커니에 입사해서 가장 신선한 충격이었던 건 2시간 짜리 미팅을 두 세마디로 요약해서 커뮤니케이션하는 모습이었다. 2시간 미팅 동안 당최 핵심이 무엇인지 감도 못잡고 있었던 나에게는 큰 충격이었다. 현재 일한지 한 달이 되는 시점에서 스스로를 피드백해보면, 2시간 짜리 미팅을 단 몇 마디로 요약하기 위해서는 크게 2가지의 능력이 필요하다.
구조화: 미팅의 가장 큰 토픽 -> 이하 레벨로 구조화 하여 전체 이야기가 어떻게 구성되었는지 이해
요약: 각 하위 레벨 別 가장 하고 싶은 말 그래서 결국 가장 포인트가 되는 말이 무엇인지 이해
본 포스트에서 주로 다룰 내용 요약은 단순히 인터뷰 내용을 요약하는 것 뿐만아니라 긴 대화에서 결국 가장 중요한 포인트가 무엇인지 잡아낼 수 있는 능력을 방법화 하기 위한 글이다.
내용 요약의 목적: 장표작성에도 가장 중요한 인풋으로 활용
내용요약은 인터뷰 요약, 회의록 요약, 리서치 요약 등 다양하게 사용된다.
서머리는 인터뷰 회의의 요약기능뿐만 아니라 장표작성에서도 큰 스토리르 잡고 디테일 정보에 대한 핵심 인풋이 되기 때문에, 어쩌면 가장 중요도가 높은 컨설턴트의 업무 중 하나라고 할 수 있겠다.
내용요약의 핵심!! 요약의 핵심은 결국 읽는이가 보기 쉽고 쉽게 이해할 수 있는 지이다. 회의를 들어오지 않은 사람이 봤을 때도, 술술 익힐 정도로 요점이 잘 드러나고, 놓치는 디테일이 없는지로 검증할 수 있다.
내용 요약 프로세스
1. 가장 높은 레벨의 구조화부터 "적당한" 레벨까지 구조화 실시
여기서 포인트는 매우 세부적인 부분 까지는 구조화 레벨을 내리지 않고, 읽는이가 이해하기 용이한 선 정도까지만 구조화를 하는 것이 중요하다. 왜냐하면 서머리 이기 때문에, 목차와 같은 기계적인 구조화가 아닌 그래서 가장 하고싶은 말이 무엇인지 의 기준으로 적어주는게 읽는이 입장에서 이해하기 편하기 때문이다.
구조화 하여 전체 내용을 이해하고자 하는 목적이므로 이 단계 까지는 단어로 구조화를 해도 문제 없다.
먼저 전체 내용을 단어 레벨로 구조화 시킨다.
[참고]1에서 구조화된 각 파트에서, 각 파트에 해당하는 가장 핵심인 내용, 머리 속에 기억남는 말을 가장 상위 레벨의 라벨링으로 사용
구조화된 단어로 기재하는 것이 아니라 문장으로 적는 이유: 단어로 구조화 하고 그 아래 문장으로 부가 설명을 하는 것도 하나의 방법이지만, 직접 write해 보면 이러한 방법이 가독성이 훨씬 낮다는 것을 경험할 수 있다. 애초에 문장으로 언급해주는 것이 서머리의 측면에서는 더 효율적이다.
가능한 한 수치등 디테일한 언급하지 않고, state로만 언급 후 아래 레벨에서 디테일한 데이터 언급
서머리 이기 때문에, 목차와 같은 기계적인 구조화가 아닌 "그래서 가장 하고싶은 말이 무엇인지" 의 기준으로 적어주는게 읽는이 입장에서 이해하기 편함
단어로 구조화된 스켈레톤에 추가적인 살을 붙여서 서머리를 완성한 모습
2. 회의록 등 INPUT DATA 보며 관련 구조화된 각 파트에 해당하는 데이터 추가
회의록을 보면서 서머리에 반영된 내용에 회색 밑줄을 그어가면 작업하는 방식은 정보를 놓치지 않는 효과적인 방법이다.
인터뷰 내용에서 디테일 내용들이 충분히 반영되었는지 회색 밑줄을 그어가면 작업하는 모습
3. 원인, 결과, 구체화 작업을 통해 살 붙여나가기
서머리 이기 때문에 완벽하게 모든 정보가 인터뷰에서 나올필요는 없음. 경우에 따라서 원인 결과 디테일 데이터를 추가해서 언급해도 관계없음. 가령, "미츠비시 상사는 에네코를 인수했다"라는 내용이 인터뷰에 나왔다면, 미츠비시 상사의 에네코 인수건을 리서치해서 보충적으로 적어 넣는다.
빨간 색으로 표시된 부분은 인터뷰 때 키워드를 획득하고 이후 추가 리서치를 수행하여 add-on한 정보
[참고] 그외 서머리 팁
프로젝트에 대한 인터뷰 후 서머리를 해야하는 작업에서는 프로젝트가 생성된 배경비즈니스 모델(어떤 플레이어가 등장해서 뭘주고 뭘받는지)프로젝트의 목적 및 의도 을 중심으로 파악하는 것이 좋다.
팩트와 주장을 구분하여 적고, 신빙성이 낮은 주장에 대해서는[추가리서치 필요]라고 표시하고, 이후 추가 리서치 실시
괄호, 구분기호, 한자어, 영단어를 적절히 활용히 가독성 높이기
괄호를 사용하여 가독성 높이기: [EX테스크포스팀] 그룹 內 최상위 EX의사결정 조직으로 전사적 EX방향성 및 초기 전략 제시
as-was, as-is, to-be라는 표현 사용: (As-was) 기존의 11.14% (2020년)에서 1% (2025년)까지 절감하는 목표 수립
구분기호를 사용하여 가독성 높이기: 일본 국내 수소 수요 ‘30년 6-7백만톤 ➡ ’50년 4천만톤으로 성장할 전망
한자어를 사용하여 가독성 높이기: 사장 傘下 조직으로 각 영업부문別 상무이사로 멤버 구성
조사의 사용 지양하기: 대만 정부는 원자력 발전의 비중을 높이기로 함 -> 대만 정부의 원자력 발전 비중 확대 결정
불필요한 단어의 사용 지양하기: 각 단어가 진짜 필요로 한지 따져봐야함
상위 레벨에서는 구체적인 정보를 되도록 언급하지 않고 ROUFH 하게 포함하여 독자가 궁금증을 갖고 읽을 수 있는 단어를 선택. 구체적인 표현은 하위 레벨에 맡겨두기
하위 레벨의 내용: 재생에너지로 2조원을 확보했다, IT기업들도 직접투자를 하려고 한다.
상위 레벨의 표현: "직접투자를 위한 재원을 별도로 마련하고 있으며 소니 外 타사들도 직접투자에 높은 관심"
상위 레벨에서는 일부러 2조원에 대한 언급은 안하고 별도 재원 마련이라고 표현하였으며, IT기업이란 언급안하고 타사로 언급
모델링의 목적은 여러가지가 있겠지만, 일반적인 모델링의 목적은 미래에 대한 추정이다. 미래를 추정하는 방법은 여러가지가 존재한다. 전략 컨설팅에서는 전문가 의견 종합을 통해 추정하고, 통계청 및 경제 기관에서는 판매사원 의견 종합을 통해 선행지수를 예측한다. 또한, 고객과 맞닿고 있는 리테일에서는 고객에게 설문지를 돌리는 고객조사기법을 사용하기도하고, 데이터가 충분히 존재하는 곳에서는 회귀분석을 통한 기법도 활용한다.
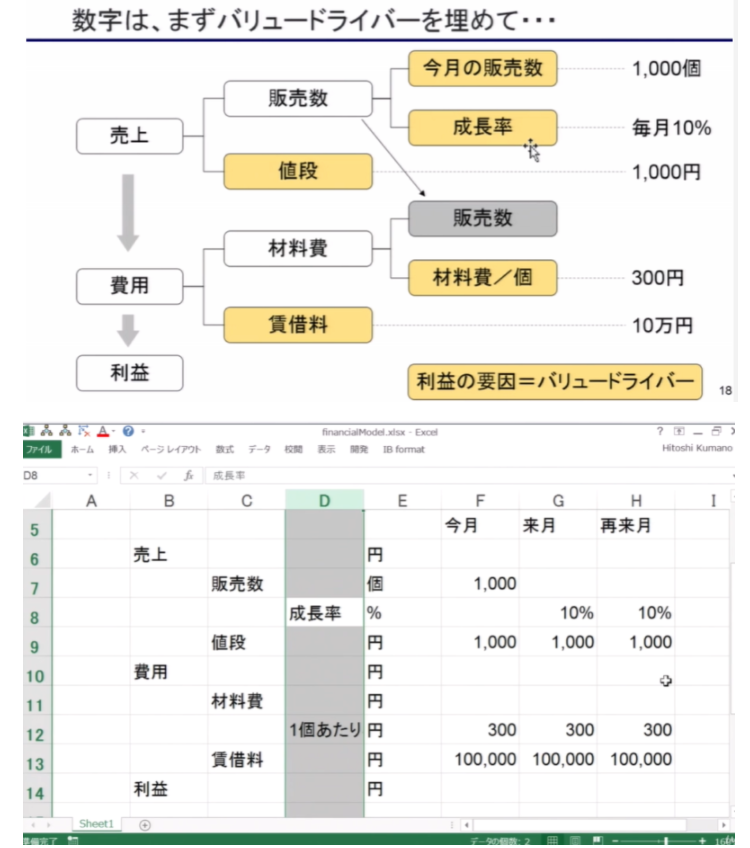
목적값에 따른 Driver 선정 실시(모델링 설계)
모델링 목적에 따라 타당하게 변수를 구성하였나: TOP-DOWN에 의해 설계된 모델링 로직이 맞는지 파악
동일한 목적치를 구하더라도 여러개의 가능한 모델링 시나리오 존재 -> 프로젝트 목적에 가장 부합하는 시나리오 모델링 선정
탑다운 방식 모델링이 타당할지, 바텀업 방식 모델링이 타당할지
수요 측을 통한 Q 로직이 타당할지, 공급 측을 통한 Q 로직이 타당할지
각 모델링을 통해 파악한 Value-Driver의 취득은 용이한지
가장 High Level의 로직 고려 시, 단위를 맞추는 과정이 매우 중요하다. 예를 들어, SOEC 수전해 발전소 시장 규모를 모델링 한다고 할 때, SOEC 수전해 발전소 1기당 가격 * 향후 지어질 수전해 발전소 기수 로 모델링 하면 매우 멍청한 모델링이 된다. 왜냐하면 수전해 발전소 사이즈는 모두 제각각 일텐데 1기당 가격을 어떻게 균일하다고 가정할 것이며, 크기가 제각각이 기수를 단지 한 울타리에 있다고 1기로 인정할 수 있는지에 대한 의문이 들기 때문이다. 때문에 위와 같은 모델링에서는 SOEC 수전해 발전소 kw당 가격 * 향후 지어질 수전해 발전소 총 용량으로 단위를 맞추어 로직 설계해야한다.
고객이 납득할 로직인가?
모델링의 두가지 방법: 탑다운, 바텀업
실제프로젝트에서 탑다운과 바텀업의 구분 중요성을 깨닳은 사례를 통해 각 프로젝트에서 더 맞는 방법의 모델링을 찾아보도록 하자. 이전 프로젝트에서 산업별(철강, 석유화학, 시멘트 등) 자가발전 중 수소 발전 용량 구하는 모델링을 실시한 경험이 있다.
탑다운 모델링의 경우
수소 발전 용량 = 산업별 전체발전용량 * 자가발전비율 * 무탄소발전비율 * 수소발전비율
위와 같은 식은 모집합에서 내려오는 모든 비율들을 구해야하기 때문에 무수히 많은 가정과 가설이 들어간다. 또한, 수소발전량이 직접적으로 구해지지 않아 직관적이지 않다.
바텀업 모델링의 경우
모집합에서 타겟을 쪼개 들어오는 탑다운 방식이 아니라, 바텀에 있는 값을 직접적으로 구해버리는 방법이다. 바텀업 모델링을 위해서는 왜 시장 Player 가 수소 발전을 하려고 하는지? 에 대한 동인(動因)을 고려하는 것이 핵심이다.
플레이어는 왜 수소 자가발전을 하려고 할까? 왜냐하면 탄소 발생량을 낮춰야 하기 때문이다. 그렇다면 수소 자가발전을 통해 얼마만큼의 탄소 발생을 절약해야하는 것일까? 이는 아래와 같은 바텀업 모델링으로 생각될 수 있다.
전체 탄소발생량 * (1-국가 허가한 탄소발생비율) * 탄소 절감에 필요한 재생에너지 발전량 * 수소발전비율
그외 탑다운과 바텀업 모델링의 예
예1: 치약시장
탑다운: 전체 미용 시장 * 치약시장
바텀업: 전체인구 * 양치 가능한 인구비율 * 하루 양치 횟수 * 회당 치약 사용량
예2: 뷰티 디바이스 시장
탑다운: 20대 이상 여성인구 * 뷰티 디바이스 사용률
20대 이상 여성인구 * f(소득, 잉여시간, 나이 등..)
바텀업: 리프팅목적 뷰티디바이스 이용인구 + 여드름 흉터 제거 목적 뷰티 디바이스 사용 인구 + ...
20대 이상 여성인구 * 주름발생률 * 리프팅디바이스사용률 + 20대 이상 여성인구 * 여드름 발병률 * 흉터남길 확률 * 흉터제거디바이스사용률...
-> 단, 바텀업으로 구성 시 사용 목적이 겹치거나 명확하지 않아 탑다운 방식으로 모델링 하는게 더 나을 수 있음
어느 정도 Sub-level 까지 변수 구조화할 것인가에 대한 고민
어떤 드라이버는 그냥 상수를 가져 올 수도 있고, 어떤 드라이버는 더 깊이 들어가서 sub-sub-driver 까지 고민 필요
생수 시장규모 = 전체인구 * 일주일 內 수 구매 인구 비율 * 생수 사먹는 횟수 * 1회당 구매하는 생수 mL
일주일 內 생수 구매 인구 비율은 전문가한테 물어보고 가져올 것인가? 아니면 해당 Driver를 구성하는 sub-driver까지 더 깊게 팔 것인가?
생수 구매 비율 = f(정수기 보유 비율, 외출시간, etc)
Driver로 설정한 값들을 어떻게 구할 것인가에 대한 고민
드라이버를 구조화한 후에는 정말 추정할 수 있는 값들인지에 대한 판단을 미리하는게 중요. 아무리 좋은 모델링이라 하더라도 현실적으로 구할 수가 없다면 모델 수정이 필요하기 때문.
해당 Driver가 정말 Top-Value와 상관관계가 있는지 파악
데이터를 통한 상관관계 분석법으로 하위의 subdriver가 top-value와 관계성이 있는지 파악하는 작업.
[참고1] 논문을 통해 해당 시장에게 영향을 미치는 변수 취득
B2C 시장은 어떤 변수로 시장 사이즈가 변화하는지 명확하지 않다. 이에 각 종 논문에서 진행한 설문 및 통계 자료를 통해 주요 변수를 파악하고 모델링에 적용할 수 있다.
최근에 뷰티 디바이스 시장 규모를 추정했는데, 두세편의 논문을 통해 나이, 소득, 직업군이 유효한 영향을 미치는 변수라는 것을 확인했다. 이처럼 논문을 통해, 타겟 시장의 선택률에 영향을 미치는 요인들을 파악할 수 있다.
[참고2] B2C 시장 모델리의 경우 "시나리오" 따른 시장 규모 추정 필요
고급 고양이 식판 구매 비율을 추정한다고 할 때, 고양이 양육 인구 중 상위 20%만 구매할 경우, 상위 30%만 구매할 경우, 상위 40%만 구매할 경우로 케이스를 나누어 계산가능. 이때 각 숫자의 근거가 필요한데, 동일한 프리미엄 시장의 다른 제품을 통해 추정할 수 있다. 예를 들어, 고양이 프리미엄 사료는 전체 고양이 인구 중 10%만 먹인다고 하면, 고급 고양이 식판도 10%만 구매한다고 추론할 수 있을 것이다.
고양이 사료 시장 내 kg당 평균 가격이 2,000원이고 프리미엄 사료는 kg 당 4,000원 인데, 프리미엄 사료 시장의 일반 사료 시장의 10%를 점하고 있다면, 가격/kg 변수와 점유율 변수를 통해 2차함수를 구하고 이로써 프리미엄 시장이 갖는 기울기를 구해낼 수 있을 것이다. 이 기울기를 활용하여 고양이 식판 구매 비율을 추정하면, 훌륭한 모델링이 될 수 있다.
+ 여기에 고양이 식판 시장과 사료 시장의 차이를 만들어내는 변수를 파악해 변화량을 주면 가장 Best일 것.
정성데이터를 어떻게 정량화 시킬까에 대한 고민
Scoring 기법 (가중치 기법)
예를 들어, A국의 한해 수소 생산량이 100만톤일 때, 한국으로 수출가능한 물량은?
전체 수소 생산량 중 한국 向 수출률을 표현해야할 때, 고객한테 "그냥 한 20% 나올것 같은데요?" 라고 말할 수는 없음. 따라서 20%라고 주장할 수 있는 근거가 필요
수소 생산하고 있는 프로젝트의 지분율 중 한국 기업의 차지하는 비중, 한국과의 물리적 거리(수소는 배로 운반하기 때문에 거리가 멀면 자연 소실 되므로), 판매자의 사업 목적 등의 지표에 Scoring
판매자의 사업 목적 같은 정성 데이터는 "판매의지 높음(100점), 판매의지 중간(50점), 판매의지 낮음(0점)"처럼 Scroing하여 정량적 수치로 변환
표준분포 기법
수소 생태계가 얼마나 잘 갖추어져 있는가를 판단하는 정성지표를 정량화 시킨다고 했을때, 각 국 보유 수소 프로젝트수에 따라 표준분포를 그리면 상위 %에 따라 Scoring 가능
Linear 및 Logistic 함수 활용한 예측 모델
데이터가 충분할 시, 기존 데이터를 통한 선형 기법을 통해 독립변수의 종속변수 값을 구할 수 있음
바이너리 기법
Pass or Fail 기법으로 떨어뜨리거나 붙여주거나..
워터풀
년도별 발생하는 사건이 언제까지 시작해서 언제 끝날 것인가를 나타낼 때 유용한 방법. 대표적인 예로 감가상각이 있다. '22년 CF가 100만원 발생하여 10년 동안 상각한다고 했을 때, '22년부터 '31년까지 10만원의 CAPEX가 나간다고 인식할 수 있을 것이며 '23년에도, '24년에도 증설로 인한 CF가 100만원씩 나가는 상황이라면 이를 표현하는 대표적 방법이 워터풀.
더 정확한 모델링을 위해 데이터를 가공하는 법에 대한 고민
Log함수
Log함수는 2가지 측면에서 Linear 보다 유용하다. 1. 현실 세계의 한계체감을 잘 반영하고 있다. 아무리 자본을 많이 쏟아부어도 어떤 한계점을 지나면 성장률이 더디다. 로그함수는 한계체감을 잘 표현할 수 있다. 2. 데이터가 편차가 커서 유의미한 모델링이 불가할 때 유용하다. 첫번째 테이블인 "여성 직종별 월평균 임금"에서 관리자와 그외 직종별 임금 편차가 매우 크다. 이때 임금을 독립변수로 사용하면 임금이 낮은 서비스종사자나 단순노무종사자 向 모델링이 심하게 왜곡될 가능성이 있다.
이때 활용할 수 있는 방법이 기존 raw데이터를 log처리 하는 것. 아래 테이블은 기존 임금 데이터를 1.01값으로 log 처리 하였다. 이에 따라 관리자 8,396 -> 단순 노무자 1,895의 편차가 관리자 908 -> 단순노무자 758로 변화하여 더 의미 있는 모델링을 할 수 있다.
행렬을 통한 연립 방정식 계산
종속변수 y값을 추론하기 위해 복수개의 독립변수 x를 선정할 수 있다. 이때 3개의 독립변수 x를 갖는 식을 처리한다고 가정하면 독립변수의 역행렬을 통해 a, b, c의 값을 추론할 수 있다.
aX1 + bX2 + cX3 = Y aX4 + bX5 + cX6 = Y aX7 + bX8 + cX9 = Y
X1 X2 X3 (a) = Y X4 X5 X6 (b) = Y X7 X8 X9 (c) = Y
어떤 Driver를 Bull Base Bear 로 설정할 지에 대한 고민
모든 드라이버에 시나리오 넣는게 아니라, Impact Factor에 해당하는 변수들에 시나리오를 제공 해야함
어떤 매게 드라이버들을 더 추가하거나 뺄지에 대한 고민
매게 드라이버란 모델링에 주요 전제가 되는 Proxy 숫자들을 의미한다. 예를 들어, 수소의 에너지 전환율이 70%라고 하면 에너지 전환율이 매게 드라이버가 될 수 있다. 에너지 전환율을 낮추거나 높여서 다른 모델링 결과를 도출할 수 있는데 이러한 Impact Factor을 상수로 고정할지 아니면 변수로 Control 할지 고민해야한다.
Driver의 Top-Bottom 값에 대한 고민
특정 Proxy를 통해 Cap값이 제공된다면 그 수치 아래서 모델링하면 되므로 편리함
가령, 국가에서 예상한 매우 긍정적 시나리오의 향후 원자력 발전 비중이 20%라면 이러한 수치를 차용하여 모델이 20%넘지 않는 선에서 모델링 실시
엑셀 시트 분할
result
input: 주요 벨류 드라이버를 조정하는 시트
const: 변수 기입 시트
senario
calculation: 로직 및 계산이 기입되어 있는 시트로 본 시트의 모든 데이터는 他 시트 참조
reference: caculation시트에서 계산할 하부단의 로직들의 섞여있는 데이터 시트
rawdata: 인구, 금리 데이터, 수도세 데이터 등 로직 없이 Counting 해서 결과물이 이미 나와있는 데이터
모델검증
정규분포, 표정정규분포를 활용하여 원하는 수치가 고루 분포되었는지 확인
모델링 팁
rawdata와 작성데이터는 다른 시트에서 관리 할 것
작성데이터의 참조는 rawdata로 할 것
타시트 참조데이터는 초록색, 동일 시트 함수데이터는 검은색, hardcoding 데이터는 파랑색으로 폰트설정할 것
전체 줄금을 삭제하고 가로줄만으로 표시할 것
데이터는 추세선을 그려가며 진위를 확인해볼 것
한 시트에 여러 테이블을 만들어야 하는 상황에는 엑셀 테이블 만들기기능 이용할 것: 테이블 당 필터링 가능
가정해야하는 변수가 더 적은 모델(less is more)
고객들은 숫자 하나하나 매우 민감하며 사소하다고 판단되는 숫자에도 근거가 존재할 것
모델링은 엑셀로 수행하기에 코딩으로는 쉽게 해결할 수 있는 Technical한 문제를 해결할 수 없는 경우가 많다. 대표적으로 엑셀은 루프기능이 없으며, 값을 변수에 담을 수 없다. 루프와 변수 저장 기능을 모두 셀단위로 처리해야 하는 것이다.
비즈니스 듀딜리젼스는 주로 M&A의 2차 딜에서 세부 실사 시에 시행됩니다. 상대회사가 주장하는 사업계획이 정말 타당한 것인지를 증명하기 위한 것입니다. 비즈니스 듀딜리전스의 결과물은 향후 사업계획에 따른 예상 이익에 따라 대상회사의 가격이 결정의 근거로 사용되기 때문에 딜에서 중요하게 사용되는 결과물입니다.
상대회사가 주장하는 사업계획이 정말 타당한지 증명하기 위해서는, 정말 이 기업이 사업계획서 대로의 매출과 이익을 창출해 낼 수 있는지를 분석합니다. 비즈니스 듀딜리전스에서 조사하고 분석하는 많은 결과물들은 PQC를 통한 재무 시뮬레이션을 하기 위해 정량적 모델링 재료가 되기도하고, 정성적 장표를 만드는데도 활용됩니다.
DD는 KBF 및 KSF 분석과 같은 정성적 분석도 많지만, DD의 가장 큰 목적은 아래와 같습니다.
과거의 PQC 변수는 어떻게 변화해 왔고 왜 그런가?: 과거를 통한 시사점 파악
장래의 PQC 변수는 어떻게 변화해 나갈 것이고 왜 그런가?
정량적 시장 분석 및 경쟁 분석을 수행하겠지만, 그 전에 왜 시장분석 및 경쟁 분석을 하는 것인지, 그 상위에 있는 사고는 어떠한 것인지 알면서 실사하자구요!
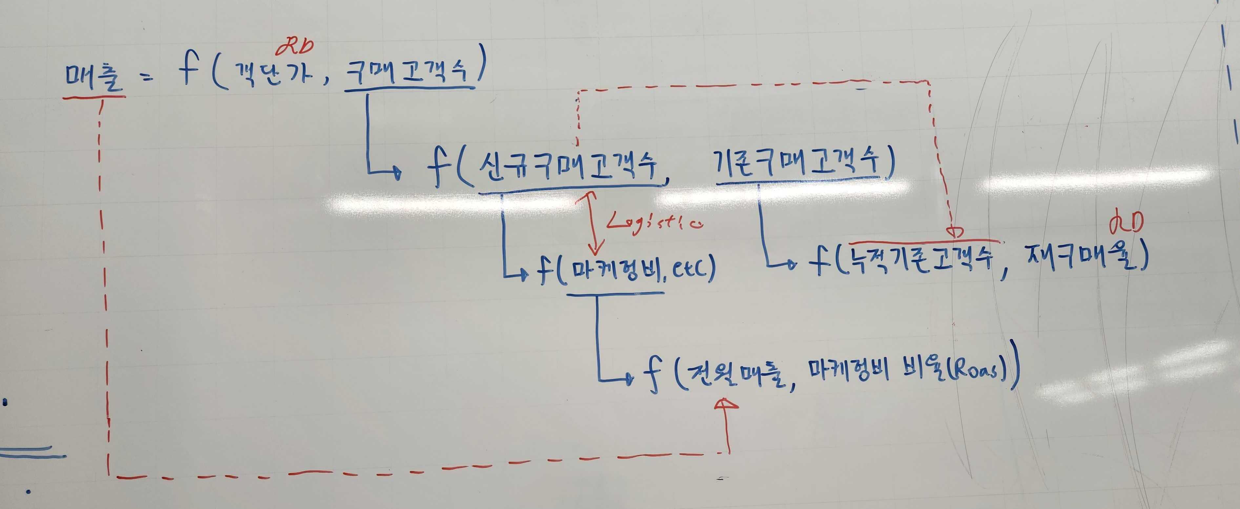
올리브영을 DD한다고 예를 들어봅시다. 올리브영의 매출 P*Q = 매장수 * 매장당입객수 * 구매전환율 * 객단가 이고, C = 원가 + 판관비 = 상품매입비 + 인건비 + 마케팅비 + 그외 비용 등등 이겠지요. KBF는 매장입객수나 구매전환율 변수에 포함된 개념이 될 것입니다. 또한, 상품 매입비나 마케팅비를 어떻게 줄이면서도 효과적인 자본효율을 내는지 등이 KSF가 되는 것이지요. 즉, 중요한건 기업의 모든 전략은 PQC의 세부변수들을 어떻게 늘이고 줄일 것인지에 대한 고민에서 파생됐다는 마인드셋을 갖추는 것입니다.
위의 그림은 PQC를 구성하는 Value driver가 어떤 방식으로 KSF 및 KBF와 관련되는지 시각화하고 있다
모델링은 숫자를 다루는 작업이지만 숫자보다 중요한 모델링의 목적은 "이러한 숫자가 무슨 의미가 있는데?" 라는 질문에 답을 할 수 있는 것에 있습니다. 때문에, 각 종 인터뷰, 리서치, 추정을 통해 값을 추론한다 하더라도 숫자 Beyond에 있는 "그래서 왜!! 이렇게 숫자가 변화하는데?"라는 질문에 Rationale를 답할 수 있어야 합니다. 이것이 진정한 DD와 모델링의 의미 이죠.
예를 들어 볼까요? 모델링 결과 건축 PC시장은 '35년까지 연간 20%라는 높은 성장률을 기록한다고 합니다. 모델링 결과를 실제 사업계획에 사용해야 하는 투자자, M&A 담당자, 사업기획담당자들은 이러한 숫자 자체는 의미 없습니다. 그들이 관심있는 건 정말 그 정도로 성장할 건지, 그것을 증명하기 위해 왜 이런 성장을 거둘 수 있는지 확신할 수 있는 근거가 필요하죠. 연간 20% 성장할 수 있는 원인은 1. 수요처의 빠른 준공 요구 2. 현장 안정성을 요구하는 정부의 높아진 허들 이라고 합시다. 더 영리한 사용자들은 한 발 더 나아가 왜 수요처가 빠른 준공을 요구하고 정말 그런게 맞는것인지, 정부의 높아진 허들이란 구체적으로 어떤 법안을 말하는 건지, 그런 법안이 정말 통과될 가능성이 있는 지 등 PC시장의 성장이 정말 발생할 가능성이 높은 가설인지 확인하고 싶을 것입니다.
때문에 CDD를 하기위한 조사 항목 리스트나 프레임웤이 중요한게 아니라 시장 성장 추이, KBF, 경쟁사 역량 등 기본적인 조사 항목에 대해 정말 그런지? 왜 그런지? 살을 붙여나가는 것이 훨씬 중요한 작업입니다.
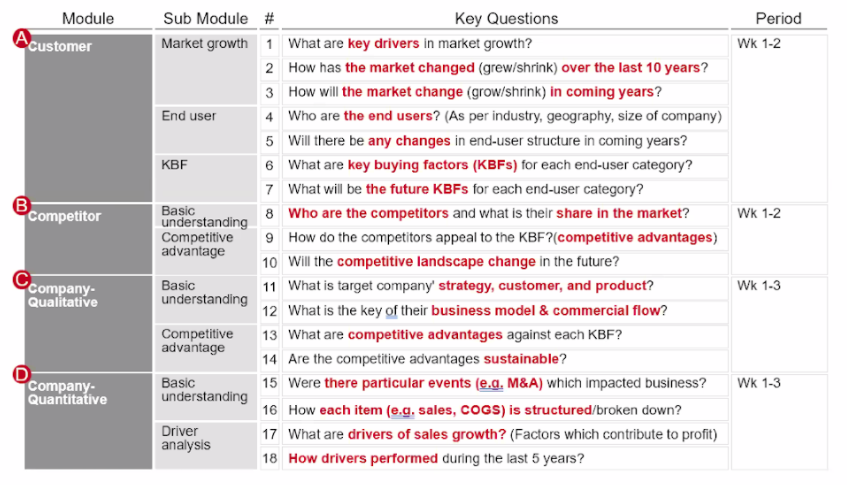
DD를 위한 기본 조사 항목
Modeling(정량 분석)이나 Rationale Deep Dive(정성 분석)를 위해 기업의 여러가지 항목을 조사해야 할텐데요.
이때, 현재와 향후 전체시장규모를 추정하기 위해서 시장분석 및 고객분석, 경쟁사대비 자사선택률을 추정하기 위해서 경쟁환경 분석이 필요로하게 됩니다. 그 외에도 대상기업분석이나 시너지 분석도 PQC를 추정할 때 필수적인 부분인데 정리하면 아래의 시장분석, 경쟁환경 분석 2가지 듀딜리전스 항목이 가장 대표적이며, 부가적으로 경제성 분석, 고객분석, 기업분석, 시너지 및 성장가설, 카운터 전략 분석을 수행합니다.
시장분석, 고객분석
경쟁환경 분석
기업분석
경제성 분석(비용 분석)
시너지 및 성장 가설
카운터 전략(경쟁사에 맞서 시장우위를 위한 전략)
외부환경분석
X
O
시장분석 (P * Q)
O
O
경제성 분석 (비용 분석)
O
O
고객분석
X
O
경쟁환경 분석
X
O
기업분석
O (매출추정)
O
시너지 및 성장 가설
O
O
카운터 전략
X
O
시장분석을 수행함에도 기업 매출 추정을 따로 수행하는 이유는 시장 분석에서 적용되지 않는 성장 가설이 기업 매출에 적용될 수도 있기 때문입니다. 예를 들어, 오리온의 매출을 추정한다고 할 때 글로벌 제과 시장 규모를 추정하고, 오리온의 개별 기업 매출을 추정합니다. 오리온의 경우 러시아, 베트남, 중국 등 글로벌 진출로 인해 시장 성장속도보다 매출 성장 속도가 빠릅니다. 이러한 포인트를 잡기 위해 시장분석과 기업분석 모델링은 따로 수행하는 것이 일반적입니다. 또한 개별 기업은 기존 역량과의 시너지를 통한 Value-up이 가능합니다. 시너지 분석은 시장 분석 밖의 기업의 개별적 요인이기 때문에 매출 분석은 시장분석과 분리해서 생각합니다.
CDD를 위한 세부 조사항목
비즈니스 듀딜리젼스의 최종 목적은 분석 내용은 반영하여 재무 시뮬레이션에 반영하기 위함입니다.(모델링 뿐만 아니라 정성적 자룔 만드는 것도 최종 목적입니다)
fish born으로 표현된 재무 시뮬레이션은 벨류 드라이버로 구성이 되어 있습니다. 기업의 이익을 구성하는 벨류 드라이버는 무수히 많은 변수들로 구성이 되지만, 그 중에서 특히 중요한 변수를 뽑자면, 시장 선택률(시장 KBF)과 기업 선택률(기업 KBF)입니다.
모델링(전략적 분석)을 위한 기초 로직 설계 모습
①외부환경 분석
정치: 정치적으로 어떠한 규제와 지원책이 존재하는지?
경제: 경제성을 실현할 수 있는지?
사회: 사회적인 트렌드에 일치하는지?
기술: 시장 밸류체인의 각 부분이 기술적으로 실현 가능한지?
②시장 환경 분석: 1. 시장의 정의, 2. 해당 시장은 성장할 수 있을 것인지?
해당 시장이 성장하기 위해서는 전체 시장 매출을 높이면 됩니다. 매출을 높이기 위해서는 P나 Q를 높이면 됩니다. 이 때 Q는 기존 및 잠재 전방시장별 판매 규모 * 시장이용률 입니다. 이 중 각 전방시장의 판매 규모와 시장이용률의 벨류 드라이버가 핵심입니다. 각 전방시장별 판매 규모는 전방/최전방 시장 분석(end-user 분석)을 통해서 검증하고, 시장이용률은 타시장 대비 시장 차별성을 검증합니다.
기존 및 잠재 전방시장의 판매 규모는 해당 시장의 타 시장에 진출할 수 있는 시장 파급력과 관련 됩니다. 시스테인이란 화학합성 식용 물질은 본래 사료시장에서 사용되던 물질이지만 근래는 대체육시장에서 수요가 상승하고 있습니다. 전혀 다른 시장으로 진출할 때 시장 규모가 비약적으로 성장합니다.
시장메트릭스를 통한 포지션 분석 및 시장 특정: 시장을 어느 정도로 디테일하게 정의했느냐를 공유할 필요 있음
전후방 밸류체인 분석
제품 및 서비스 분석
해당 시장의 상위 시장 분석을 통한 더 넓은 의미의 시장 성장요인 캐치: 예를 들어, 로션 시장의 경우 로션시장 < 기초화장품 시장 < 화장품 시장의 상위 시장이 존재 Market Metrix로 타겟 시장 규정
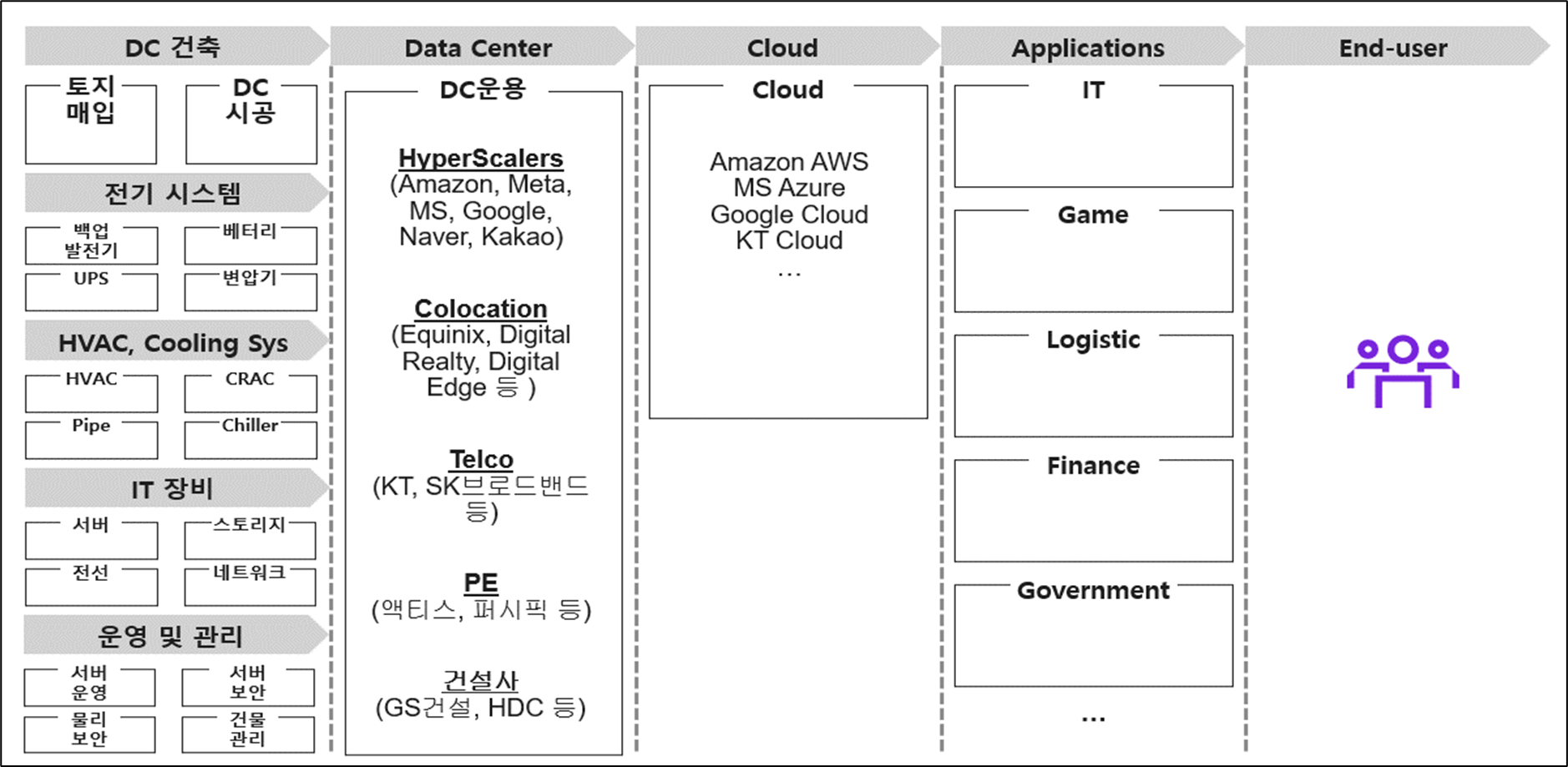
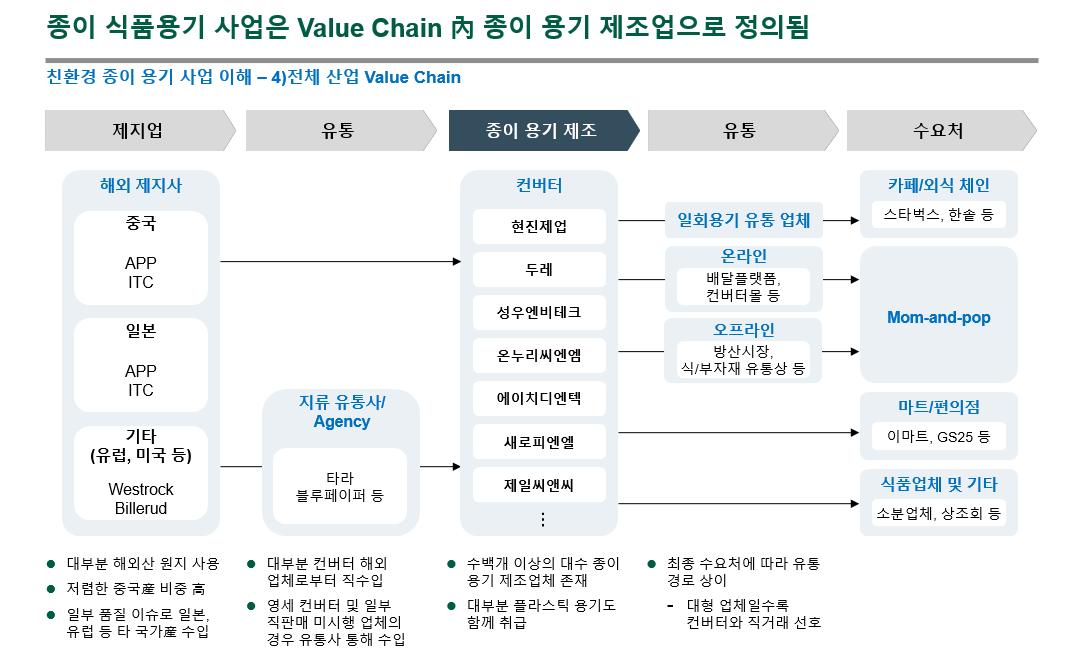
Value Chain 분석 및 시장별 플레이어 상정 (예: 데이터센터 시장)Value Chain 분석 및 시장별 플레이어 상정 (예: 종이 용기 제조업)
시장 전망: ✔ 현재의 시장 규모, 시장 성장률 조사 및 장래 수치 추정(신규 시장인 경우 전방시장에 따른 향후 시장 성장율 변화 예측)
시장 수요 분석: 일반적인 시장규모 추정은 시장 수요 분석만 실시
전방/최전방시장 別 규모 분석(end-user 분석): 기존 고객 시장 분석
어떤 고객(WHO)이 왜(WHY) 우리의 물건을 사주는가?(전방시장 종류 분석): 타겟 시장에서 물건을 구매하는 전방 시장의 활용처(application)는 어디가 있는지? 예를 들어, 분석 타겟 시장이 데이터센터 구축 시장인 경우, 기존 부동산 업자/ 통신사/ 코로케이터/ 카카오와 같은 직접수요자 들이 전방 시장 고객들로 인식 가능. 다른 예로, 분석 시장이 수전해 SOEC 시장일 때, 발전소 시장, 정유 및 화학 시장, 철강 시장들이 전방 시장 고객들로 인식 가능
전방 시장의 니즈 분석: 전방 시장은 우리 시장의 물건을 왜 사주는 걸까? (왜 사주는지를 알아야 향후 지속성에 대한 납득 가능)
장래에도 우리 시장의 물건을 구매해 줄까?
전방 시장이 없는 B2C 시장도 동일하게 활용처(Application)을 중심으로 생각하고 고객군을 구조화하는 방식으로 모델링 실시. b2c에서는 고객층을 age sex price area natl generation time 등으로 나누어 생각한다. 이는 전방시장의 application을 분석하기 위한 방법으로, b2b 시장분석에서 자주하는 전방 application을 구조화하는 것과 동일한 발상이다. 소비자 집단은 b2b처럼 명확히 application이 나누어져 있지 않기 때문에 age sex price area natl generation time와 같은 유의미한 구조화를 통해 application을 파악하고자 하는 것이다.
ex1) AA 건전지: 리모컨, 장난감, 사무용품 등
ex2) 필기 타블릿: 웹툰 작가, 음악가, 유튜버 등
전방/최전방 시장(end-user)의 수요 분석 및 확대 요인 분석: 벨류 드라이버 구조화를 통한 추정
전방/최전방 시장(end-user)의 수요를 segment(area age sex price sku store natl)에 따라 분석하면 정확한 추정에 유의미. 예를 들어, 미용기기 시장 분석 시 40세 이상 인구 비중이 늘어날 수록 매출이 늘어나는 경향 有
기존 및 신규 전방시장의 확대: 신규 고객 시장 분석
B2C의 신규 전방 시장: age sex time area channel.. 에 따른 신규 Position으로의 파급 가능성 분석
B2B의 신규 전방 시장: 신규 산업군에 따라 분석
기존의 고객 산업 이외에 새로운 산업의 고객유치 가능성 여부
향후 새로운 잠재시장으로의 전방 파급력 가능성 분석
시장이용률 (시장차별요인)
외부환경
정치: 정치적으로 어떠한 규제와 지원책이 존재하는지?
경제: 경제성을 실현할 수 있는지?
사회: 사회적인 트렌드에 일치하는지?
기술: 시장 밸류체인의 각 부분이 기술적으로 실현 가능한지?
대체시장
어떤 종류의 대체시장 및 보완시장이 존재하는지 파악
해당 시장이 대체 시장 대비 어떠한 점이 우위에 있어서 향후 성장할 가능성이 있는 것인지?
전방/최전방 시장의 segment별 시장 차별요인 분석
시장 공급 분석
국내 생산
국내 생산 업체 갯수
각 업체별 생산 가능 물량
국외 생산(수입)
국내 수출 국가 갯수
각 국가별 생산 업체 갯수
각 업체별 생산 가능 물량
국내향 수출률
시장 Feasibility: 시장이 정말 개화할 수 있을 것인가?
PEST에 프레임워크에 따른, 시장을 둘러싼 규제・경제성・사회적 트렌드・기술 현실성 분석
과거에는 해당 시장이 주목받지 못했지만, 왜 이제서야 주목받는 이유: EX) 수소경제 - 과거에도 수소경제가 주목받았지만 현재와 다른 이유는 1. 기술 발달에 따른 수소 경제 현실성 증가 2. 광범위하고 지속적인 보조금 및 규제 확인
해당 시장 관련 ValueChain의 개화 여부
유사사업 존재 여부
시장 진입 가능성 분석
정부규제, IP, 초기투자 비용, 경쟁도 등
시장 기본 분석
시장 마진
시장 쉐어: Top쉐어 기업의 점유율이 높고 고착화되어 있으면 참입의 여지가 적음
시장 원가 구조
시장의 유통 시스템
③고객 분석: "시장 정의의 종단점"
✔어떤 고객(WHO), 왜(WHY) 해당 재화 및 서비스 소비하는지?(KBF)
고객이 왜 WHY 대체시장이 아닌 대상 시장을 이용하는 요인 탐색
예) 스킨케어 시장에서는 여드름・미백・홍조・주름・색소・침착・잡티와 같은 CONCERN, 비건LGBT친환경과 같은 VALUE로 더 세부화할 수 있음
어떤 고객 WHO가 해당 시장의 제품과 서비스를 사용하는지
화장품 시장의 예) 연령별・성별・경제력별・지역별・피부타입별 등
일반적인 시장의 예) age sex areaprice natl economy race
(한 발 더 나아가서) 언제 WHEN 해당 재화나 서비스를 소비하는지
✔고객 구조 및 트렌드 변화에 따른 KBF의 변화 탐색
고객인 특정 회사를 이용하는 요인 탐색
✔고객 KBF 파악
축별 매출 분석(나이 성별 시기별 SKU별 채널별 지역별 가격별 목적별 전방시장별 국가별) ➡ 기존사업강화 뿐만 아니라 신사업 진출에 대한 인사이트도 얻을 수 있음
가장 매출이 높은 고객군 탐색
④경쟁 환경 분석
기본 분석(경쟁 기업 파악, 쉐어파악, 매출 성장률, 영업이익률, ROIC)
시장 쉐어: 소수의 기업이 과점하는 구조일 경우 참입이 쉽지 않음
경쟁 Landscape 분석
시장 메트릭스에서 경쟁사의 포지션 분석: 벨류체인과 산업 및 제품 축으로 나뉘어진 시장 메트릭스 上 경쟁사의 진출 시장 파악
경쟁사의 시장내 포지션 분석: 포지션 분석을 시행하는 이유는 경쟁사별 어떤 고객에게 강점이 있는지, 또한 어떤 포지션에 참입할 수 있는 여지가 있는지를 판단하기 위함
전방 시장이 B2C 인 경우: 소매 고객층(age sex area time natl price store sku)에 따른 시장 점유율
전방 시장이 B2B 인 경우: 전방 시장 종류에 따른 시장 점유율
KBF 관련 분석
타겟 시장 KBF 파악: 예) 골판지 상자 제작사들은 골판지를 구매할 때 어떤 요인을 가장 중요하게 볼까?
KBF를 만족시키기 위한 기업별 KSF 역량 분석
각 경쟁사의 KSF가 가지는 진입 장벽 및 커피 가능성 분석
각 경쟁사별 향후 변화하는 시장 KSF를 만족하는 주요 역량 분석
경쟁 상대의 SWOT분석
(optional)자사 분석과 동일한 밀도의 경쟁 상대 분석
[참고] KBF, KSF, TREND의 차이
KBF: 하위 제품단에서의 고객 구매요인 KSF: 구객 구매 요인을 더욱 효율적이고 효과적으로 달성하기 위해 기업단에서의 고민 TREND: 하위 제품단이 모인 상위 시장에서 제품 전체적으로 나타는 경향성
[참고] 시장 KBF 분석 시 중요한 건 Why, What, How, Who, When을 파는 것
시장 KBF란, 고객들이 재화 및 서비스 구매시 최우선으로 삼는 기준이다. 이는 시장마다 상이하다. 수전해조 시장에서는 가격·수소전환비율이 KBF가 될 수도 있고, 유통 플랫폼 시장에서는 상품수·배송속도·CS만족도가 KBF가 될 수 있다. 또한, 특별한 제품 스펙이 요구되지 않는 골판지나 이쑤시개 시장에서는 오로지 가격만이 주요 KBF일 수도 있다. 시장 내 각 기업은 점유율 확장을 위해 고객이 우선적으로 삼는 KBF를 충족시키기 위해 노력하고 있으며, 이러한 노력은 각 기업 고유의 KSF가 된다. 이처럼 KSF는 KBF를 달성하기 위해 각 기업들이 노력 포인트로 Top-Down적 사고과정에서 파생되**어야 한다.**
그런데 시장 KBF 를 분석하면 매우 당연한 이야기지만 반드시 등장하는 것이 바로 "가격·품질"이다. 그러나 단순히 "가격이 이 시장의 KBF입니다" 라고 말하는 건 아무런 의미도 없다. 싼 가격과 좋은 품질의 제품을 원하지 않는 사람이 어디있단 말인가?
정말 필요한 정보는 각 KBF에 대한 Why What How이다. 왜 다른 요인이 아니라 해당 KBF가 고객이 우선하는 요소인지(Why), 품질 요소란 구체적으로 무엇을 의미하는지(What), 가격 경쟁력을 갖추기 위해서는 어떻게 해야하는지·가격 경쟁력을 갖추기 위해 어떤 비용을 줄여 나가야하는지· 비용을 줄이기 위해서는 어떤 자산을 갖추어야 하는지(How) 등 sub-level의 이야기가 심도있게 나와야한다.
1. Why? 고객의 여러 KBF 중에서도 우선순위가 있다. 수전해조 시장에서는 수소발생효율과 가격이 주요 KBF이지만, 수소발생효율이 가격 요인 보다 중요하다. 왜냐하면, 소재기술 발달로 수전해조 내용년수가 증가함에 따라 TCO관점에서 본다면 수소발생효율이 높은 편이 초기 가격이 조금 비싸더라도 10년후에도 더 이득일 수 있기 때문이다. 이처럼 각 KBF가 왜 고객의 필수 요구사항 인것인지? 여러 KBF들 중 어떤 요인이 가장 우선도가 높은지 파악해야 더 높은 우선순위의 KBF를 만족시키기 위해 역량을 집중할 수 있다.
2. What? 의미있는 KBF를 분석하기 위해서는 KBF를 더 구체화시킬 수 있다(What). 폐배터리 재활용 원료 시장에서 원하는 품질이란 리튬의 순도가 XX% 이상이라는 구체적 품질의 기준이 등장할 수 있다. 또한 가려움증 개선 로션 시장에서 원하는 품질이란 보습도가 더 높고 인체친화적인 친환경 원료를 사용한 것이 될 수 있다.
3. How? KBF가 구체화되었다면 다음은 이러한 고객 KBF를 만족시키기 위해서 시장 내 각 기업들이 개별적으로 어떤 노력들을 하고 있느냐를 파악할 수 있다. 이러한 기업의 노력들이 각 기업이 보유한 KSF가 된다. 동일한 시장 내라고 하더라도 각 기업은 고유의 방법을 통해 KBF를 달성할 수 있다. 위에서 예로든 가려움증 개선 로션시장에서 더 높은 보습도를 달성하기 위해, 어떤 기업은 원료 연구에 몰두할 수 도 있고, 다른 어떤 기업은 원료 연구보다 원료 간의 Mixing 기술에 초점을 둔 Recipe를 발전시켜 나갈 수도 있다.
골판지 시장 제품 특성 상 품질에 대한 요구도가 높지 않은 제품에 대해서는 가격만이 구매 결정 요인인 제품도 있다. 예를 들어, 골판지 시장의 고객은 골판지 상자 제조사 인데, 골판지는 시장 내 경쟁사 間 특별한 품질적 차이가 나지 않는다. 가격이 최우선 KBF인 시장에서는 가격을 낮추기 위한 노력들이 KSF가 된다. 가령, 골판지 원료가 되는 펄프 수직계열화를 통한 완가 절감 · 운영비 절감을 위한 자동화 · 더 최소한의 펄프사용으로 더 단단한 골판지를 만들기 위한 기술개발연구 등이 있다.
폐배터리 재활용 시장 *_폐배터리 재활용 시장에서 고객들의 가장 큰 관심사는 *_품질과 납품 안정성이다. 폐배터리 재활용 광물의 품질은 추출 기술이 성숙되어 평균 추출률 95% 정도로 형성되어 있다. 이는 시장내 경쟁사 間 큰 차이가 없다. 폐배터리 재활용 시장에서는 품질보다 오히려 납품 안정성이 중요하다. 폐배터리 재활용은 폐기된 배터리를 재활용하여 광물을 추출하는 시장이기 때문에, 사업의 전제가 되는 폐배터리가 없으면 제품 생산자체가 안된다. 폐배터리 시장의 player들은 폐배터리를 원활하게 수급하기 위해 세계 곳곳에 폐배터리 수집 공장을 건설한다. 또한, 수집 공장을 건설하기 위해서는 자금 융통이 중요하다. 보유 현금흐름으로 공장을 짓는게 아니라면 저리(低利)로 유통 가능한 Financing 능력이 또 다른 KSF 일 것이다.
유통 커머스 플랫폼 시장 유통 플랫폼 시장은 고객들로 하여금 많은 상품수, 빠른 배송을 우선적으로 요구 받는다. 쿠팡은 유상증자 후 미친 듯이 많은 물류 창고를 건설했는데, 더 많은 물류 창고가 KBF를 만족시킬 수 있는 핵심 KSF이기 때문이다. 이에 더 나아가서, 쿠팡은 물류 창고를 매우 자동화 하여 주문과 동시에 발주가 자동화되도록 시스템을 갖추었다. 주문 -> 발주에 이르는 자동화는 빠른 배송을 가능케 하는 또 다른 KSF이기 때문이다.
⑤타겟 기업분석
해당 기업의 쉐어를 높이기 위해선 매출을 높이면 됩니다. 매출을 높이기 위해서는 P나 Q를 높이면 됩니다. 이 때 Q는 전방시장수요 * 시장이용률 * 자사 선택율이므로, 자사 선택율이 핵심 벨류 드라이버가 되는데, 기업 선택률을 높이기 위해서 가장 중요한 분석 항목은 기업에 대한 KBF입니다.
한편 기업의 이익은 Q에서만 오지 않습니다. P와 C를 통해서도 실현할 수 있습니다. 기업의 성장가설에서는 PQC를 폭넓게 고려하여 성장의 방향성과 정량적 재무 시뮬레이션을 진행합니다.
아래 항목에서는 Law Due Diligence, Finance Due Diligence 까지 폭넓게 포함하고 있습니다. CDD에서는 타겟 기업의 KBF, KBF를 만족시킬 수 있는 역량을 중점적으로 분석하는 것이 필요합니다.
시장메트릭스를 통한 포지션 분석 및 진행 중인 사업 분석
전후방 밸류체인 분석
제품 및 서비스 분석
비즈니스모델 분석
비즈니스 모델의 키 분석(비즈니스 모델에 따라 Driver가 달라짐)
★비즈니스 모델 분석을 통한 벨류 드라이버 분석 및 핵심 드라이버 추출
✔KSF: 시장 KBF 만족시키기 위한 필수 역량은 무엇이 있으며, 해당 기업은 이 역량을 만족하고 있는지?
전문가 인터뷰 등을 통해 업계의 KSF 요인 분석
당사의 역량과 KSF 비교
당사가 KSF를 달성하기 위해 필요한 action 분석
✔KBF: 고객이 해당 경쟁사가 아닌 해당 기업을 이용하는 이유는 무엇인지?
시장 내 KBF는 무엇인지? 향후 KBF는 어떻게 변화해 나갈 것인지?
KBF를 만족시킬 수 있는 타겟 기업의 역량은 어떻게 되는지? 향후 그러한 역량을 갖출 수 있는지?
Price: 메모리반도체, 원자재와 같이 제품 자체의 차별성이 존재하지 않는 제품 및 서비스는 결국 가격 차별성으로 수렴
Product: 시장내 제품 및 서비스의 차별성 분석(품질, 성능, 디자인, 제품수명주기)
SWOT 분석은 강점 뿐만 아니라 약점을 분석함으로써 타겟에 대한 객관적인 시각을 잃지 않게 해주는 유효한 Tool
자본구조 분석
타인자본 분석: 부채비율, 부채이자율, 부채 목적, 채권자 분석
자기자본 분석: 주요 주주 및 지분, 증자/감자/CB/BW등 자본 변화 분석
관계회사 지분과 실적
자회사 지분과 실적
재무제표를 통한 재무 상태 분석
대차대조표 분석: 구성비, 성장율, 부채비율, 그외 이상한 점
손익계산서 분석: 구성비, 성장율, 그외 이상한 점
축별손익계산서 분석: 사업별 손익계산서
현금흐름표 분석: 영업/투자/재무 관점에서의 현금 유출 분석
✔ROIC 모델링: 신규 CAPEX 없이도 돈 잘 벌 수 있는 비즈니스 모델인지
해당 기업 보유의 유형자산 분석
생산거점
가동율: f(인력, 원자재, 설비, ETC)
생산량
해당 기업 보유의 무형자산 분석(DATA, 특허)
보유 데이터 파악
보유 데이터를 통한 신규 산업 혹은 기존 산업에의 이익변수와 연결
보유 라이센스 및 특허의 차별성 파악
7S분석: Strategy System Structure SharedValue Skills Staff Style
경영자 분석
사내 직원 평가 분석
매출 모델링: 상기에서 분석한 KSF 및 KBF 기반 매출 모델링 실시. 기업 段 매출 모델링은 시장 규모 추정 모델링과는 분석의 축이 다른 경우가 많아 별도로 수행. 예를 들어, 화장품 이커머스 브랜드의 매출은 채널 및 기존・신규 회원 축이 유의미하며, 화학 용품 생산 공장은 공장 캐파와 가동율 축이 유의미하다.
P: 가격
경쟁베이스: 수요공급에 따라 가격이 조정
가치베이스: 기업의 브랜드가치/차별성에 따라 가격이 조정
코스트베이스: 비용 상승에 따른 가격 전가 가능성, 디지털화를 통한 비용 절감 가능성에 따라 가격 조정
정부조정베이스
Q: Q의 Supply분석
생산거점
가동율: f(인력, 원자재, 설비, ETC)
생산량
Q: Q의 Demand분석
기업선택률 분석
축에 따른 세그먼트 분석: 나이 성별 시기별 SKU별 채널별 지역별 가격별 목적별 전방시장별 국가별)
시장 이용율
자사 이용율
Price: 위에서의 가격정략
Product: 시장내 제품 및 서비스의 차별성 분석(품질, 성능, 디자인, 제품수명주기)
날짜: 정보의 최신화는 중요하다. 법, 비즈니스 환경 등은 2-3년으로도 충분히 변할 수 있기 때문에 데이터의 날짜 입력은 필수
검색어: 검색어를 무분별하게 사용하지 않고 검색어 하나하나에 집중하며 리서치 할 수 있을 뿐만 아니라, 내가 어떠한 의식의 흐름으로 검색을 시행하고 있는지 체크할 수 있다.
리서치하는 감
개발이랑 느낌이 비슷한데, 개발할 때 "아, 이런걸 어떻게 만들지? 되긴되나?"라는 마음이 생기지만 손을 움직이면 어떻게든 개발을 한다. 리서치도 이와 마찬가지로 "아, 이런 걸 어떻게 찾지? 절대 안나올거 같은데"라는 생각이 들지만 그걸 찾아내는게 리서치이다. 찾으면 나온다.
오픈리서치 시에는 검색어 설계 후, 검색한 검색어를 표시하면서 리서치하기
최신 데이터를 요구하는 리서치의 경우, 올드 데이터는 재끼기
비즈니스 리서치는 양과 분위기가 중요하지만, TAX나 LEGAL리서치는 정확도가 생명이므로 아래의 두 가지에 특히 주의
데이터의 출처가 어디인지: 신뢰할 수 있는 조직에서 언급한 건지, 법적 근거가 있는 데이터인지
데이터가 최신인지: 법적근거가 있는 데이터라하더라도, 변경된 데이터라면 고객에게 불리하게 작용
검색 후, 검색 페이지를 훑어가며 새탭으로 페이지를 쭉 열어놓고, 20개정도 탭이 쌓이면 페이지들을 하나하나 훑어가기
처음부터 페이지를 모두 보지 말고, 큰 목차를 스킵한 뒤 내가 원하는 정보가 맞는지 먼저 확인하기
리서치를 하다보면, 최신 동향을 알고 싶을 때는 startup으로 검색한다던가 시장 수치를 알고싶을 때는 graph statistics 로 검색한다던가 하는 키워드에 대한 감이 생김
주요 키워드: silicon valley startup graph statistics MIT 기술동향
이미지 검색을 미리 시행하는 것도 하나의 요령
시간에 제한(2시간)을 두고 시간 내 에서 리서치 하기
구조화된 설계를 눈앞에 적어두고 자료 찾을때 마다 설계 방향에 따른 올바른 데이터 인지 아닌지를 확인하기
리서치 도중 추가 리서치가 필요한 키워드에 대해서는 새로운 탭 열어놓고 검색어 넣어 놓기
가설적 검색하기: 발전량이 감소하는 원인을 찾는다고 할때 "발전량 감소"라고 검색해서 망라적으로 리서치할게 아니라 발전량이 감소하는 원인에 대한 가설을 세워 가령 발전량 감소 원인이 省에너지 정책 기조 때문이라고 가설을 세웠다면 발전량 省에너지 정책이라고 검색하면 리서치 속도를 비약적으로 끌어올릴 수 있다.
리서치를 했는데 안나온다..
안나오는 경우 의외로 많다. 비이이이싼 보고서에는 있겠지만 공짜로 얻으려니 쉽지 않다. 이럴땐 다음과 같이 해결한다.
꼭 찾아야 되는 정보인 경우: 돈주고 정보사기
인터뷰
보고서 구매
Statista 등
중요도가 높진 않지만 찾긴 해야하는 경우
1. 추정
최근에 수전해 공장의 수소 저장창고 면적을 찾아야하는 프로젝트가 있었다. 나올 턱이 없다. 돈도 없어서 돈주고 정보를 살수도 없다. 그렇다면 추정이 최고의 방법이다.
수소 저장 창고 면적 = 수소 탱크 용량당 면적 * 수전해 공장 수소 생산량
위의 방법으로 추론할 수 있겠다. 수소 탱크 용량당 면적은 리서치해도 쉽게 나오고 안나오면 사진보고 크기 추정하면 된다. 리서치 결과 1,200L/㎡다.
이처럼 리서치해보고 안나오면 추정해라. 중요한건 고객도 오히려 이런 방식으로 머리써서 찾는걸 더 선호할 때도 있다는 것이다. '컨설팅 업체 맡기니까 이런 접근도 하네' 라는 배울점이 있어서다.
2. 대안 솔루션 고려
꼭 필요한 데이터가 아니라면 동일한 시사점을 갖지만 내용은 다른 정보를 찾아보자. 예를 들어, 최근에 기업 別 수소 시장 점유율을 찾아야하는 프로젝트가 있었는데 신시장이라 그런지 돈주고 데이터가 나오지 않았다. 그런데 이 데이터를 장표에 사용하려고 했던 이유는 '수소 시장의 Leading 기업이였던 Linde라는 회사가 진짜 대단한 회사에요'를 어필하기 위한 목적이었다.
그러면 꼭 수소 시장 점유율을 찾을 필요는 없다. 산업가스 시장 점유율은 좀 더 리서치하기가 편하니 기업 별 산업 가스 시장 점유율로 대체했다.
리서치의 결과 정리
설계에 따라 실행된 리서치 결과는 그 결과물만 보면 input이 정리가 되지 않아 무엇을 의미하는지 이해하기 힘들다. 따라서, 처음 설계한 구조에 따라 input을 삽입해가며 정리해나가는 과정이 필요하다.