基準年の数量 :比較年の価格
:比較年の価格  :比較年の数量
:比較年の数量