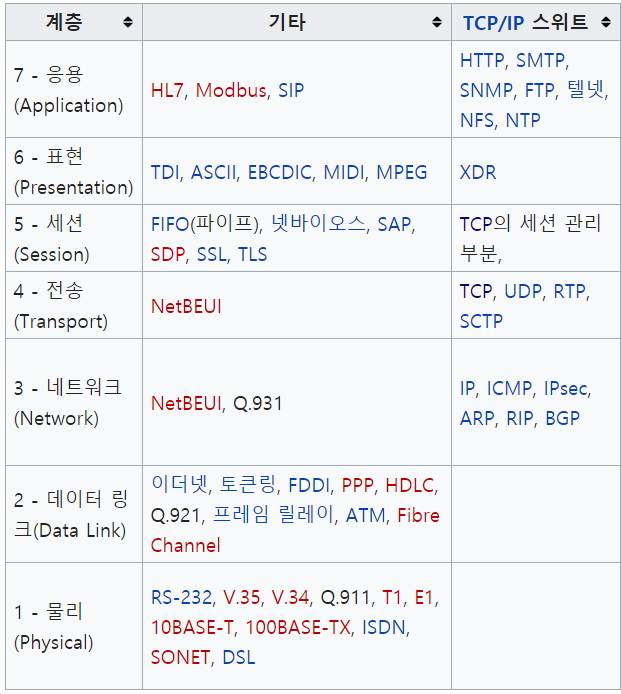
▶ 개발에 있어 가장 중요한 것 : input과 output의 흐름을 파악하는 것
▶ 디렉토리명에는 괄호를 넣지말라
▶ 개발에 있어서 문제점을 파악할 때는, 데이터 흐름의 구분을 지어놓고 한 스텝씩 진행하는 방식이 요구된다.
1. 전체 데이터의 흐름에서 각 스텝을 나눈다.
2. 구문이나 환경변수 등 각 스텝에 했던 일들을 정리한다.
3. 하나하나 천천히 보면서 문제점을 파악해본다.
▶ access로그와 error 로그 보는 것을 생활화하라
데이터의 이동뿐만 아니라 어디서 에러가 나는지 집어낼 수 있다
▶ 되도록 코드를 쓰지마라
무슨 말인가하면, 같은 동작은 실행한다면 되도록 코드를 간결하게 쓰고 장황하게 쓰지않는 쪽이 좋다는 의미이다. 코드는 길어지면 길어질 수록 가독성이 떨어지고 어디에서 에러가 났는지 확인하기 어렵기 때문이다.
▶ 개발의 기본 마인드
1.기능은 되도록 닫기(클래스나 메서드 단위별로 제한된 기능만을 갖기)
2.메인터넌스와 코드 효율성을 증대하기 위해 확장성은 넓히기
3. 누구나 코드를 보면 이해할 수 있도록 적기
▶ 숫자나 문자열등 직접정보가 코드안에 포함되어 있으면 안되는 이유 : 수정요소가 발생할 시 그 숫자나 문자열은 사용한 모든곳을 하나하나 수정해야하는 불상사가 생길 수 있다.
▶ 부하 테스트시 포함되는 조건들
인스턴스 : aws의 인스턴스
프로세스 : 가동된 어플리케이션의 수
스레드 : 하나의 서버에 접속한 사람수: 예를 들어 2명이서 서버 접속하면 스레드는 2개 -> 자바 스레드의 개념추가할 필요있음*
▶ ssh는 /var/empty/sshd에 의해 기동되는데, 이는 root에 의해 소유 되지 않으면 오류가 난다.
(https://support.microsoft.com/ja-jp/help/4092816/ssh-fails-because-var-empty-sshd-is-not-owned-by-root-and-is-not-group)
/var/empty/sshd 디렉토리가 루트에 의해 소유 디어 있어야 하고, 그룹이나 특정인이 writable의 권한을 가지고 있으면 ssh가 실행되지 않는다. 따라서 아래와 같은 명령어로 이 문제를 고칠 수 있다.
chmod 755 /var/empty/sshd;chown root:root /var/empty/sshd;service sshd restart
▶ 문제가 있다면 혼자서 멍때리지 말고 로그를 봐라.
배경 : fluentd가 반응하지 않아서 혼자 설정파일 수십번 바꾸고 바보짓을 했는데, 로그보니까 금방해결 되었다.
'C Lang' 카테고리의 다른 글
| Agile manifesto(애자일 선언문) (0) | 2020.06.02 |
|---|---|
| Redmine의Wiki 폴더구성(예시) (0) | 2019.09.17 |
| Programming Case Types(Camel case, Snake case, Kebab case, Pascal case, Upper case, (with snake case)) (0) | 2019.08.23 |
| 개발 명명 규칙 (0) | 2019.06.07 |