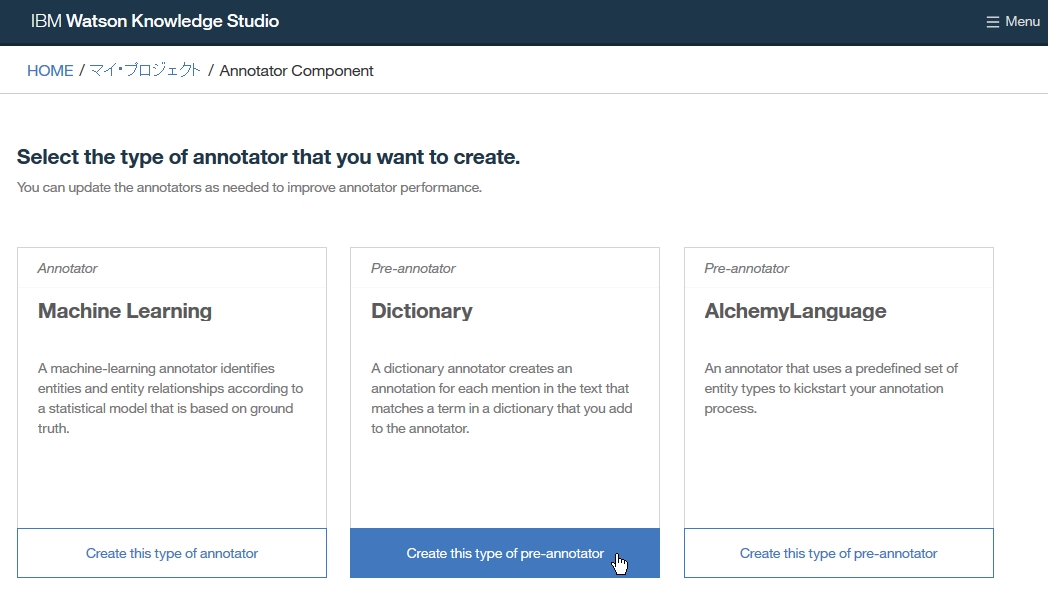
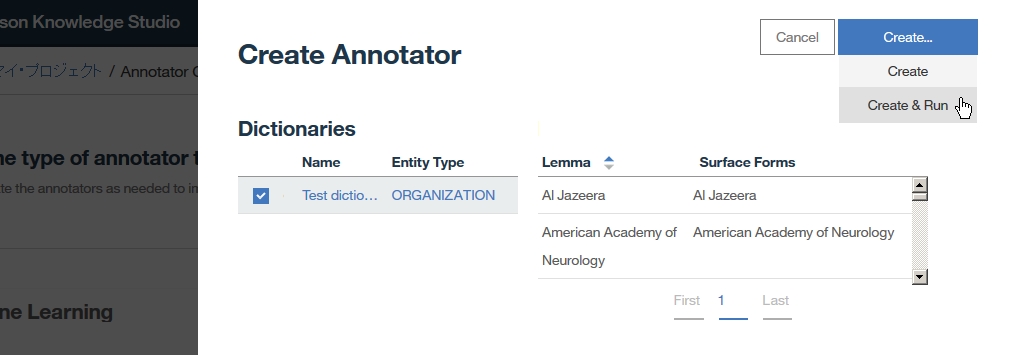
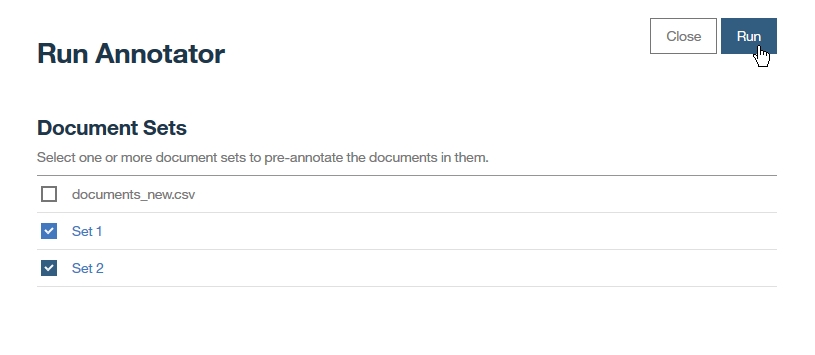
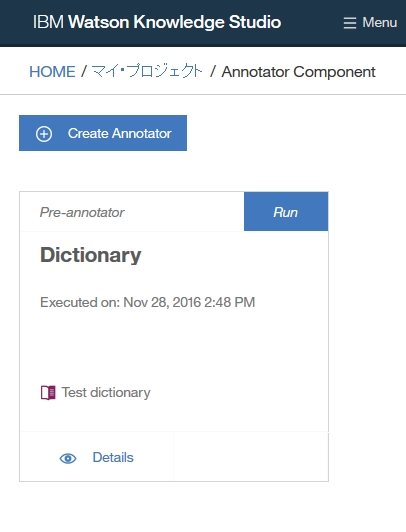
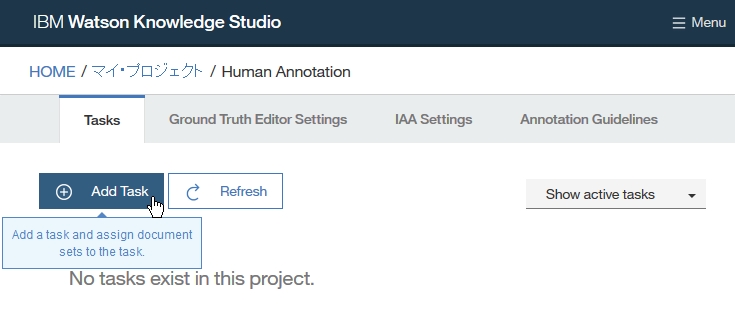
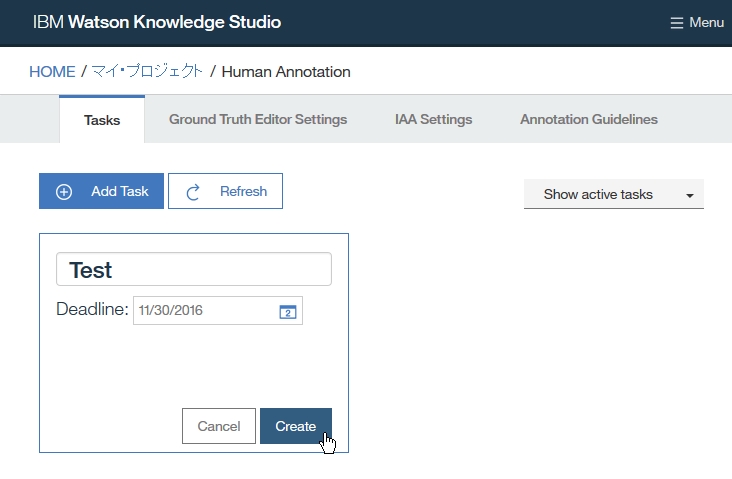
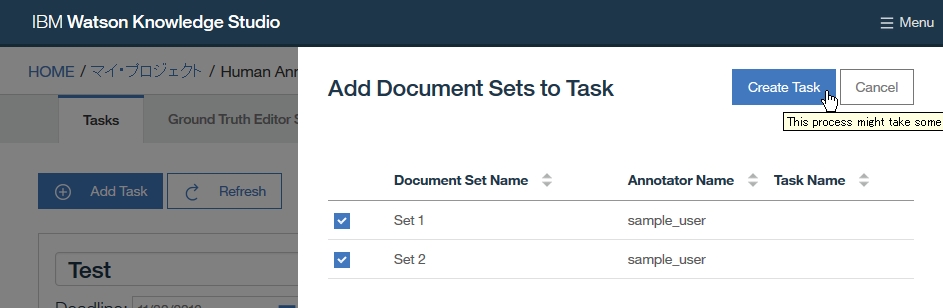
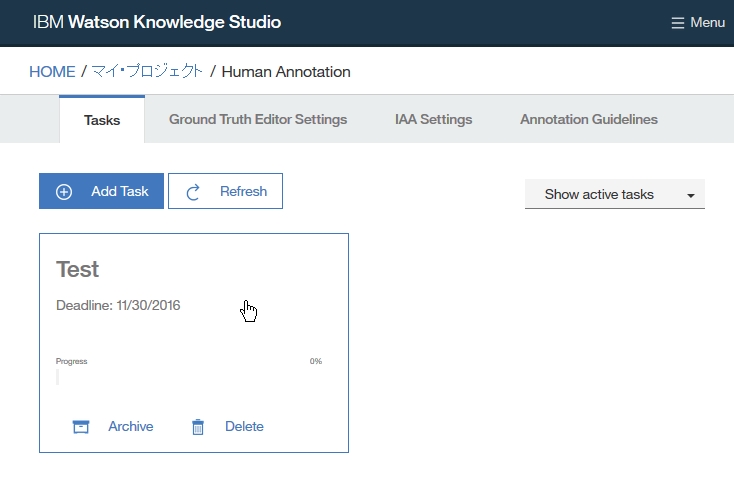
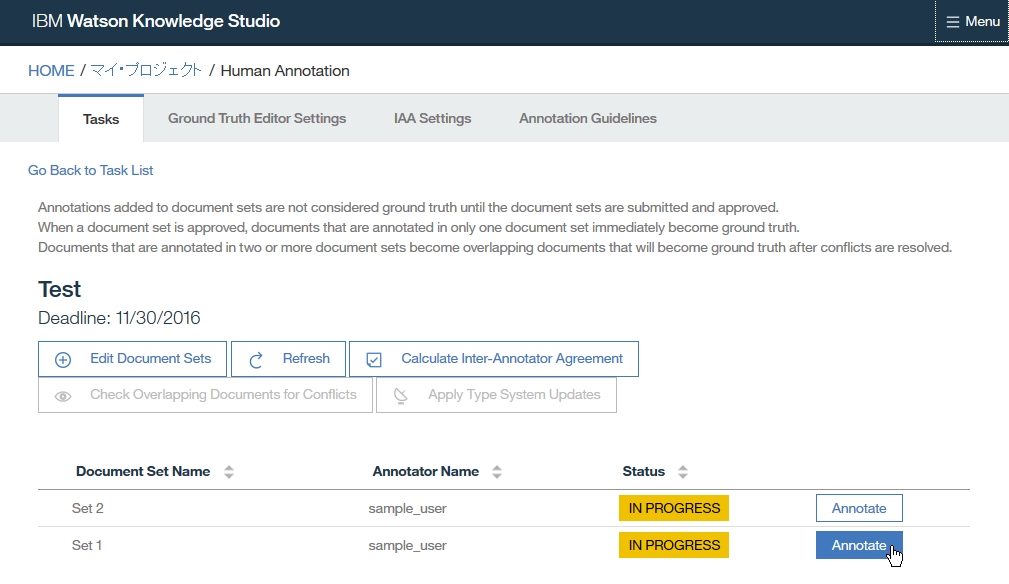
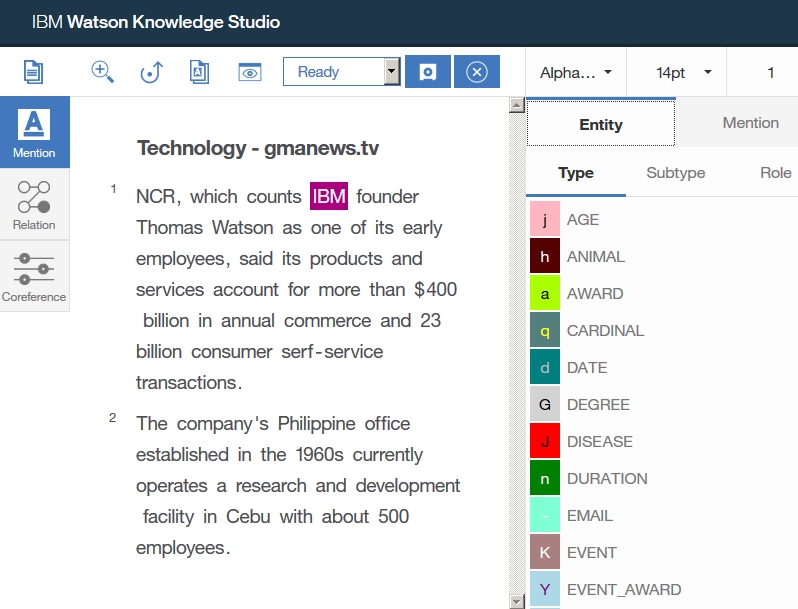
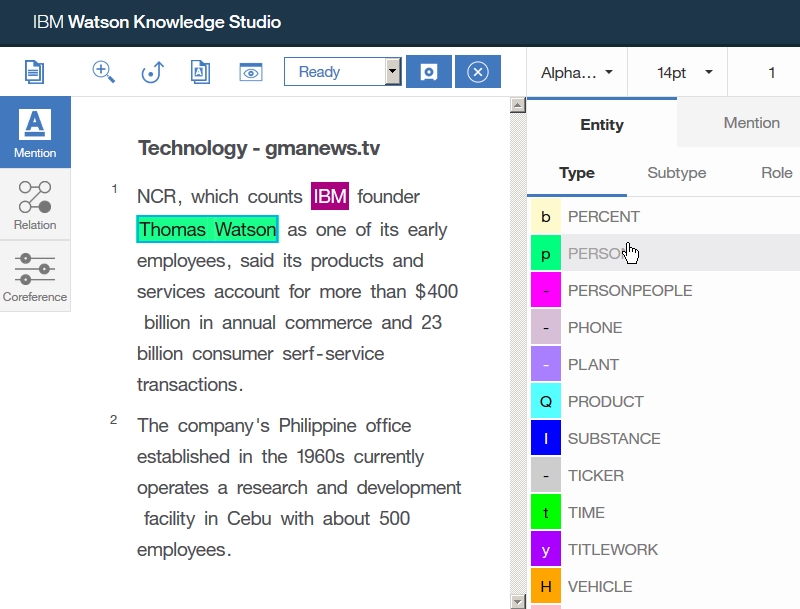
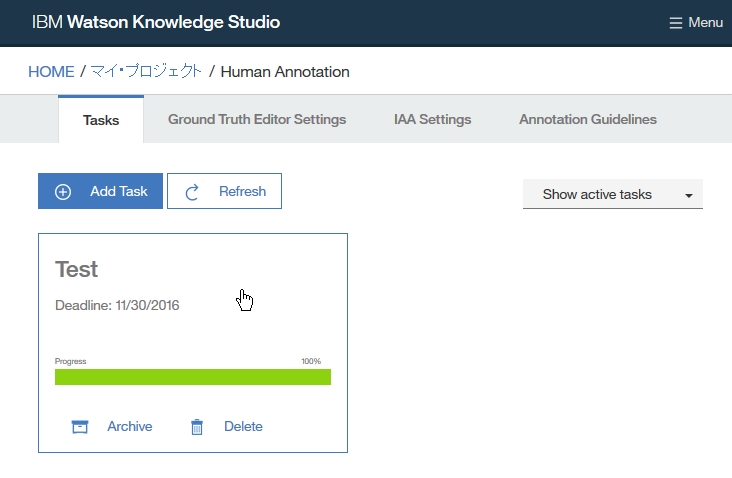
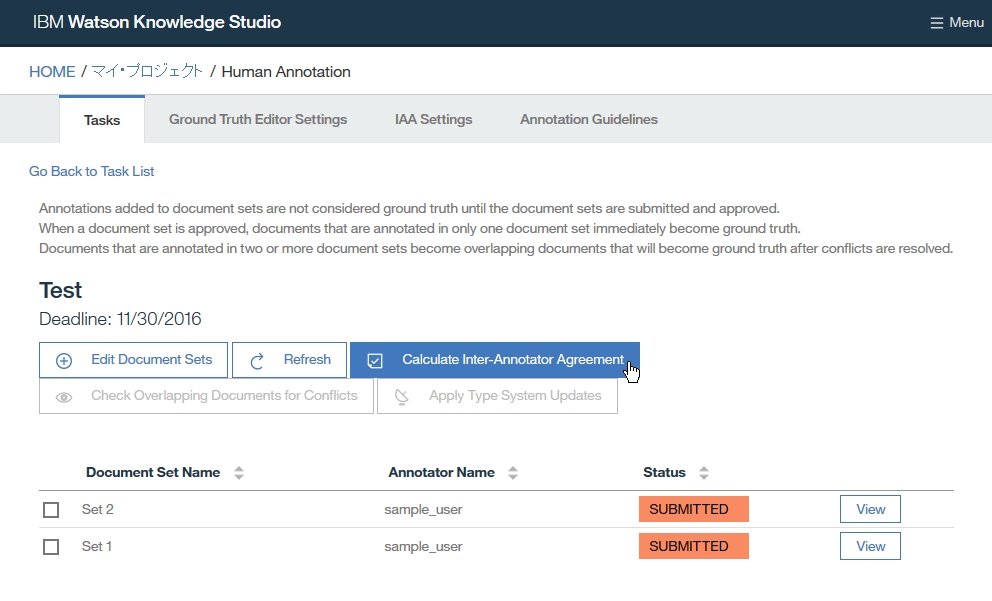
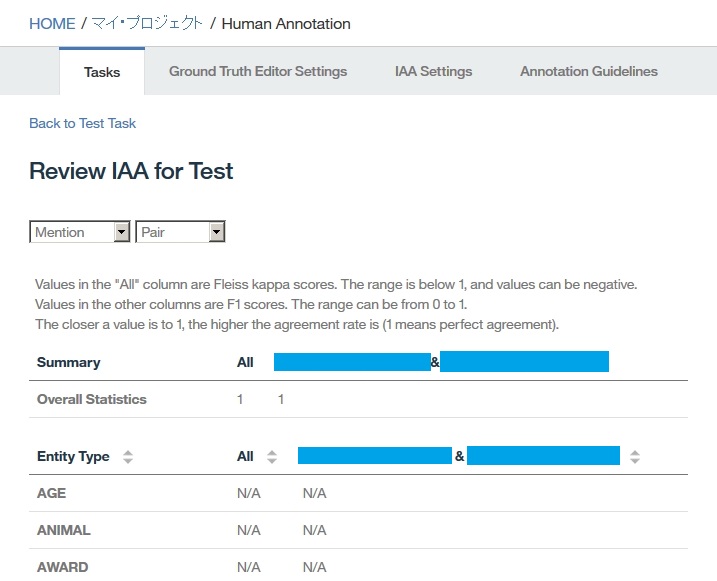
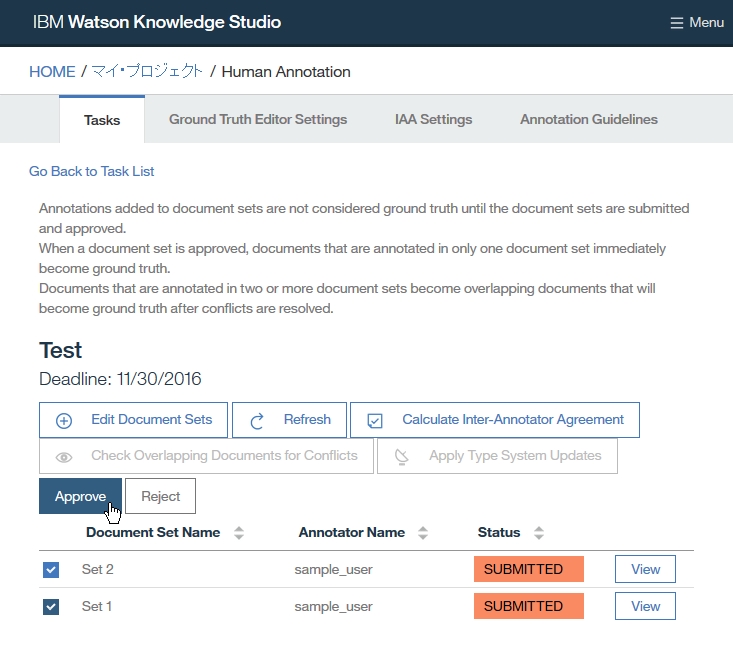
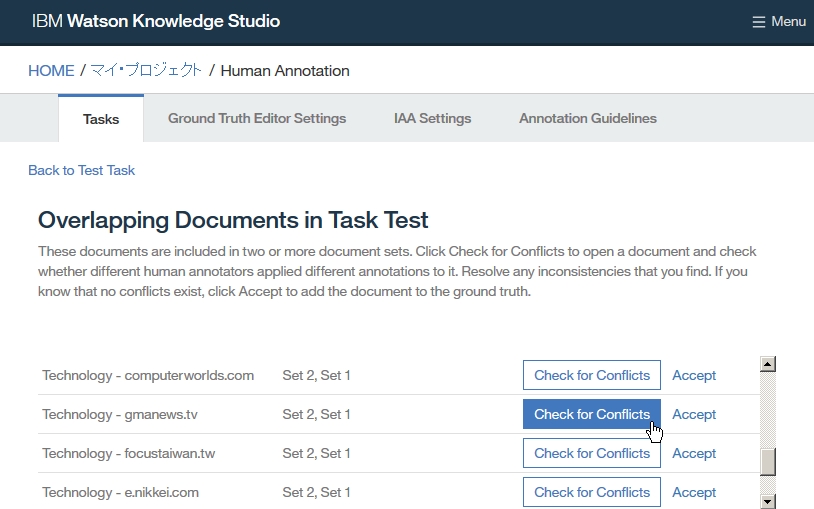
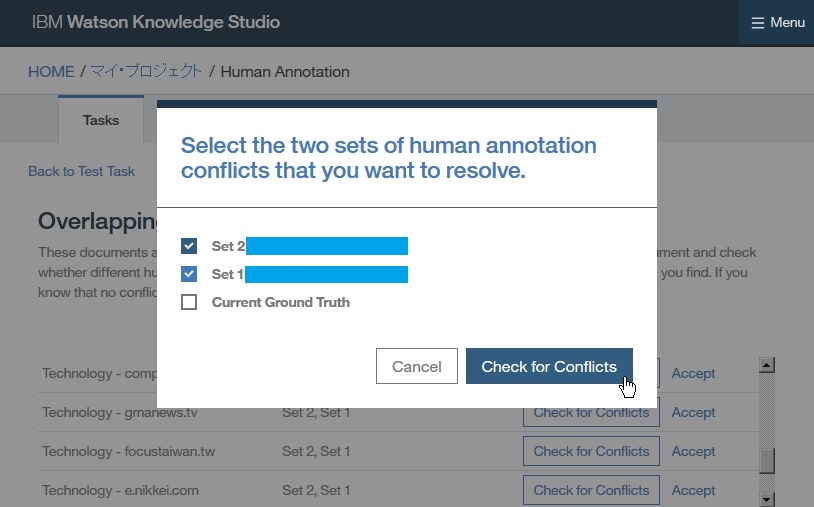
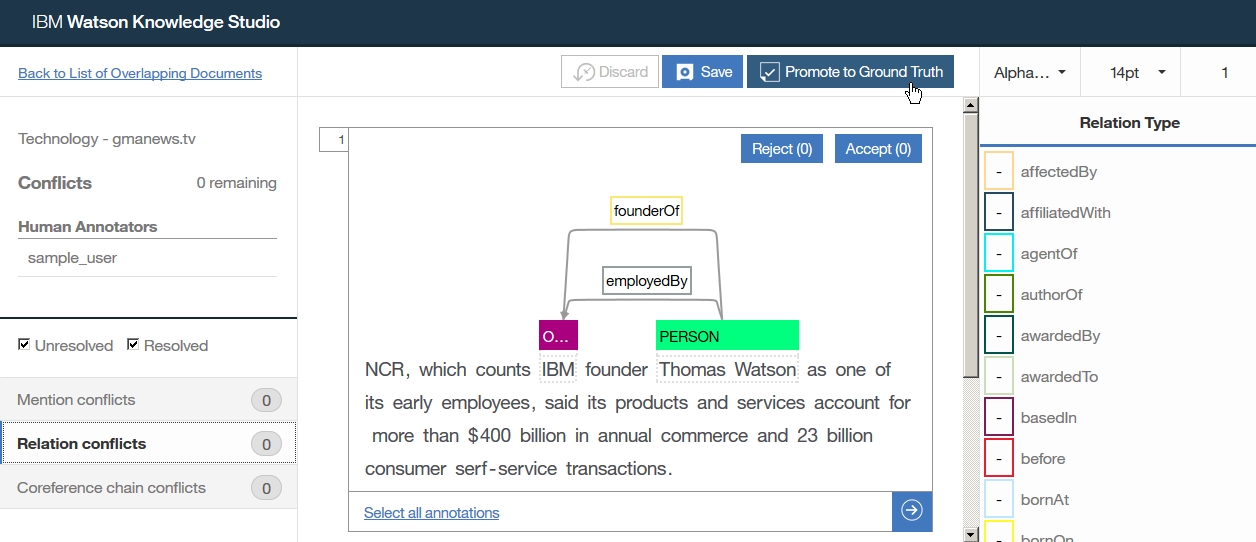
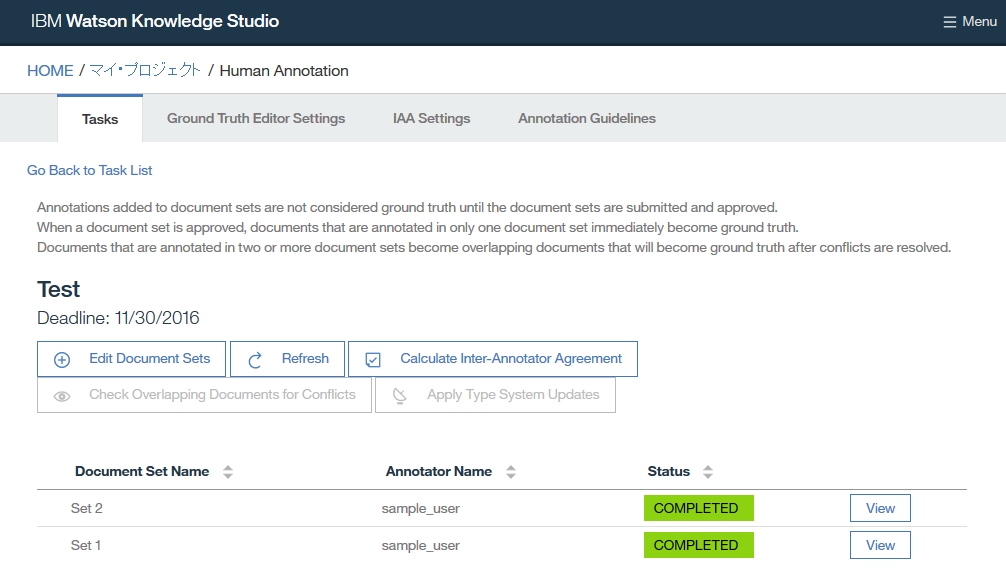
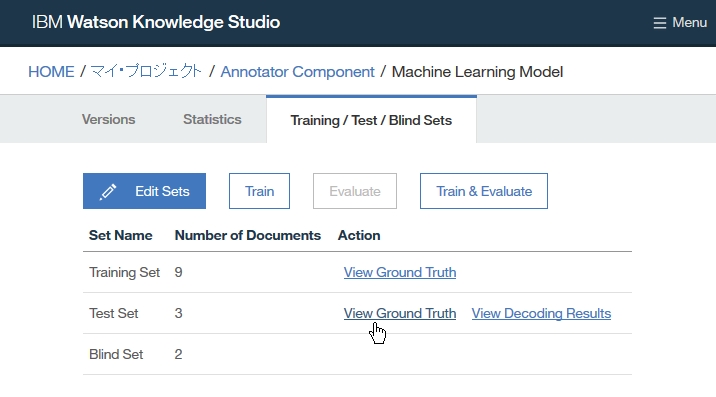
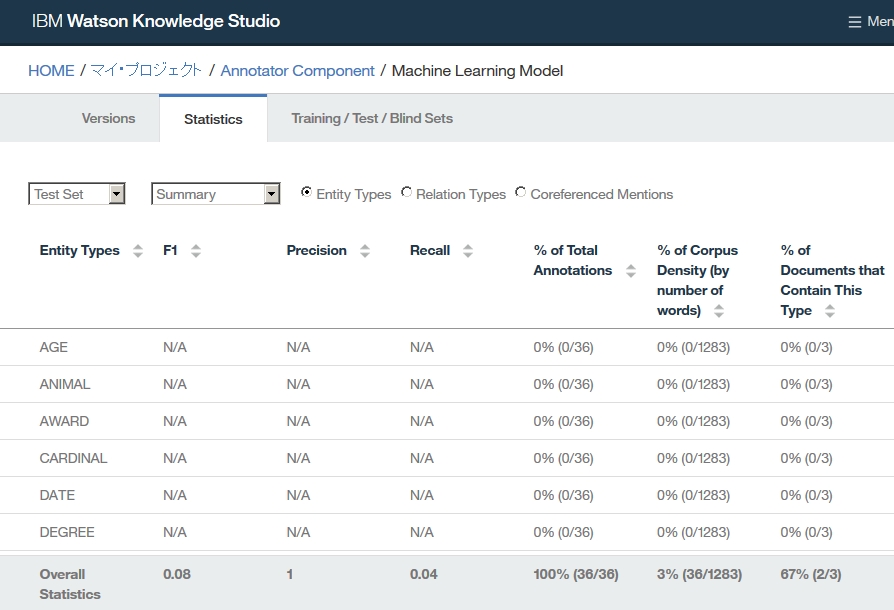
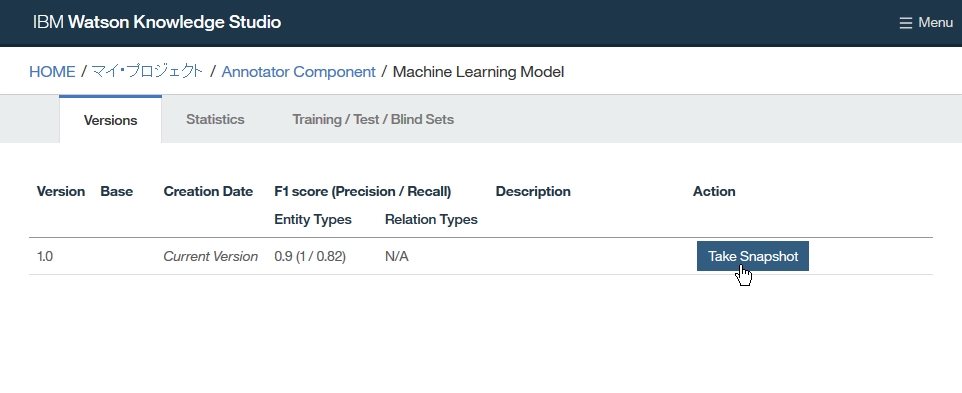
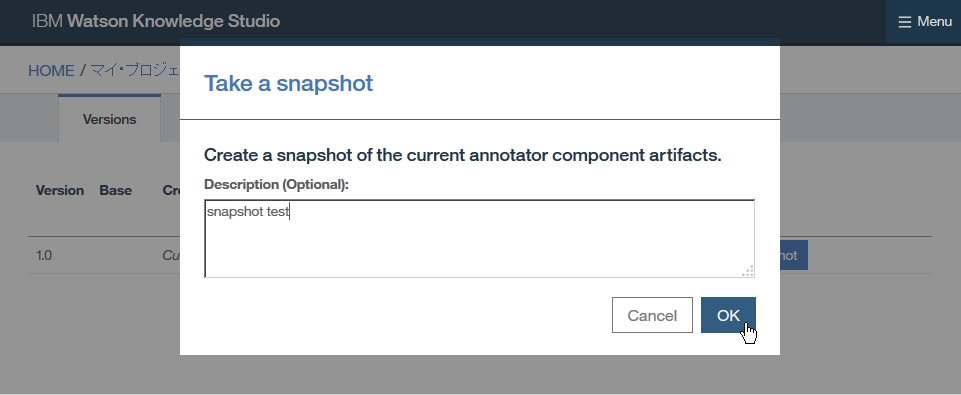
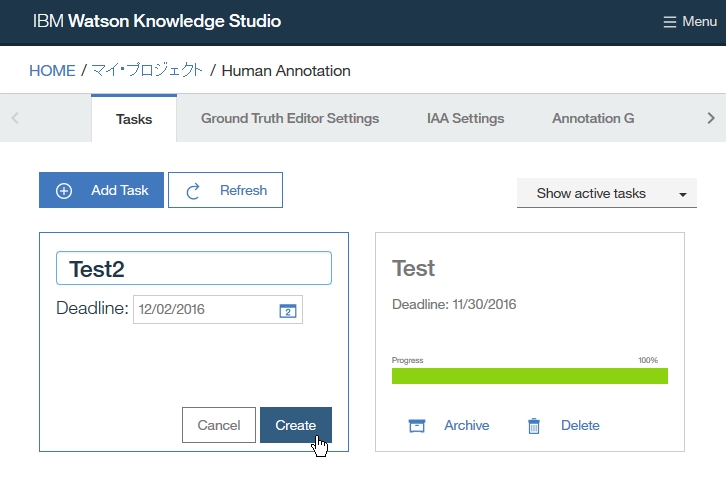
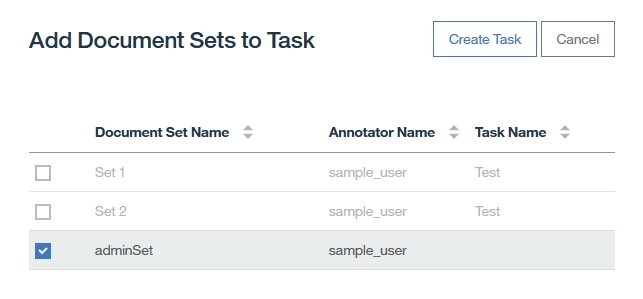
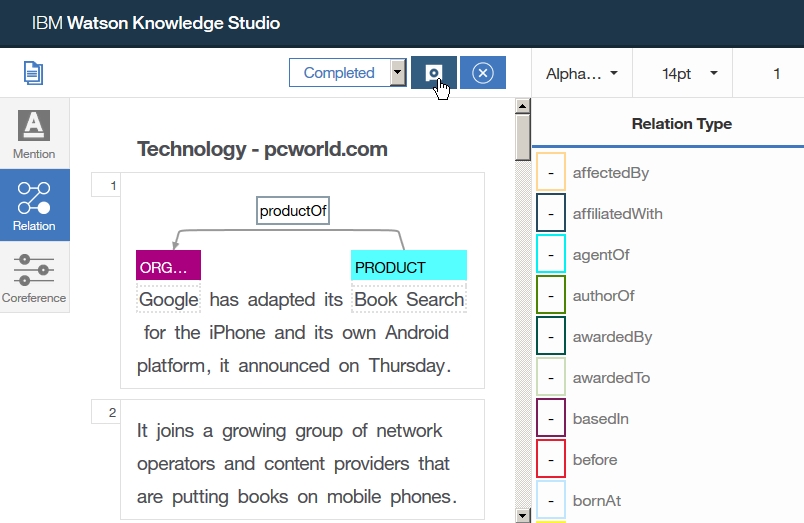
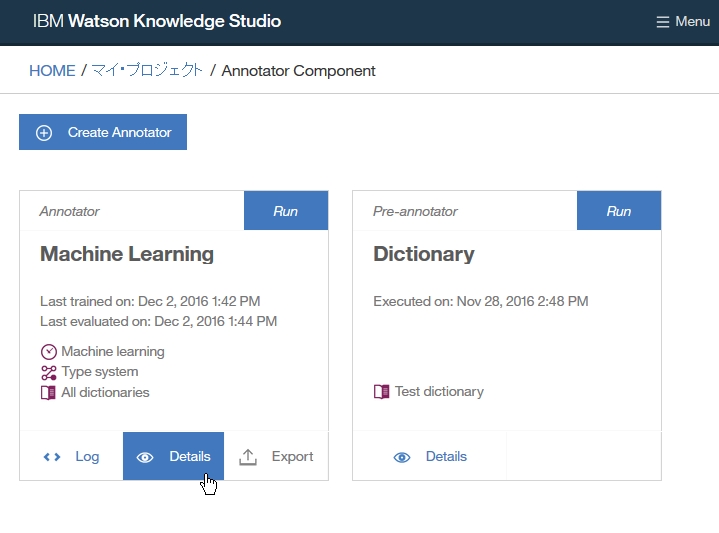
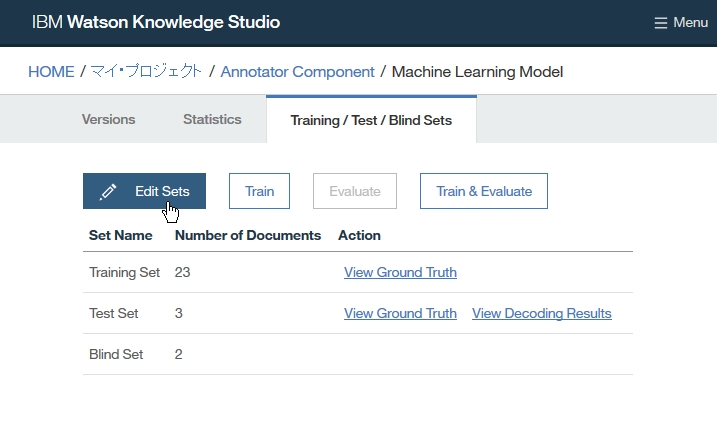
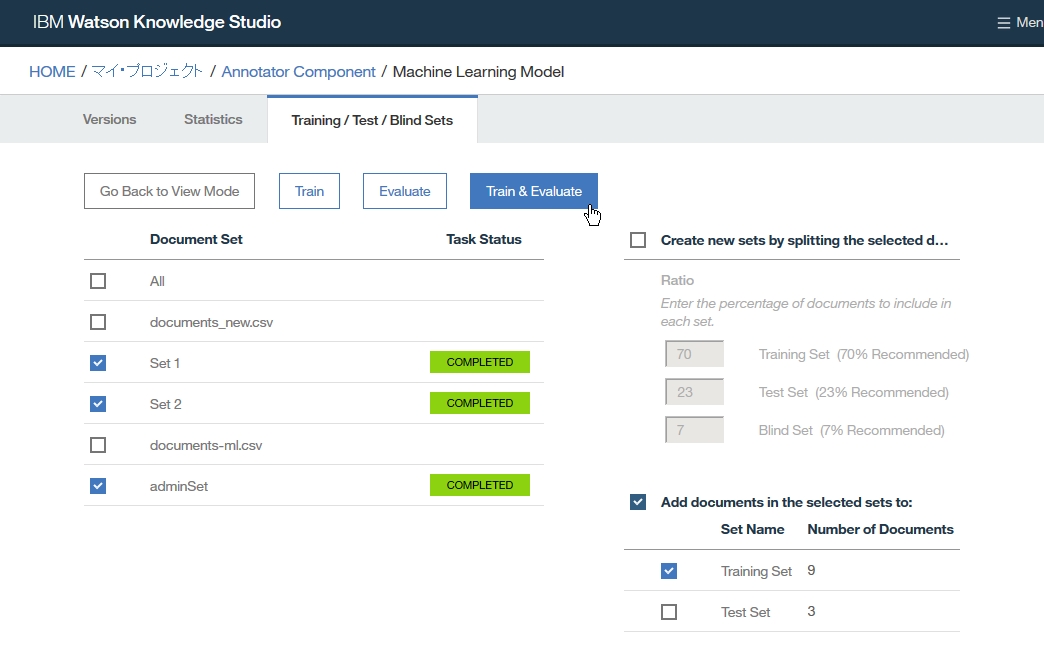
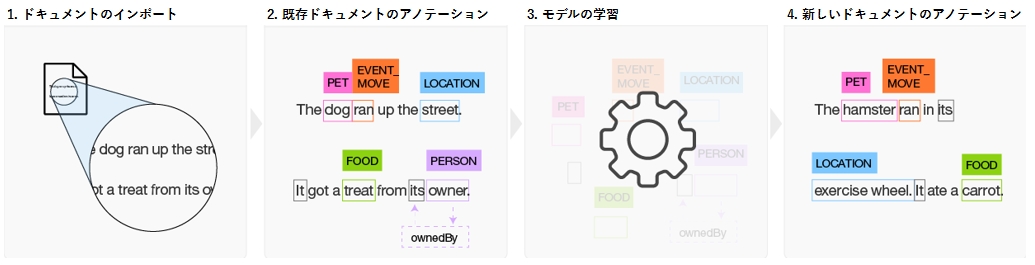
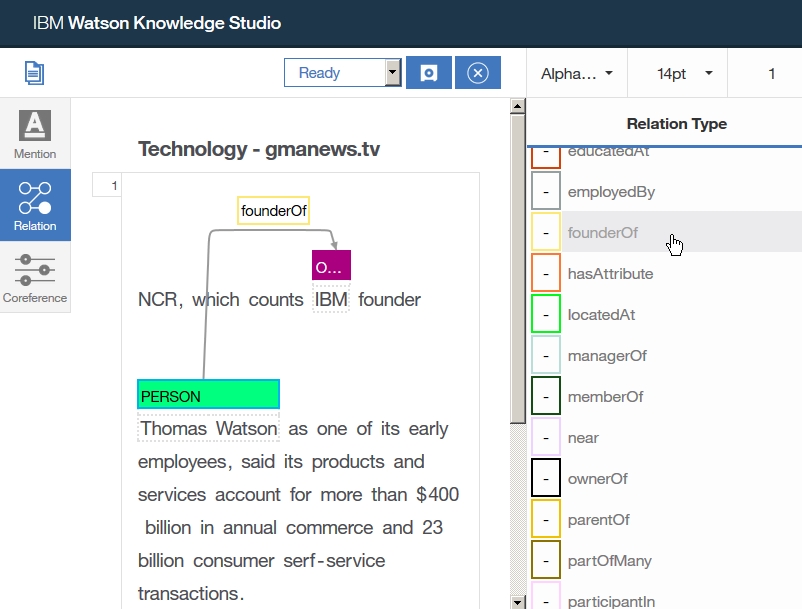
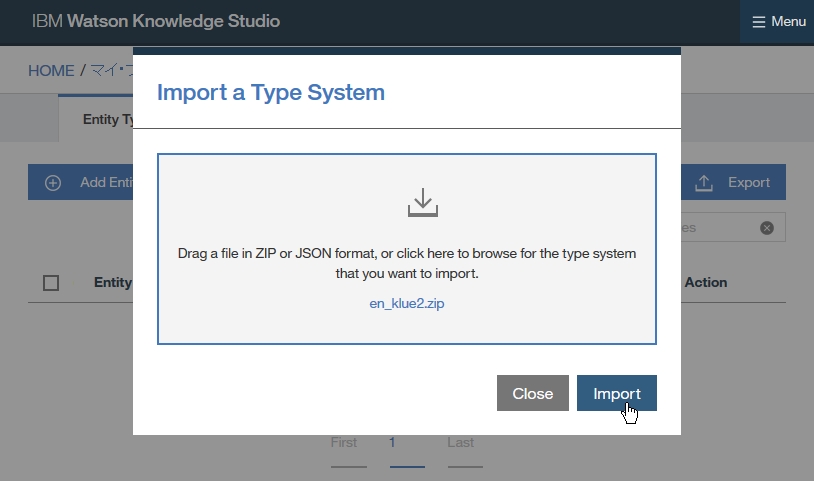
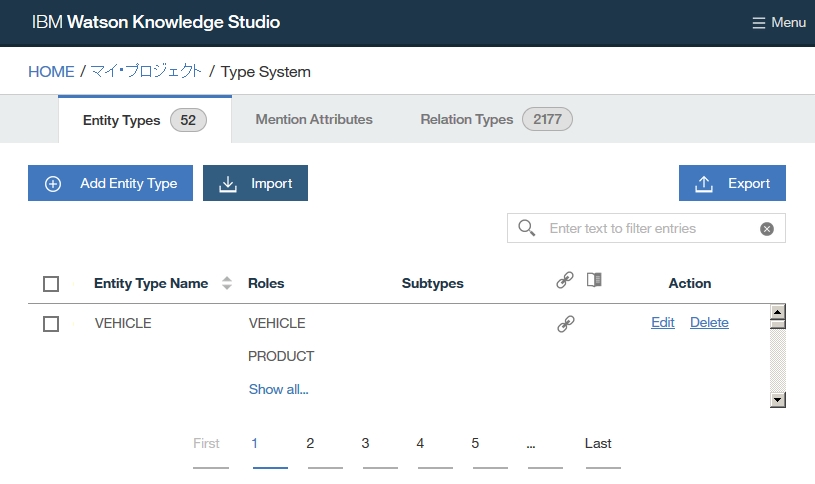
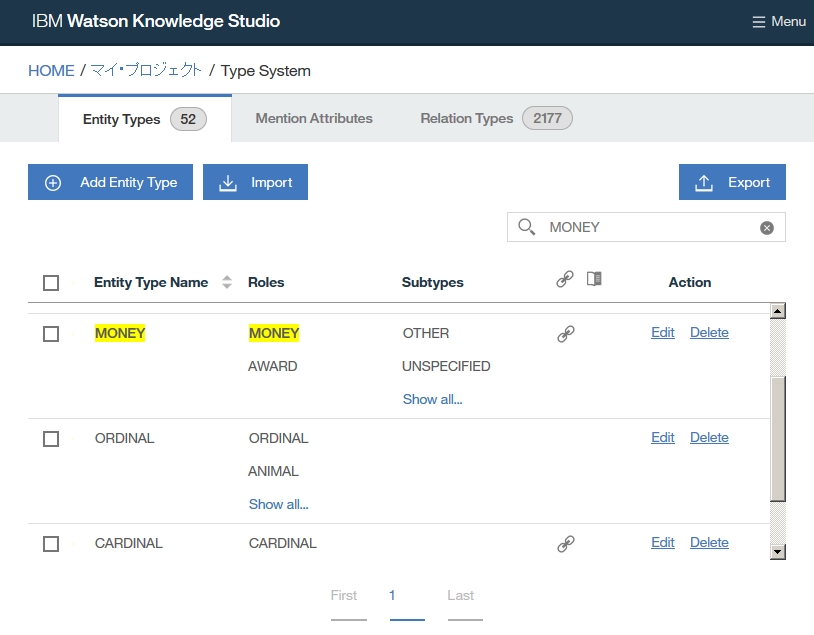
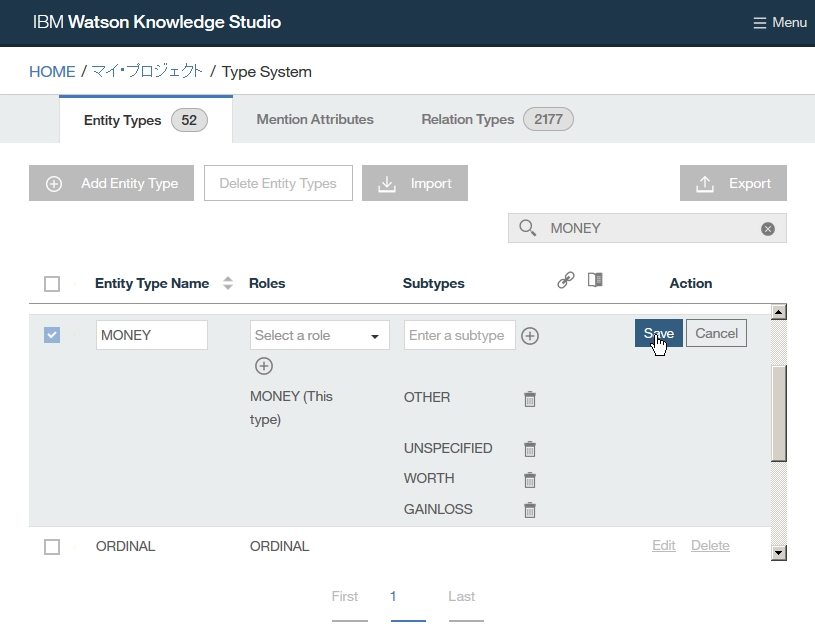
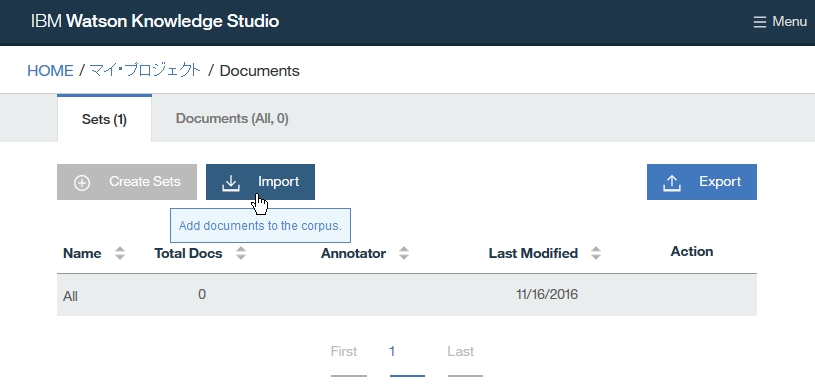
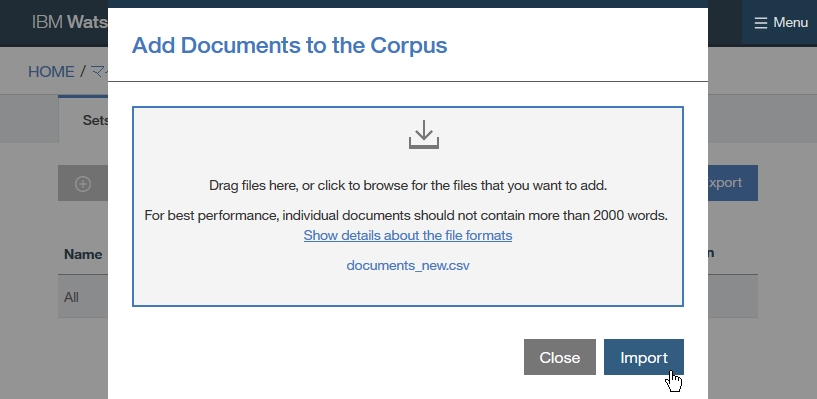
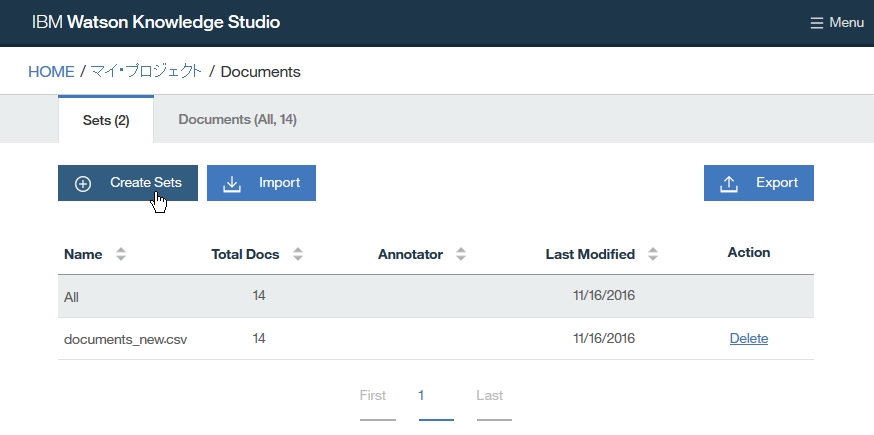
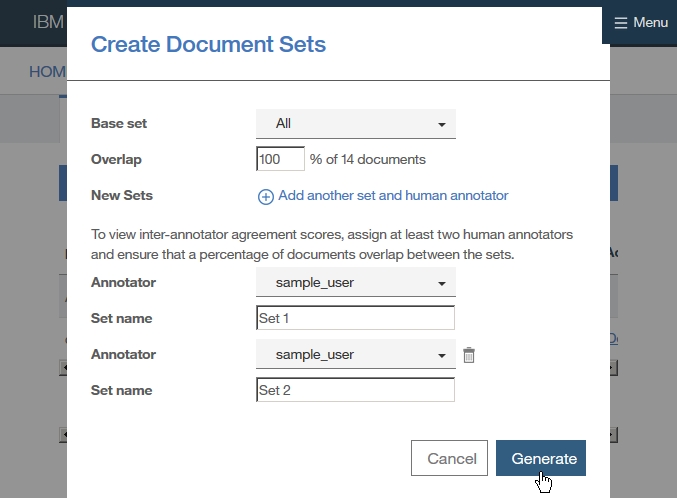
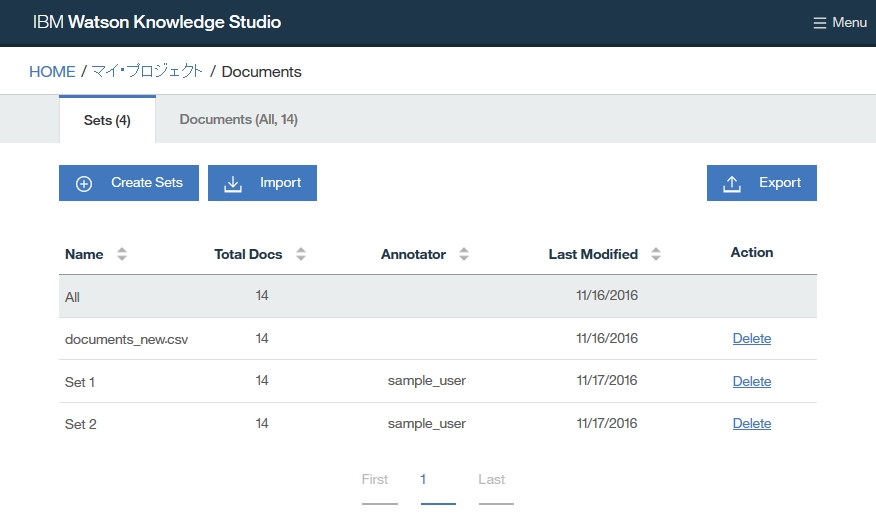
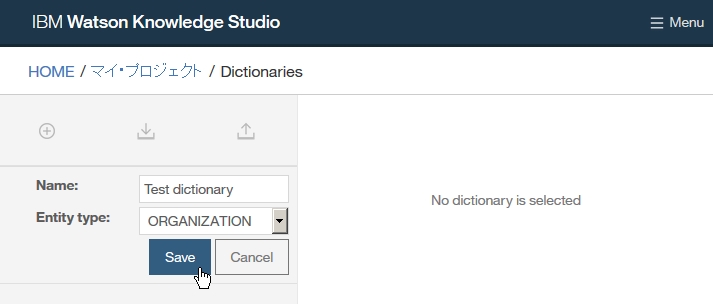
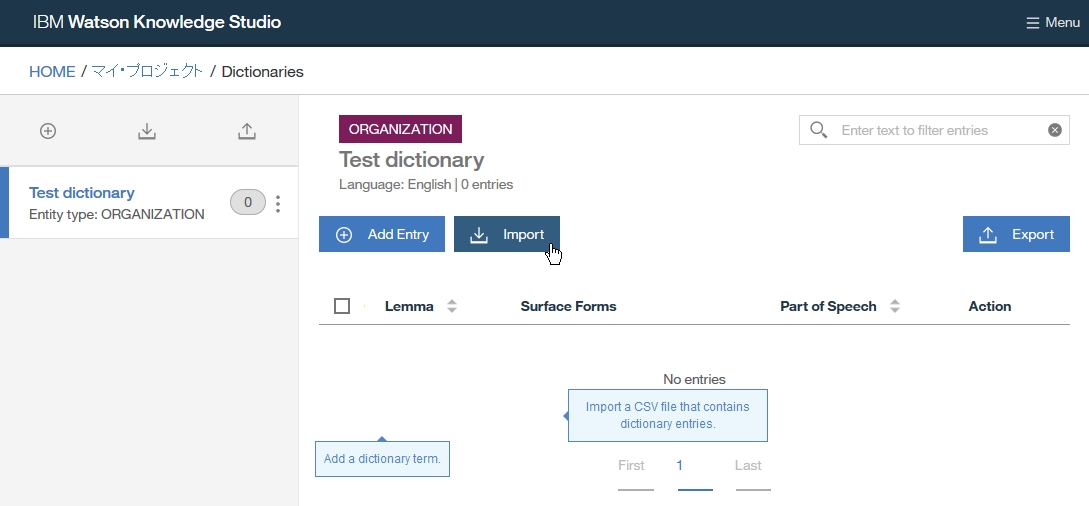
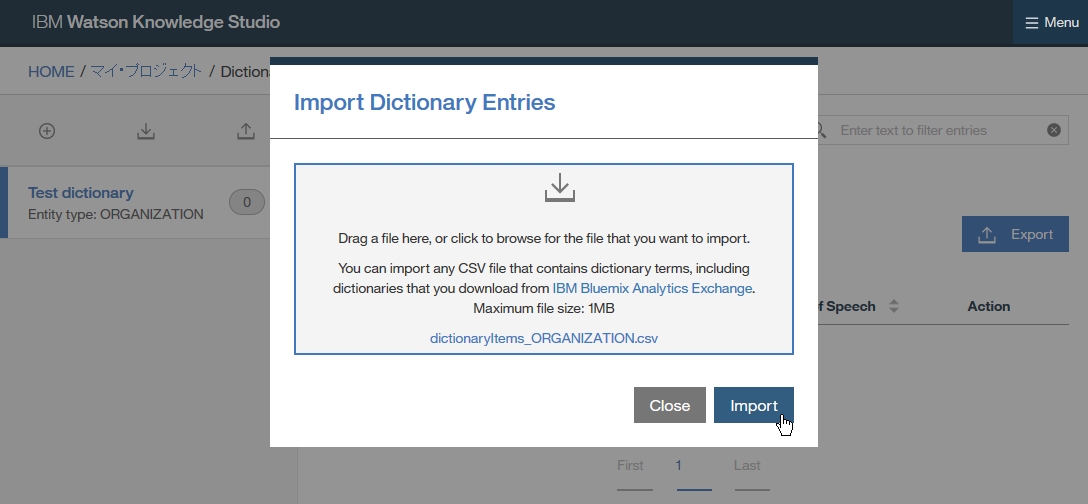
Dictionary Add
-find root -> Resource -> Dictionaries
-click right on Dictionaries folder
-select New -> Dictionary Database
-insert Dictionary name
-select language
-click Finish
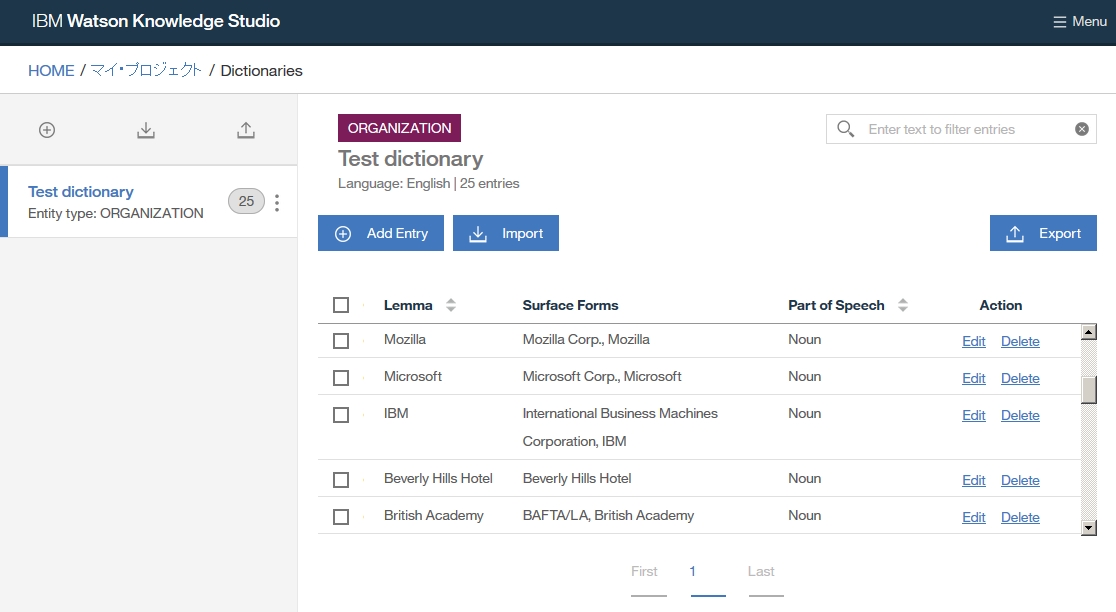
-find out dictionary name which you made
-select the dictionary
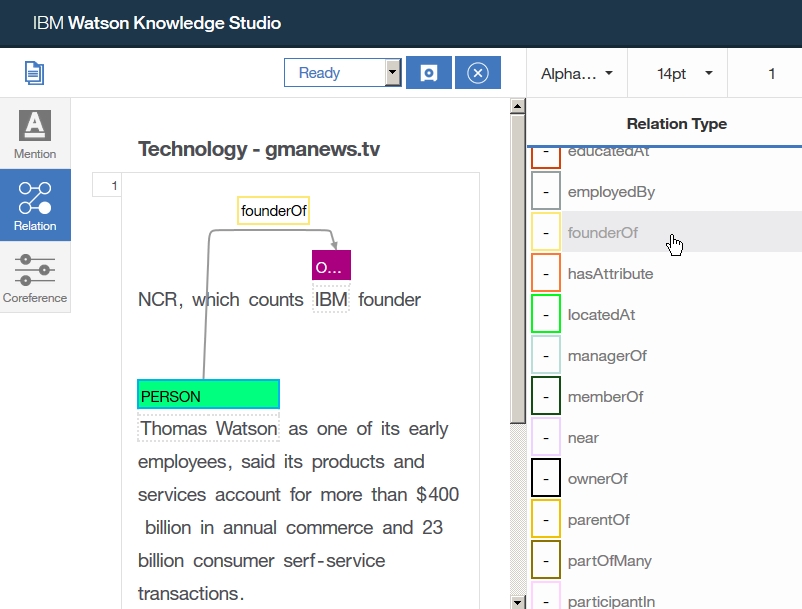
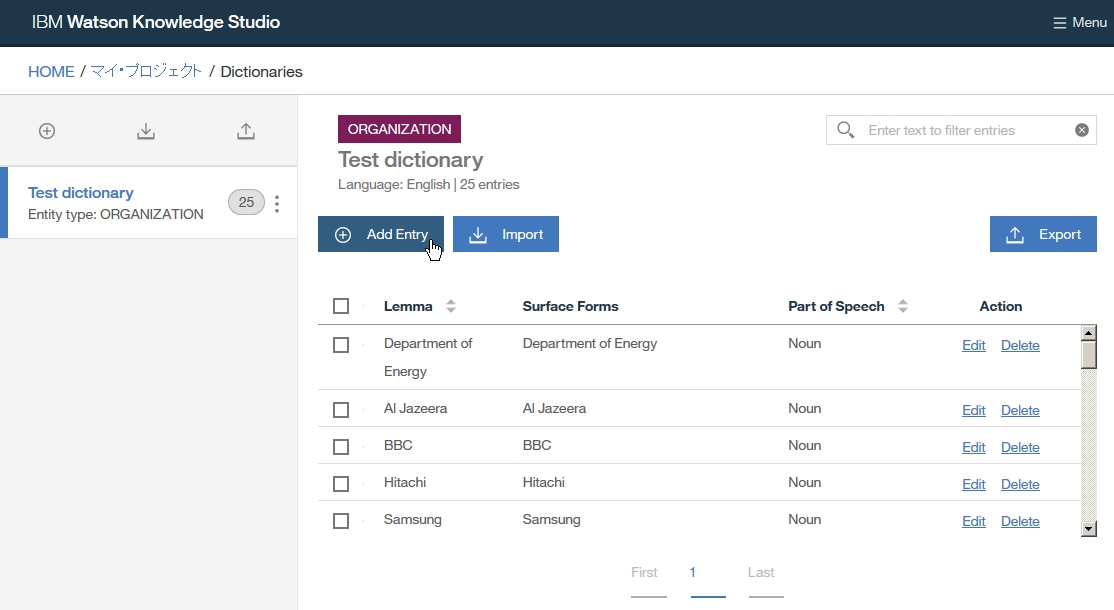
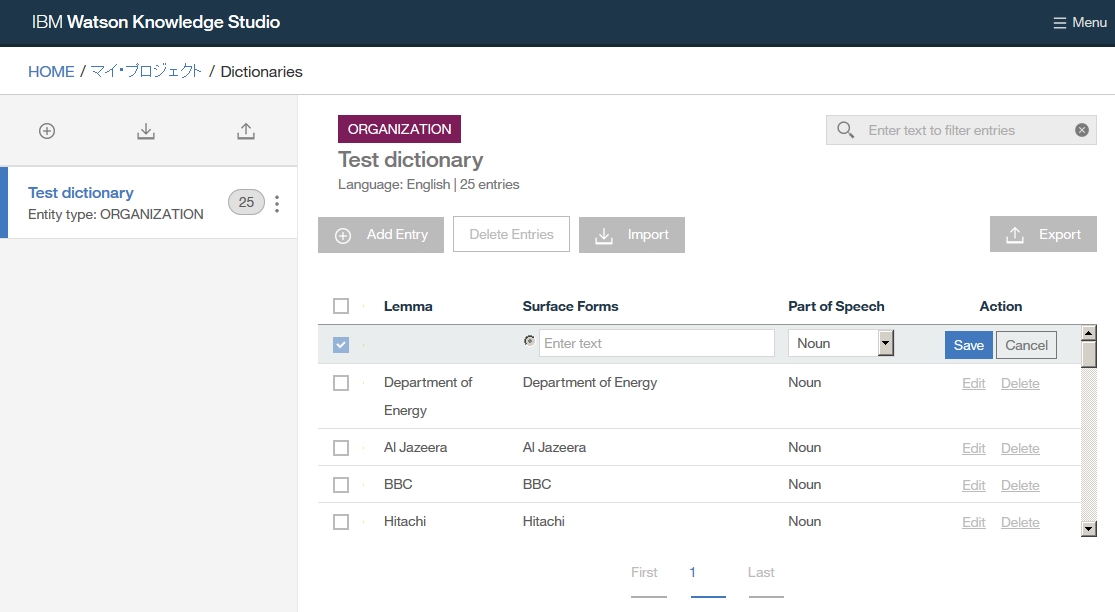
-right click at dictionary table and choose Add entry to dictionary [dicName]
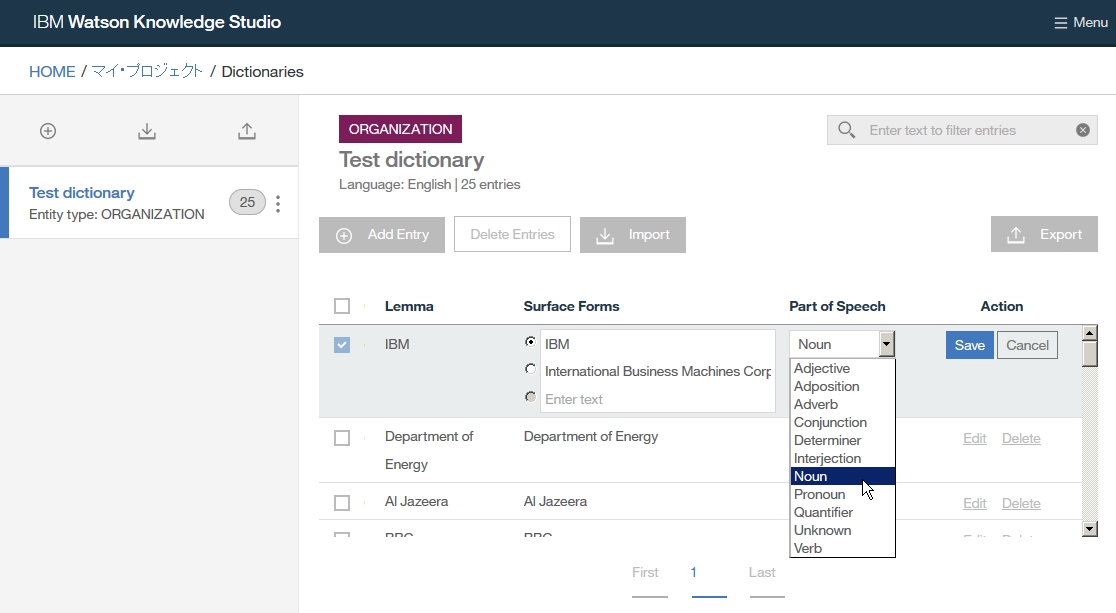
-insert a word you want to add as dictionary
-if you want to add word as synonym, click Add surface form
Server Config
-find root -> Configuration -> Servers
-right click on Servers folder
-select New -> Contents Analystic Server Connection
-insert Host Name, User Id, Password, Port, Admin Port, Collection.
User Id, Password, Port, Admin Port has already been setup, when you install wex in server
Annotator refresh
:All analysis is executed by Annotator config folder.
Eventhough building new dictionary or rule, the new built setup which won't be reflected at annotation config is not a target of analysis.
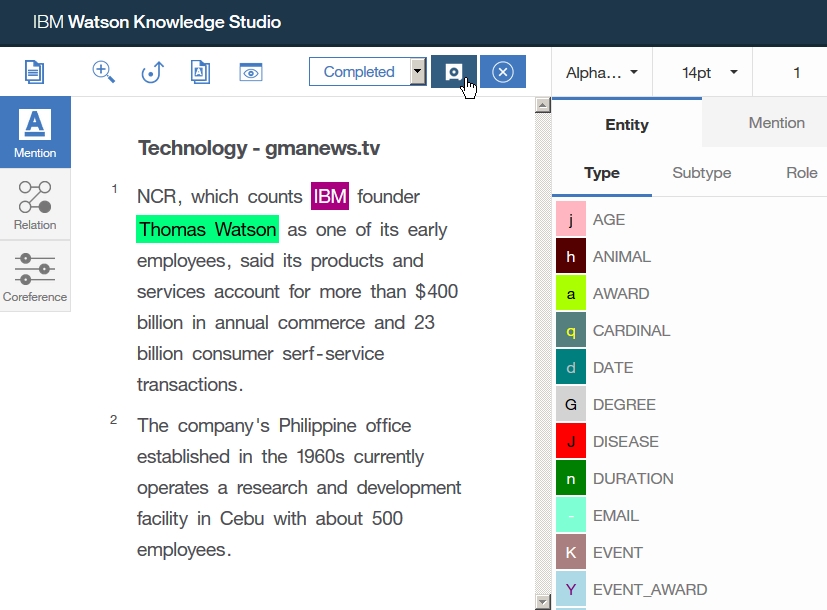
-find root -> Configuration -> Annotators
-click right on Dictionaries folder
-select New -> UIMA Pipeline Configuration
-set up Lexical Analysis(dictionary model), parsing Rules(rule base model)
-click Select button at Lexical Analysis index.
-Add new dictionary.
-click Rebuild buttion.
Annotator export & Facet Add
-find root -> Configuration -> Annotators
-right click on .annoconfig file
-select Content Analytics Studio -> UIMA pipeline to Content Analystic Server
-select target annotation config
-select target server config
-select collection(collection is easily seemed as table of DB)
-click Add button
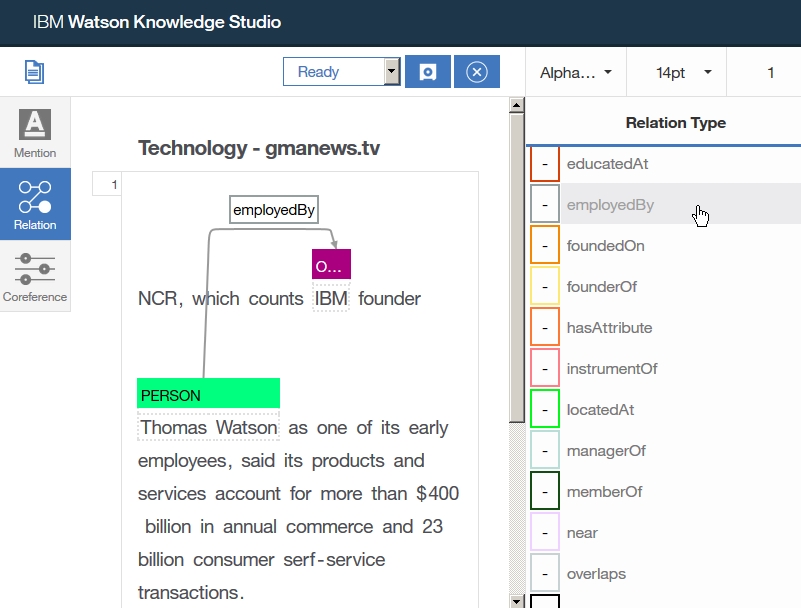
-select UIMA type
-Add Index Filed or Facet*(covered Text, literal value... )
-Add Facet Tree Path
-check button Field Search
-check buttion Upload PEAR file to the Content Analystic Server (*what sis PEAR file)
1 2 3 4 5 6 7 8 9 | { "path": [ "component", "danger" ], "keyword": "バッテリー", "begin": 1, "end": 6 } | cs |
1 2 3 4 5 6 7 8 | { "path": [ "Section" ], "keyword": "危険物情報", "begin": 1, "end": 6 } | cs |
1 2 3 4 5 6 7 8 | { "path": [ "Section" ], "keyword": "輸出入制限品", "begin": 1, "end": 6 } | cs |
covered Text : 인지한 단어 그대로
literal value : 지정한 스트링으로 keyword지정
lemma:key : 搭乗口:搭乗ゲート、ゲート의 경우 搭乗口의 동의어로 搭乗ゲート、ゲート가 포함되어 있음. 이때 lemma는 搭乗口. keyword를 lemma:key로 설정할 경우 ゲート를 찾아도 搭乗口를 키워돌 지정함


'C Lang > New IT Program Diary' 카테고리의 다른 글
| 자연언어 머신러닝 관련 용어 (0) | 2018.07.31 |
|---|---|
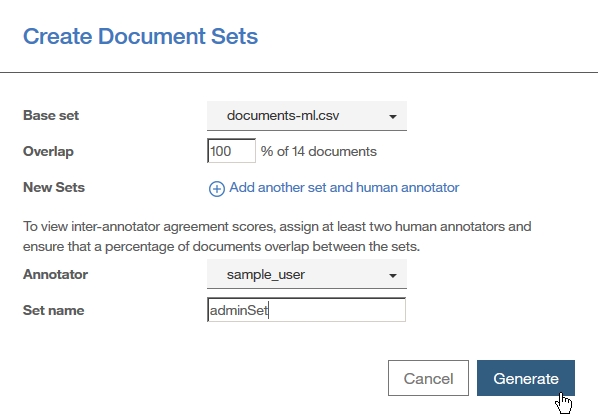
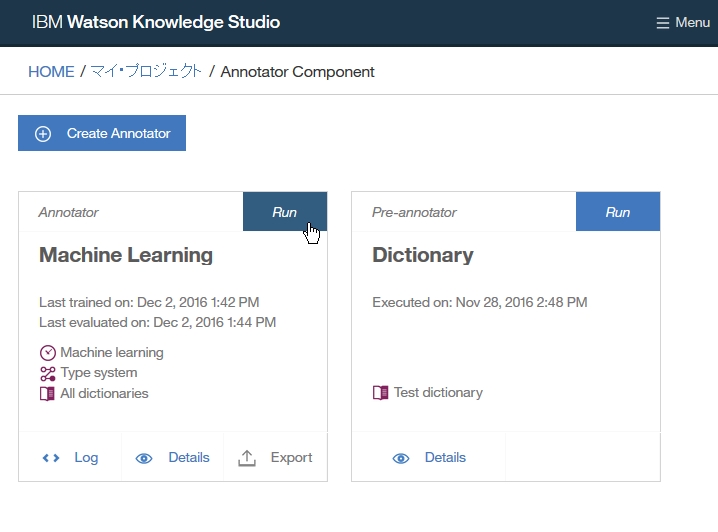
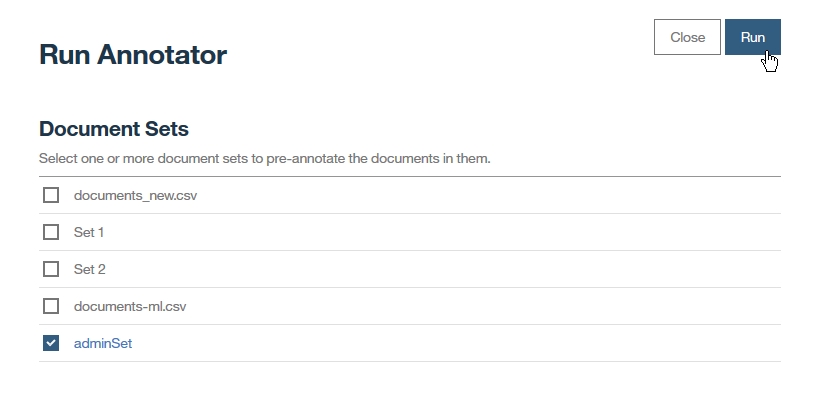
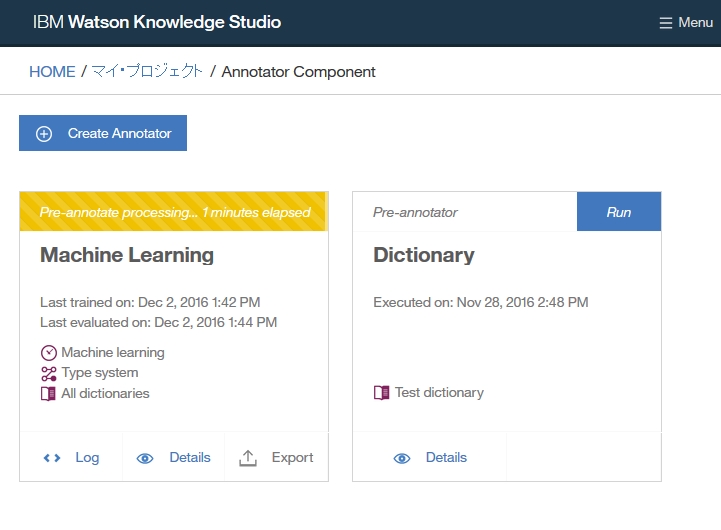
| Watson Knowledge StudioのTutorialをやってみた(딕셔너리베이스 pre-annotation, human annotator를 위한 annotation task작성, annotator간 합의도출, 기계학습annotator작성) (0) | 2018.07.31 |
| Watson Knowledge StudioのTutorialをやってみた(annotation, type system, entity type, relation type, 도큐먼트 추가, 도큐먼트작성, 딕셔너리추가) (0) | 2018.07.31 |
| dialogflow program diary (0) | 2018.07.10 |
| Watson program diary (0) | 2018.05.10 |