Data types aren’t the only things missing. VBScript also lacks several statements. It’s missing all of the statements related to file I/O, such as Open, Close, Read, and Input. Other statements that are not available are Write. GoSub, On GoSub, On GoTo, On Error, and DoEvents. Table 13.5 contains a complete list of all of the available VBScript statements.
Table 13.5: Statements Supported in VBScript
Statement
Description
Call
Invokes a subroutine
Const
Declares a constant value
Dim
Declares variables
Do/Loop
Executes a loop until a condition or while a condition is True
Erase
Reinitializes the contents of a fixed-size array and frees all of the memory allocated to a variable-sized array
For/Next
Executes a loop while iterating a variable
For Each/Next
Executes a loop while iterating through a collection of objects
Function/End Function
Declares a routine that will return a value
If/Then/Else/End If
Conditionally executes one set of statements or another
On Error
Takes the specified action if an error condition arises
Option Explicit
Requires that all variables must be declared before their use
Private
Declares private variables
Public
Declares public variables
Randomize
Initializes the random-number generator
ReDim
Changes the size of an array
Select Case/End Select
Chooses a single condition from a list of possible conditions
Set
Assigns a reference to an object or creates a new object
날이 갈수록 개인정보 보호에 관련하여 보안정책을 점진적으로 강화하고 있습니다. 이에 따라 Web에서 회원가입 시 Password 설정을 복잡해진 보안정책에 맞추다 보니 복잡하게 조합해야만 정상적으로 가입을 할 수 있습니다. 이러한 강화된 보안정책 때문에 기존에 사용하던 자신만의 Password를 인위적으로 보안정책에 맞추는 경우가 많을 것입니다. 그러다 보니, 종종 Log-In을 할 때 Password를 잊어버려서 곤란한 상황이 발생하는 경우도 한번쯤은 있었을 것입니다. 일반적으로 이렇게 복잡한 조건이 필요한 경우 사용자에게 입력을 받을 때 여러 가지 조건을 주면서 정해진 규칙 안에서만 입력을 하도록 유도를 하고 있습니다. 이번 프로젝트를 진행하면서 사용자가 입력하여 DB에 형식에 맞도록 저장하기 위해 조건을 주는 부분이 있었는데, 간단하게 해결 하기 위해 정규표현식(Regular Expression)을 사용하였습니다. 이 글에서는 정규표현식을 실제로 사용하면서 필요한 정보들을 초보 개발자의 관점에서 해석하고 실제로 사용하는 과정을 담았습니다.
정규표현식이란?
정규표현식의 사전적인 의미로는 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어입니다. 주로 Programming Language나 Text Editor 등 에서 문자열의 검색과 치환을 위한 용도로 쓰이고 있습니다. 입력한 문자열에서 특정한 조건을 표현할 경우 일반적인 조건문으로는 다소 복잡할 수도 있지만, 정규표현식을 이용하면 매우 간단하게 표현 할 수 있습니다. 하지만 코드가 간단한 만큼 가독성이 떨어져서 표현식을 숙지하지 않으면 이해하기 힘들다는 문제점이 있습니다.
*정규표현식을 지원하는 프로퍼티・메서드가 있고, 지원하지 않는 프로퍼티・메서드가 있으므로 정규식을 사용하고 싶다면 먼저 사용하고자 하는 프로퍼티・메서드 파라미터 정보를 확인하여야 합니다. 예를 들어, match,replace함수는 정규표현식을 파라미터로써 용인합니다. 하지만, workbook.Open함수는 순수한 스트링만을 파라미터로써 용인하기 때문에 정규표현식을 파라미터로써 사용할 수 없습니다.
Regular Expression UML
자바스크립트에서 정규식 사용법 : //으로 감싸기
Syntax
/pattern/modifiers;
Example
var patt = /w3schools/i
Example explained:
/w3schools/i is a regular expression.
w3schools is a pattern (to be used in a search).
i is a modifier (modifies the search to be case-insensitive).
정규표현식은 표준인 POSIX의 정규표현식과 POSIX 정규표현식에서 확장된 Perl방식의 PCRE가 대표적이며, 이외에도 수많은 정규표현식이 존재하며 정규표현식 간에는 약간의 차이점이 있으나 거의 비슷합니다. 정규표현식에서 사용하는 기호를 Meta문자라고 합니다. Meta문자는 표현식 내부에서 특정한 의미를 갖는 문자를 말하며, 공통적인 기본 Meta문자의 종류로는 다음과 같습니다.
Meta 문자중에 독특한 성질을 지니고 있는 문자클래스'[ ]'라는 문자가 있습니다. 문자클래스는 그 내부에 해당하는 문자열의 범위 중 한 문자만 선택한다는 의미이며, 문자클래스 내부에서는 Meta문자를 사용할 수 없거나 의미가 다르게 사용됩니다.
POSIX에서만 사용하는 문자클래스가 있는데, 단축키처럼 편리하게 사용할 수 있습니다. 대표적인 POSIX 문자클래스는 다음과 같으며 대괄호'[ ]' 가 붙어있는 모양 자체가 표현식이므로 실제로 문자클래스로 사용할 때에는 대괄호를 씌워서 사용해야만 정상적인 결과를 얻을 수 있습니다.
이밖에도 [:cntrl:] : 아스키 제어문자(0~31번, 127번), [:print:] : 출력 가능한 모든 문자, [:xdigit:] : 모든 16진수 숫자 등이 있습니다.
정규표현식을 실제로 사용할 때 언어마다 사용방법이 각각 다릅니다. 진행했던 프로젝트에서는 정규표현식을 JavaScript에서 사용했는데, JavaScript에서 사용하는 방법에 대해서 설명 하겠습니다. 사용하는 JavaScript 버전이 1.1이하 버전일 경우에는 정규표현식을 사용할 수 없습니다. 정규표현식을 사용하는 방법으로는 두 가지가 방법이 존재하며, 첫 번째로는 'RegExp'객체를 이용하는 방법이 있습니다. 주로 정규표현식이 자주 변경되는 경우 사용합니다.
// RegExp 객체를 이용하는 방법var objectInitializer = newRegExp('정규표현식',['Flag']);
두 번째로는 객체초기화(Object Initializer)를 사용하는 방법입니다. 주로 입력된 표현식이 거의 바뀌지 않는 상수 형태의 표현식을 사용할 때 사용합니다.
자주 사용하는 Flag는 밑의 3종류가 있으며 Flag를 사용을 하지 않을 수도 있습니다. 만약 Flag를 설정 하지 않을 경우에는 문자열 내에서 검색대상이 많더라도 한번만 찾고 끝나게 됩니다.
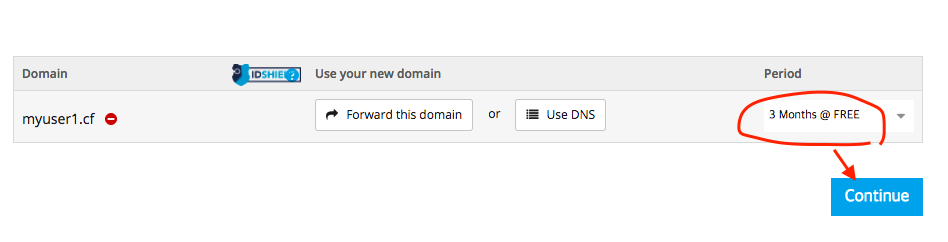
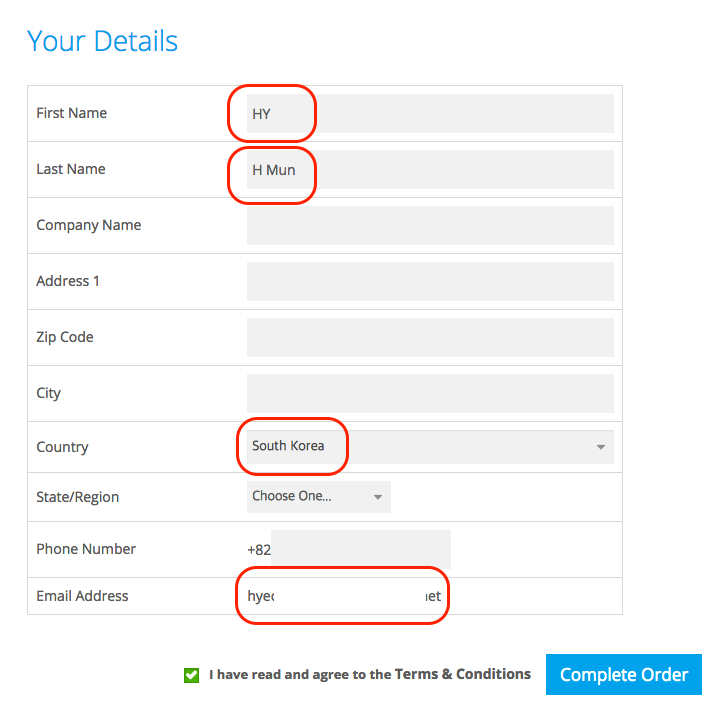
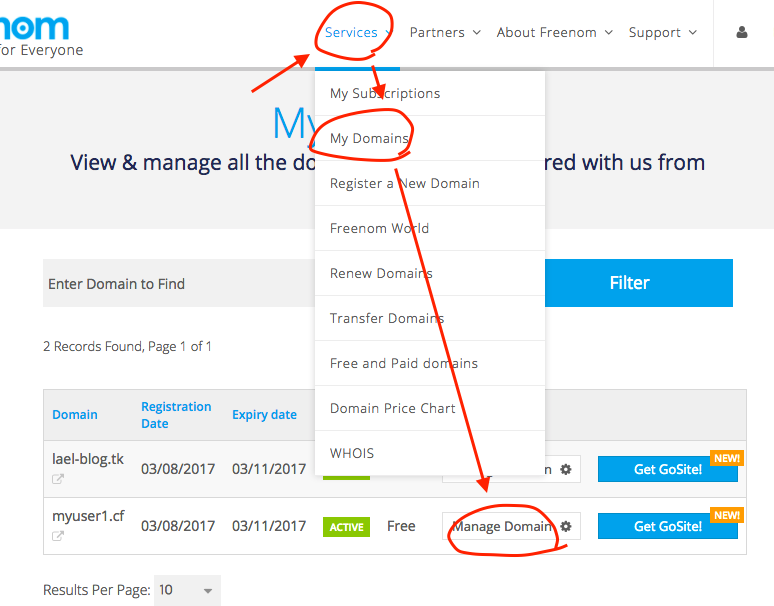
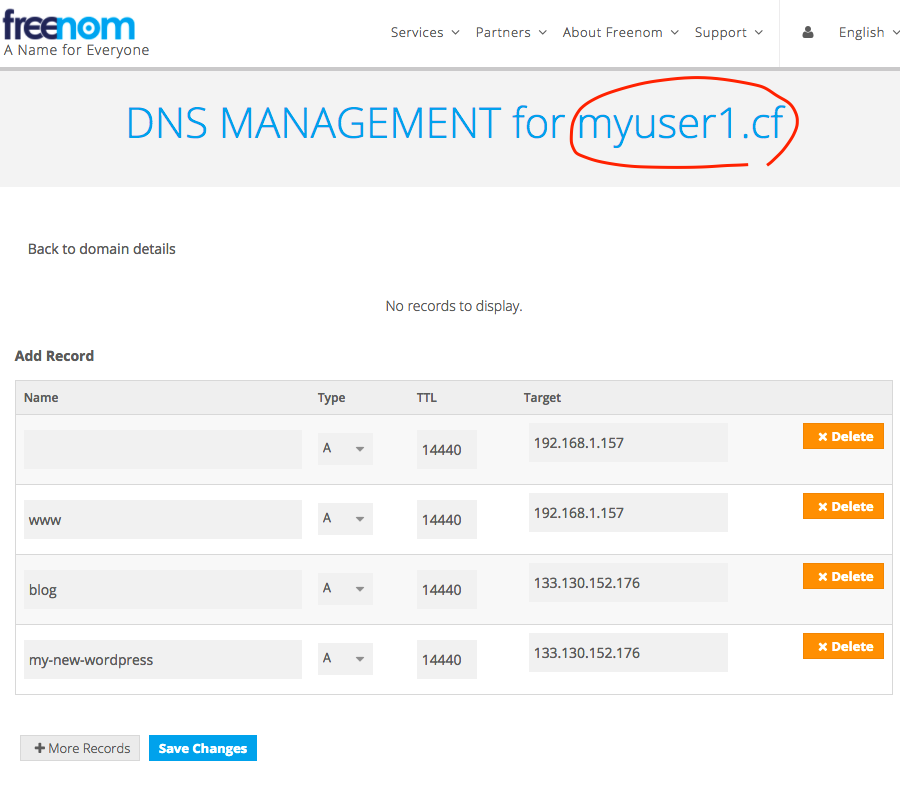
jhkim-140117-RegularExpression-09
이 외에도 공백을 무시하고 주석을 허용하는 x, 개행문자도 포함해서 찾는 s 등 다양한 Flag들이 있습니다.
정규표현식 실제 적용
사용자로부터 값을 입력 받는 부분에서 유효성 체크를 하기 위해 정규표현식을 간단하게 적용한 경우가 있었습니다. 먼저 입력 받은 값은 반드시 한글이 포함되지 않도록 유효성 체크를 하는 부분이 있었습니다. 사용자가 입력한 데이터 중에서 유효하지 않는 데이터를 정규표현식을 이용하여 검색한 뒤 Return하는 방법을 사용하였습니다.
//사용자가 입력한 ID가 한글이 포함되어 있는지 Check 합니다.functionidCheck () {
// 입력한 ID를 Check하기 위해 가져옵니다.var titleCheck = $("titleId").val;
// 정규표현식으로 한글만 선택하도록 만듭니다.var languageCheck = /[ㄱ-ㅎ|ㅏ-ㅣ|가-힣]/;
// 입력한 ID와 정규표현식을 비교하여 한글 여부를 판단합니다.// test외에도 search ,exec , match등을 사용할 수 있습니다.if (languageCheck.test(titleCheck)) {
alert("ID에 한글이 포함되어 있습니다.");
return;
}
...
}
다음으로는 8자리 이하 정수로 이루어진 x, y 좌표를 사용자로부터 입력 받는 경우가 있었습니다. 사용자가 조건에 충족하지 않은 값을 입력할 경우 DB에 적재 할 때나 좌표를 활용할 때 문제가 발생할 수 있기 때문에 유효성 체크가 필요했습니다. 사용자가 값을 입력할 때마다 유효한 값인지 체크를 하고, 잘못된 값을 입력하면 그 값은 Null로 치환을 하는 방법을 사용했습니다. 사용자 입장에서는 유효하지 않은 값을 입력하면 값을 입력하는 순간 아무런 동작을 하지 않은 것처럼 보입니다.
// 8자리 이하인 숫자인지 Check 하는 Function// 사용자가 Key를 입력할 때마다 Function이 호출되도록 구현하였습니다.function checkNumber (data) {
// 사용자가 입력한 값을 Check를 위해 변수에 넣습니다.var checkData = data.value;
// 입력한 값이 8자리가 넘어가는지 Check를 합니다.if ( checkData.length > 8 ) {
// 8자리가 넘어가면 8자리까지만 표현하고 나머지는 제외합니다.
data.value = checkData.substring(0,8);
} else {
// 8자리 이하일 경우// Number형이 아닌값이 입력되면 입력값을 null값으로 대체합니다.
data.value = checkData.replace(/[^0-9]/g, '');
}
}
정규표현식으로 조건을 구현하니 매우 간단하게 해결하였습니다. 이 밖에도 Email Check, File 확장자 Check, 주민등록번호 Check, 문자열 공백제거, 문자열 첫 글자 대문자로 치환 등등 정규표현식을 이용하여 다양한 형태의 유효성검사를 구현할 수 있습니다. 정규표현식을 구현하면서 유용한 Utility들이 있습니다. 물론 이러한 Utility들은 Web에서 다양하게 찾아 볼 수 있지만 프로젝트를 진행하면서 유용하게 사용했던 Utility두가지에 대해서 간단하게 소개하도록 하겠습니다. 먼저 사용자가 정규표현식을 작셩하고 직접 원하는 문자열을 Test 할 수도 있고, quality 높은 표현식을 구현하는데 도움을 주는 Utility입니다. 정규표현식에 대해서 지식이 부족한 사용자도 우측의 정규식 표현 Sample과 그에 대한 설명이 자세하게 나와있어서 쉽게 구현할 수 있습니다. 프로그램을 다운받지 않고 Web에서 직접 실행하므로 별다른 설치 없이도 즉시 사용할 수 있는 편리성이 있습니다. 하지만 Web에서 실행하므로 Off-Line에서는 지원이 안되며, 프로그램 내부에서 전체적으로 Font Size가 작다는 단점이 있습니다.
두번째 Utility는 표현식을 쉽게 이해할 수 있도록 도식화 하는 Utility입니다. 앞에서 정규표현식 표현방법을 소개 할 때 쉽게 이해할 수 있도록 도식으로 처리한 부분도 이 Utility를 이용하여 직접 구현하였습니다. 이 Utility는 표현식을 구현하기 보다는 복잡한 표현식을 해석하고 이해하는 목적이 가장 알맞다고 생각합니다. 프로젝트를 진행하면서 직접 구현한 표현식이 도식으로 목적에 맞게 구현 되는지 Test 할 수 있습니다. 정규표현식에 대해 어느 정도 지식을 갖추고 있는 사용자들에게 적합하다고 생각합니다. 이 Utility도 앞선 Utility와 마찬가지로 Web에서 별다른 설치 없이 즉시 사용 가능합니다.
정규표현식은 자주 쓰지 않으면 금방 잊게 되는 수학공식과 같은 존재라고 생각합니다. 정규표현식에 대해서는 오래전부터 접해보긴 했지만, 매번 수박 겉 핥기 식의 학습으로 인해 정규표현식을 접할 때마다 새로운 느낌을 받았습니다. 이번에 정규표현식에 대해 글을 쓰는 목적 중에 하나는 회사 블로그에 글을 올리면서 이러한 얕은 지식을 정리하고 내 것으로 만드는 계기가 되도록 하는 마음으로 선택하였습니다. 이번 프로젝트에는 정규표현식을 다양하게 사용하지 못해서 한정된 부분만 구현하였지만, 기본 표현법만 제대로 익히면 JavaScript 이외에 다양한 정규표현식에서도 쉽게 응용할 수 있다고 생각합니다.
규식은 문자열에서 문자 조합에 일치 시키기 위하여 사용되는 패턴입니다. 자바스크립트에서, 정규식 또한 객체입니다. 이 패턴들은 RegExp의 exec메소드와 test 메소드 ,그리고 String의 match메소드 , replace메소드 , search메소드 , split 메소드와 함께 쓰입니다 . 이 장에서는 자바스크립트의 정규식에 대하여 설명합니다.
정규식(정규 표현식) 만들기
여러분은 두가지 방법 중 하나로 정규식을 생성할 수 있습니다.
정규식 리터럴(슬래쉬"/"로 감싸는 패턴)을 이용한 방법은 다음과 같습니다.
var re =/ab+c/;
정규식 리터럴은 스크립트가 로드되었을 때 정규식 컴파일을 제공합니다. 만약 정규식이 상수라면, 이와 같은 사용이 성능을 향상시키는데 도움이 됩니다.
생성자 함수를 사용하면 정규식의 런타임 컴파일을 제공합니다. 정규식의 패턴이 변경될 것을 인지하거나 패턴이 예측되지 않을 때 그리고 사용자 입력과 같이 다른 출처로부터 패턴을 가져올 경우에는 생성자 함수를 사용합니다.
정규식 패턴 작성하기
정규식 패턴은 /abc/ 같은 단순 문자의 구성이거나, /ab*c/ 또는 /Chapter (\d+)\.\d*/와 같은 단순 문자와 특수 문자의 조합으로 구성됩니다. 마지막 예제는 기억장치처럼 쓰이는 괄호를 포함하고 있습니다. 패턴화된 부분 문자열 일치 사용하기에서 설명하는것 처럼 패턴에서 괄호를 포함한 부분은 나중에 사용하기 위하여 저장됩니다.
단순한 패턴을 사용하기
단순한 패턴은 직접 찾고자 하는 문자들로 구성됩니다. 예들 들어, /abc/라는 패턴은 문자열에서 정확히 'abc' 라는 문자들이 모두 함께 순서대로 나타나야 일치합니다. 위의 패턴은 "Hi, do you know your abc's?" 와 "The latest airplane designs evolved from slabcraft." 두가지 예 에서 부분 문자열'abc'에서 일치할 것입니다. 'Grab crab' 이라는 문자열에서'ab c' 라는 부분 문자열을 포함하고 있지만, 'abc' 라는 정확한 부분 문자열을 포함하지 않기 때문에 일치하지 않습니다.
특수 문자를 사용하기
검색에서 하나 이상의 b들을 찾거나 공백을 찾는 것과 같이 직접적인 일치 이상의 일치를 필요로 할 경우 패턴은 특수한 문자를 포함합니다. 예를 들어, /ab*c/ 패턴은 'a'문자 뒤에 0 또는 'b' 문자(*은 바로 앞의 문자가 0 개 이상이라는 것을 의미합니다)와 바로 뒤의 'c' 가 따라오는 문자 조합에 일치합니다. 문자열 "cbbabbbbcdebc," 에서 위의 패턴은 부분 문자열 'abbbbc' 와 일치합니다.
특수 문자 앞의 백슬래시는 앞의 문자는 특별하고, 문자 그대로 해석되면 안된다고 알려줍니다. 예를 들어, 앞에 \가 없는 'b'는 보통 소문자 b가 나타나는 어디든지 일치합니다. 그러나 '\b'스스로는 어떤 문자도 일치하지 않습니다; 이 문자는 특별한단어 경계 문자의 형태를 띄고 있습니다.
특수 문자 앞에 위치한 백슬래시는 다음에 나오는 문자는 특별하지않고, 문자 대로 해석되어야 된다고 알려줍니다. 예를 들어, 패턴 /a*/는 특수문자'*'을 0 이상의 'a'들 로 믿습니다. 대조적으로, 패턴 /a\*/ 는 문자열'a*' 같은 문자와 일치할 수 있게'*'의 특수함을 제거합니다.
RegExp("pattern") 표기를 쓰면서 \ 스스로 이스케이프 하는 것을 잊어버리지 마세요. 왜냐하면 \ 는 문자열에서도 이스케이프 문자이기 때문입니다.
예를 들어, /e?le?/ 는 "angel"의 'el' 에 일치하고, "angle"의 'le' 에 일치하고 또한 "oslo" 의 'l'에도 일치합니다.
만약 수량자 *,+,?,{} 바로 뒤에 사용한다면, 기본적으로 탐욕스럽던(가능한 한 많이 일치시키는)와는 반대로 수량자를 탐욕스럽지 않게 만듭니다 (가능한 가장 적은 문자들에 일치시킵니다), 예를 들어, . /\d+/를 "123abc"에 적용시키면 "123"이 일치합니다. 그러나 /\d+?/를 같은 문자열에 적용시키면 오직 "1"만 일치합니다.
또한 이 표 시작부분의 x(?=y) 와 x(?!y)에서 설명된것 처럼 사전 검증 에서도 쓰입니다.
'x'에 일치하지만 일치한 것을 기억하지 않습니다. 괄호는 비포획 괄호(non-capturing parentheses)라고 불리우고, 정규식 연산자가 같이 동작할 수 있게 하위 표현을 정의할 수 있습니다. 정규식 예제/(?:foo){1,2}/을 생각해보세요. 만약 정규식이 /foo{1,2}/라면, {1,2}는 'foo'의 마지막 'o' 에만 적용됩니다. 비포획 괄호과 같이 쓰인다면, {1,2}는 단어 'foo' 전체에 적용됩니다.
예를 들어, /Jack(?=Sprat)/ 는 'Sprat'가 뒤따라오는 'Jack' 에만 일치합니다. /Jack(?=Sprat|Frost)/는 'Sprat' 또는 'Frost'가 뒤따라오는 'Jack'에만 일치합니다. 그러나, 'Sprat' 및 'Frost 는 일치 결과의 일부가 아닙니다.
문자셋(Character set) 입니다. 이 패턴 타입은 괄호 안의 이스케이프 시퀀스를 포함한 어떤 한 문자에 일치합니다. 점(.) 이나 별표 (*) 같은 특수 문자는 문자셋에서는 특수 문자가 아닙니다. 따라서 이스케이프시킬 필요가 없습니다. 다음의 예제에서 보여주는 것 처럼 , 하이픈을 을 이용하여 문자의 범위를 지정해 줄 수 있습니다.
패턴 [abcd] 처럼 일치하는, 패턴 [a-d] 는 "brisket"의 'b' 에 일치하고, "city"의 'c' 에 일치합니다. 패턴 /[a-z.]+/ 와 /[\w.]+/는 "test.i.ng" 전체 문자열이 일치합니다.
음의 문자셋(negated character set) 또는 보수 문자셋(complemented character set)입니다. 괄호 안에 동봉되지 않은 어떤 문자든 일치합니다. 하이픈을 이용하여 문자의 범위를 지정할 수 있습니다. 일반적인 문자셋에서 작동하는 모든것은 여기에서도 작동합니다.
예를 들어, 패턴[^abc]는 패턴[^a-c]와 동일합니다. 두 패턴은 최초로 "brisket"의 'r', "chop."의 'h' 에 일치합니다.
단어의 경계와 일치합니다. 단어의 경계는 단어 문자가 뒤따라오지 않는 위치나, 단어 글자의 앞에서 일치합니다. 단어의 경계는 일치하는 것에 포함되지 않는다는것을 숙지하세요. 다른 말로는, 단어의 경계에 일치하는 것의 길이는 0 입니다. (패턴 [\b]와 혼동하지 마세요.)
예제: /\bm/는 "moon"의 'm'에 일치합니다 ; /oo\b/ 는 'oo'를 뒤따라오는 'n' 은 단어 문자이기 때문에, "moon"의 'oo'에 일치하지 않습니다 ; /oon\b/는 "moon"의 'oon'에 일치합니다. 왜냐하면, 'oon'은 문자열의 끝이라서 뒤따라오는 단어 문자가 없기 때문입니다 ; /\w\b\w/는 어떤 것에도 일치하지 않습니다. 왜냐하면, 단어 문자는 절대로 비 단어 문자와 단어 문자 두개가 뒤따라올수 없기 때문입니다.
숙지하세요: 자바스크립트의 정규식 엔진은 특정 문자 집합을 단어 문자로 정의합니다. 이 집단에 속하지 않은 어떤 문자는 단어 분리(word break) 로 여겨집니다. 이 집단의 문자들은 꽤나 한정되어 있습니다: 이 집단은 오로지 로마자 소문자와 대문자, 10진수 숫자, 밑줄 문자로 구성되어 있습니다. "é" 또는 "ü" 같이, 강세 표시가 되어있는 문자들은 안타깝게도 단어 분리(word breaks) 로 취급됩니다.
정규식 내에서, 문자 그대로 취급되어야 하는 사용자 입력을 이스케이프 처리 하는 것은 간단한 재배치로 할 수 있습니다:
functionescapeRegExp(string){return string.replace(/[.*+?^${}()|[\]\\]/g,"\\$&");// $&는 일치한 전체 문자열을 의미합니다.}
괄호를 사용하기
정규식의 어떤 부분을 둘러싼 괄호는 일치한 부분 문자열을 기억하게 합니다. 일단 기억된다면, 부분 문자열은 패턴화된 부분 문자열 일치 사용하기에서 설명되는것 처럼 다른곳에 사용하기 위하여 호출 될 수 있습니다.
예를 들면, 패턴 /Chapter (\d+)\.\d*/는 추가적으로 이스케이프 되거나 특수 문자 를 이용하고, 그 패턴의 부분이 기억될것이라고 나타냅니다. 이 패턴은 잇달아 하나 이상의 숫자(\d는 숫자를 의미하고 +는 1개 이상을 의미합니다.)와 하나의 소숫점(스스로가 특수문자인; \가 앞서는 소숫점은 패턴은 무조건 문자 그대로의 문자 '.' 을 찾아야 한다는 의미입니다), 0개 이상의 숫자(\d 는 숫자, * 0개 이상을 의미합니다.)가 뒤따라오는 'Chapter '문자들에 정확하게 일치합니다. 추가적으로, 괄호는 처음으로 일치하는 숫자를 기억하기 위하여 쓰였습니다.
이 패턴은 "Open Chapter 4.3, paragraph 6"에서 찾을 수 있으며, '4'가 기억됩니다. 이 패턴은 "Chapter 3 and 4"에서는 찾을 수 없습니다. 왜냐하면 문자열이 '3'이후에 마침표를 가지고 있지 않기 때문입니다.
일치한 부분을 기억하지 않고 부분 문자열을 일치하기 위해선, 괄호에 ?:패턴을 서문으로 쓰세요. 예를 들어, (?:\d+)는 1개 이상의 숫자에 일치하지만 일치하는 문자들을 기억하지 않습니다.
정규식 사용하기
정규식은 RegExp,test,exec,String,match, replace, search, split 메소드와 함께 쓰입니다. 이 메소드는 JavaScript reference에서 잘 설명되어 있습니다.
정규표현식 or 고정된 문자열로 대상 문자열을 나누어 배열로 반환하는 String 메서드입니다.
한 패턴이 어떤 문자열에서 나온 것인지 알고 싶으면, test 나 search 메소드를 사용하는게 좋습니다; 좀더 많은 정보를 원하면 (대신 실행이 느림) exec 나 match 메소드를 사용하는게 좋습니다. 만약 exec 나 match 메소드를 사용했는데 일치하는 부분이 있으면 이 메소드는 배열을 반환하고 정규식 객체에 관련된 properties나 앞서 정의된 정규식 객체인 RegExp properties를 업데이트 합니다. 만약 일치하지 않으면, exec 메소드는 null 을 반환합니다.(강제로 false 값).
아래의 예에서는, 일치하는 문자열을 찾기 위해 exec 메소드를 사용했습니다.
var myRe =/d(b+)d/g;var myArray = myRe.exec("cdbbdbsbz");
만약 정규식 속성에 접근할 필요가 없다면, 아래와 같이 myArray를 만드는 대체적인 방법도 있습니다.
var myArray =/d(b+)d/g.exec("cdbbdbsbz");
문자열로부터 정규식을 구성하고 싶다면, 이런 방법도 있습니다:
var myRe =newRegExp("d(b+)d","g");var myArray = myRe.exec("cdbbdbsbz");
이 스크립트에서, 매칭이 성공하고 배열을 반환한 뒤 아래의 표에서 보이는 대로 속성을 갱신합니다.
정규식 실행결과
Object
Property or index
Description
In this example
myArray
The matched string and all remembered substrings.
["dbbd", "bb"]
index
The 0-based index of the match in the input string.
1
input
The original string.
"cdbbdbsbz"
[0]
The last matched characters.
"dbbd"
myRe
lastIndex
The index at which to start the next match. (This property is set only if the regular expression uses the g option, described in Advanced Searching With Flags.)
5
source
The text of the pattern. Updated at the time that the regular expression is created, not executed.
"d(b+)d"
이 예의 두번째 형식처럼, 변수로 지정하지 않고 객체 초기화로 만들어진 정규식을 사용 할수 있습니다. 하지만 만약 그러면 매 어커런스는 새 정규식이 됩니다. 이러한 이유로 만약 변수로 지정하지 않고 이러한 형식을 사용하게 되면, 나중에 그 정규식의 속성에 접근할 수 없게 됩니다. 예를들어, 이러한 스크립트가 있을 수 있습니다.
var myRe =/d(b+)d/g;var myArray = myRe.exec("cdbbdbsbz");console.log("The value of lastIndex is "+ myRe.lastIndex);// "The value of lastIndex is 5"
그러나, 만약 이러한 스크립트가 있으면:
var myArray =/d(b+)d/g.exec("cdbbdbsbz");console.log("The value of lastIndex is "+/d(b+)d/g.lastIndex);// "The value of lastIndex is 0"
두 상태의 /d(b+)d/g 어커런스는 다른 정규식 객체이고 이런 이유로 그것의 다른 마지막 위치 속성 값을 갖게 됩니다. 만약 객체 초기화된 정규식 속성의 접근이 필요하다면, 먼저 변수로 지정해야 합니다.
패턴화된 부분 문자열 일치 사용하기
정규식 패턴에서 소괄호를 포함하는 것은 기억되는 서브매칭에 해당하는 것을 발생시킵니다. 예를들면, /a(b)c/ 는 'abc' 와 매칭시키고 'b'를 기억합니다. 이러한 소괄호가 쳐진 일치하는 문자열을 불러오기 위해, 배열 요소 [1], ..., [n] 를 사용합니다.
소괄호가 가능한 문자열의 수는 제한이 없습니다. 반환된 배열은 찾아낸 모든 것들을 갖고 있습니다. 다음의 예는 소괄호가 쳐진 일치하는 문자열들을 어떻게 이용하는지 보여 주고 있습니다.
다음의 예는 문자열의 단어를 바꾸기 위해 replace() 메소드를 이용하고 있습니다. 글자를 바꾸기 위해, 이 스크립트는 첫번째와 두번째 소괄호가 쳐진 일치하는 문자열을 의미하는 대체물의 $1 과 $2 를 사용하고 있습니다.
var re =/(\w+)\s(\w+)/;var str ="John Smith";var newstr = str.replace(re,"$2, $1");console.log(newstr);
이것은 "Smith, John"을 출력합니다.
플래그를 사용한 고급검색
정규식은 전반적이고 대소문자를 구분하지 않는 검색을 따르는 네가지 선택적인 표기 방식이 있습니다.
Regular expression flags
Flag
Description
g
Global search.
i
Case-insensitive search.
m
Multi-line search.
y
Perform a "sticky" search that matches starting at the current position in the target string.
정규식과 플래그를 포함하기 위하여 이 문장을 사용합니다:
var re =/pattern/flags;
혹은
var re =newRegExp("pattern","flags");
이 플래그는 정규식의 필수적인 부분임을 기억 하는게 좋습니다. 이것들은 나중에 추가되거나 제거될 수 없습니다.
예를들어, re = /\w+\s/g 는 띄어쓰기 다음에 한개 이상의 문자를 찾는 정규식을 생성합니다. 그리고 문자열 도처의 조합을 찾습니다.
var re =/\w+\s/g;var str ="fee fi fo fum";var myArray = str.match(re);console.log(myArray);
이것은 ["fee ", "fi ", "fo "]를 보여줍니다. 이 예에서:
var re =/\w+\s/g;
이 라인은 이렇게 치환 될 수 있습니다:
var re =newRegExp("\\w+\\s","g");
그리고 똑같은 결과를 얻습니다.
m 플래그는 여러줄의 입력 문자열이 여러 줄로 다뤄져야 하는 특별한 경우에 쓰입니다. 만약 m플래그가 사용되면, ^ 와 $ match at 전체 문자열의 시작과 끝 대신에 입력 문자열 안의 어느 시작점과 끝에 일치시킵니다.
예시
다음의 예는 정규 표현식의 몇 가지 사용법을 보여줍니다.
입력 문자열에서 순서를 변경하기
다음 예는 정규식의 형성 과정, string.split()과string.replace()의 사용을 설명합니다. 그것은 공백, 탭과 정확히 하나의 세미콜론의 구분으로 이름(이름을 먼저)이 포함된 대략 형식의 입력 문자열을 정리합니다. 마지막으로, 순서(성을 먼저)를 뒤바꾸고 목록을 정렬합니다.
// The name string contains multiple spaces and tabs,// and may have multiple spaces between first and last names.var names ="Harry Trump ;Fred Barney; Helen Rigby ; Bill Abel ; Chris Hand ";var output =["---------- Original String\n", names +"\n"];// Prepare two regular expression patterns and array storage.// Split the string into array elements.// pattern: possible white space then semicolon then possible white spacevar pattern =/\s*;\s*/;// Break the string into pieces separated by the pattern above and// store the pieces in an array called nameListvar nameList = names.split(pattern);// new pattern: one or more characters then spaces then characters.// Use parentheses to "memorize" portions of the pattern.// The memorized portions are referred to later.
pattern =/(\w+)\s+(\w+)/;// New array for holding names being processed.var bySurnameList =[];// Display the name array and populate the new array// with comma-separated names, last first.//// The replace method removes anything matching the pattern// and replaces it with the memorized string—second memorized portion// followed by comma space followed by first memorized portion.//// The variables $1 and $2 refer to the portions// memorized while matching the pattern.
output.push("---------- After Split by Regular Expression");var i, len;for(i =0, len = nameList.length; i < len; i++){
output.push(nameList[i]);
bySurnameList[i]= nameList[i].replace(pattern,"$2, $1");}// Display the new array.
output.push("---------- Names Reversed");for(i =0, len = bySurnameList.length; i < len; i++){
output.push(bySurnameList[i]);}// Sort by last name, then display the sorted array.
bySurnameList.sort();
output.push("---------- Sorted");for(i =0, len = bySurnameList.length; i < len; i++){
output.push(bySurnameList[i]);}
output.push("---------- End");console.log(output.join("\n"));
입력을 확인하기 위해 특수 문자를 사용하기
다음 예에서, 사용자는 전화번호를 입력 할 것으로 예상됩니다. 사용자가 "Check" 버튼을 누를 때, 스크립트는 번호의 유효성을 검사합니다. 번호가 유효한 경우(정규식에 의해 지정된 문자 시퀀스와 일치합니다), 스크립트는 사용자에게 감사하는 메시지와 번호를 확인하는 메시지를 나타냅니다. 번호가 유효하지 않은 경우, 스크립트는 전화번호가 유효하지 않다는 것을 사용자에게 알립니다.
비 캡처링 괄호 (?: , 정규식은 세 자리 숫자를 찾습니다 \d{3} OR | 왼쪽 괄호\( 세 자리 숫자 다음에 \d{3}, 닫는 괄호 다음에 \), (비 캡처링 괄호를 종료)) 안에, 하나의 대시, 슬래시, 또는 소수점을 다음과 같이 발견했을 때, 세 자리 숫자 다음에 d{3}, 대시의 기억 매치, 슬래시, 또는 소수점 다음에 \1, 네 자리 숫자 다음에 \d{4} 문자를 기억합니다([-\/\.]).
사용자가 <Enter> 키를 누를 때 활성화 변경 이벤트는 RegExp.input의 값을 설정합니다.
<!DOCTYPE html><html><head><metahttp-equiv="Content-Type"content="text/html; charset=ISO-8859-1"><metahttp-equiv="Content-Script-Type"content="text/javascript"><scripttype="text/javascript">var re =/(?:\d{3}|\(\d{3}\))([-\/\.])\d{3}\1\d{4}/;functiontestInfo(phoneInput){var OK = re.exec(phoneInput.value);if(!OK)window.alert(OK.input +" isn't a phone number with area code!");elsewindow.alert("Thanks, your phone number is "+ OK[0]);}</script></head><body><p>Enter your phone number (with area code) and then click "Check".
<br>The expected format is like ###-###-####.</p><formaction="#"><inputid="phone"><buttononclick="testInfo(document.getElementById('phone'));">Check</button></form></body></html>
by 신영진(YoungJin Shin), codewiz at gmail.com, @codemaru, http://www.jiniya.net
컴퓨터에서 무엇인가를 동시에 실행시킨다는 개념은 초창기부터 있었다. 실제로 1970년대 유닉스 구현에는 이미 멀티태스킹이라는 개념이 포함되어 있었다. 하지만 이런 방식이 범용적으로 사용되기 까지는 오랜 시간이 걸렸다. 1995년 Windows 95가 나오기까지 PC 운영체제를 거의 독점했던 DOS 시절에는 한번에 하나의 프로그램이 실행되는 것이 상식이었고, 다른 프로그램과 동시에 실행되는 프로그램을 만드는 것이 대단한 테크닉으로 취급 받았다. Windows 3.1의 등장과 함께 멀티태스킹이란 개념이 일반인들에게 본격적으로 소개되었다. Windows 3.1은 DOS 위에서 구동되는 프로그램이었지만 여러모로 현재 Windows의 기틀을 다진 운영체제였다. 비선점형 멀티태스킹 방식을 지원했고 현재 사용되는 GUI의 기본 개념을 소개한 운영체제였다. 이런 시기를 거쳐 Windows 95가 등장하면서 DOS 시절에 굳어졌던 일반인들의 상식은 완전히 뒤집혔다. 이제 프로그램은 원래 당연히 동시에 실행되는 것이고, 운영체제에서 멀티태스킹이란 당연히 지원해야 되는 기능이 돼버렸다. Windows 95의 선점형 멀티태스킹은 일반인들에게 그런 인식을 심어주기에 충분했다.
하지만 모든 일이 항상 좋은 점만 있는 것은 아니다. 일반인들에게 당연한 기능 내지는 축복이 시선을 달리해서 개발자의 입장으로 바라보면 재앙과도 같기 때문이다. 단순히 동시에 실행된다는 사실 만으로는 그렇게 많은 문제가 발생하진 않지만 동시 상황에서 무엇인가를 공유하기 시작하면 지옥 문을 여는 것과 동일한 효과를 가져온다. 단순히 하나만 공유해도 이런데 프로세스 내에서 모든 자원을 공유하는 스레드는 문제 발생의 정도가 더 심각하다. 이런 환경은 개발자에게 엄청나게 많은 문제들을 안겨주었고, 더불어 기존에는 고민할 필요도 없었던 문제들에 대해서 고려하도록 만들었다. 그리고 이 시점부터 더 이상 프로그램은 결정론적으로 동작하지 않게 되었다. 이는 달리 표현하면 재현 불가능한 무수한 버그들이 스레드라는 판도라의 상자를 통해서 세상으로 출현했다는 것이다.
이런 여러 이유로 멀티 스레드 프로그래밍은 윈도우 프로그래밍 중에서도 매우 어려운 부분에 속한다. 그럼에도 점점 더 PC의 코어 수는 늘어가고 멀티 스레드 프로그래밍은 점점 더 당연한 일이 되어가고 있다. 왜 멀티 스레드 프로그래밍이 어려운 것일까? 아마도 우리의 생각 자체가 병렬적으로 동시 처리하는 것에 익숙하지 않은 점에 그 근본적인 원인이 있을 것 같다. 이번 시간에는 컴퓨터에서 멀티태스킹을 구현하는 기본적인 구조와 멀티태스킹이 가져오는 동기화 문제에 대해서 살펴보도록 하자.
시분할
요즘은 CPU가 여러 개 달린 컴퓨터가 일반적이다. 스마트폰에도 듀얼 코어가 탑재되는 세상이니 PC는 두 말하면 잔소리다. 이렇게 CPU가 여러 개 달린 컴퓨터에서는 동시에 실행하는 것이 하나도 이상하지 않다. 장치 개수만큼 동시에 실행할 수 있는 것은 누가 봐도 당연한 일이기 때문이다. 하지만 Windows가 인기를 끌듯 말듯했던 Windows 3.1 시절부터 Windows XP가 등장하던 시점까지는 이러한 멀티 코어가 일반적인 PC 환경은 아니었다. 그 당시 컴퓨터에는 CPU가 하나라는 것이 거의 고정적이었던 시절이었다. 그렇다면 어떻게 이 CPU가 하나인 환경에서 여러 개의 프로그램을 동시에 실행할 수 있었던 것일까? 여기에는 약간의 눈속임이 있다.
눈속임을 쉽게 이해하기 위해서 우리가 공부를 하는 과정에 비유를 들어서 먼저 살펴보도록 하자. 텅 빈 책상이 있고, 책상 앞 의자에 우리가 앉아 있는 상황이다. 책상에는 국어, 영어, 수학 문제집이 놓여 있다. 이 문제집을 다 푸는 것이 오늘 우리의 할 일이다. 이 미션을 달성하는 방법에는 크게 두 가지 전략이 존재한다고 볼 수 있다. 하나는 국어 문제집을 다 풀고, 영어 문제집을 다 풀고, 수학 문제집을 다 푸는 형태로 순차적으로 하나씩 작업을 완료해 나가는 방식이고, 다른 하나는 국어, 영어, 수학 문제집을 번갈아 가면서 조금씩 풀어 나가는 방식이다. 멀티태스킹의 비밀은 바로 두 번째 방법에 있다. 문제집을 번갈아 가면서 푸는 상황에서 문제집을 교체하는 시간을 단축시키다 보면 어느 순간부터는 마치 우리가 세 개의 문제집을 동시에 풀고 있는 것처럼 느껴진다는 사실을 이용한 것이다.
운영체제는 여러 개의 프로그램을 동시에 실행하기 위해서 우리가 문제집을 풀었던 것과 동일한 방식으로 CPU에 프로그램 코드를 할당한다. 탐색기, 계산기, 그림판이 실행되어 있다면 Windows는 탐색기 코드를 조금 실행하고 계산기 코드를 또 조금 실행하고 이어서 그림판 코드를 실행하고는 다시 탐색기 코드를 실행하는 식으로 동시에 실행된 프로그램의 코드들을 잘게 나누어서 반복적으로 실행함으로써 마치 우리 눈에는 여러 개의 프로그램이 동시에 실행되는 것처럼 보이도록 만든다.
문제집을 번갈아 가면서 풀려면 문제집을 바꿀 때에 자신이 마지막으로 풀었던 문제가 어디인지를 기록해 두어야 한다. 그래야 나중에 다시 그 문제집을 풀 때에 어디서부터 풀어나가야 할지 기억할 수 있기 때문이다. 이렇게 마지막으로 풀었던 문제가 어떤 것이었는지를 기억하는 것과 마찬가지로 멀티태스킹에서도 이러한 것들이 필요하다. 작업을 이어가기 위해서는 중지했던 작업을 어디서부터 이어가야 할지를 알아야 하기 때문이다. 이렇게 작업을 이어가기 위해서 중단했던 시점의 기록을 “컨텍스트”, 작업들을 전환하는 것을 두고는 “컨텍스트 스위칭”이라고 표현한다.
문제집을 번갈아 가면서 푼다는 이 방법을 좀 더 살펴보면 재미있는 현상이 있다. 문제집을 너무 띄엄띄엄 번갈아 풀 경우에는 세 개를 동시에 푼다는 느낌이 없어지고, 문제집을 자주 번갈아 풀다 보면 특정 시점 이상부터는 문제집을 푸는 시간보다 문제집을 바꾸는 시간이 더 많아진다는 점이다. 이는 시분할을 사용한 멀티태스킹 시스템에서는 모두 발생하는 문제로 컨텍스트 교체 비용이 공짜가 아니라는 점을 보여준다. 따라서 운영체제는 멀티태스킹의 품질과 교체 비용을 고려해서 작업 교체 빈도를 적절하게 결정할 필요가 있다.
협력형 vs 선점형
앞선 국영수 문제집 풀이 예를 다시 생각해 보자. 여기서 우리가 문제집을 번갈아 푼다고 생각했을 때 이를 통제하는 방식 또한 크게 두 가지 형태로 나뉠 수 있다. 문제집을 푸는 당사자가 자유롭게 일정시간 한 문제집을 풀다가 다음 문제집을 푸는 형태로 번갈아 가면서 푸는 방식이 있을 수 있고, 다른 하나는 선생님이 일정시간마다 들어와서 다음 문제집을 풀도록 지시하는 방법이 있을 수 있다.
그렇다면 이 두 방식에는 각각 어떤 장단점들이 있을까? 우선 스스로 관리하는 방법을 생각해 보자. 이 방법의 장점은 효율성의 극대화에 있다. 문제를 푸는 당사자가 스스로 문제집을 교체하기 때문에 언제 교체하는 것이 가장 유리한지를 알 수 있다는 점이다. 다른 부가적인 장점으로는 선생님이라는 외부 존재가 필요하지 않다는 점을 들 수 있겠다. 이는 다시 말하면 비용이 절감된다는 말이다. 이에 반해서 두 번째 방법은 선생님이라는 추가 비용이 발생하지만 문제집 교체가 일정시간마다 반드시 발생하기 때문에 문제집 세 개에 할당되는 시간이 비슷해 진다. 멀티태스킹의 관점에서 보자면 일정 수준 이상으로 멀티태스킹 품질을 유지할 수 있다는 것을 의미한다.
이게 바로 협력형과 선점형 멀티태스킹의 차이다. 협력형 멀티태스킹이란 멀티태스킹 작업들이 협력해서 동시에 실행되는 구조를 말한다. 프로그램 실행 중간에 스스로 컨텍스트 전환을 해도 되는 시점이라고 판단이 된다면 다음 작업에게 CPU를 양보해주는 형태로 멀티태스킹이 진행된다. Windows 3.1이 이러한 방식을 채택했었다. 하지만 앞서도 언급했듯이 이 방식의 단점은 특정 작업이 지나치게 오래 CPU를 독점할 경우 전체 멀티태스킹의 품질이 떨어질 수 있다는 점에 있다. 더욱 치명적인 문제는 특정 작업의 버그로 인해서 CPU 자원을 다른 작업에게 양보하지 않을 경구 운영체제 자체가 다운될 수 있다는 점이다.
선점형 멀티태스킹이란 협력형과는 반대로 작업 제어 권한을 커널이 가지는 구조를 말한다. 이는 모든 작업이 임의의 시점에 커널에 의해서 선점될 수 있음을 의미한다. 선점된다는 말은 CPU 자원이 커널에게로 다시 넘어간다는 것이다. 여기에선 특정 작업이 CPU를 독점할 수도 없으며, CPU를 독점하려 한다고 해도 커널이 원하면 언제든지 CPU 제어권을 뺏어올 수 있다. 즉, 커널이 선생님의 역할을 한다고 할 수 있다. 이 방식의 장점은 앞에서도 설명한 것과 같이 안정적으로 멀티태스킹을 수행할 수 있으며, 작업들의 버그로 시스템다운이라는 치명적인 결과가 나타나진 않는다는 점이 있다. Windows 95 이후의 모든 Windows 운영체제는 이러한 선점형 멀티태스킹 방식으로 멀티태스킹을 구현하고 있다.
스레드
전통적으로 운영체제에서 작업이란 프로세스란 개념으로 표현된다. 따라서 운영체제는 앞서 설명한 것처럼 이런 프로세스를 동시에 여러 개 실행할 수 있도록 만들기 위해서 프로세스의 코드를 번갈아 가면서 수행한다. 이렇게 멀티태스킹 운영체제를 만들어놓고 보니 만들어진 프로세스들 중에는 다른 프로세스와 대규모의 자료를 공유해야 하는 것들이 있었다. 이런 프로세스들은 단순히 자료를 공유하기 위해서 운영체제의 IPC라는 복잡하고 비싼 메커니즘을 사용하고 있었다. 여기에서 이런 의문을 품은 사람들이 생겨난다. 왜 이렇게 멍청하게 하고 있지? 처음부터 모든 것을 자동으로 공유하도록 해준다면 어떨까? 이런 생각이 스레드라는 개념의 초기 발상이다. 많은 유닉스 운영체제는 이 개념의 생각대로 스레드를 특수한 형태의 프로세스로 처리한다. 실제로 리눅스의 경우에는 스레드라는 별도의 커널 객체를 두기 보다는 단순히 동일한 커널 구조체를 참조하는 특수한 프로세스로 구현했다.
하지만 Windows는 이러한 방식이 아닌 좀 다른 방식으로 스레드와 프로세스의 관계를 정리했다. 일단 기존의 스케줄링 단위를 프로세스에서 스레드로 바꾸어 버렸고, 프로세스는 스레드가 수행될 때 참조하는 컨테이너 역할로 만들어버렸다. 이렇게 만들어버리자 Windows에서는 스레드가 없는 프로세스란 아무런 의미가 없어졌다. 그래서 Windows에서 모든 스레드 종료란 프로세스의 종료를 의미한다.
다시 정리하면 이렇다. Windows 환경에서 프로세스란 실행 환경을 제공해주기 위한 컨테이너 역할을 한다. 여기에는 주소 공간과 접근 권한 같은 것들이 포함된다. 프로세스 자체로는 수행 가능한 객체가 아니며 내부에서 하나 이상의 스레드를 수행시킬 수 있는 환경에 불과하다. 스레드는 스케줄링의 기본 단위이며 하나의 실행 흐름을 나타낸다. 스레드는 수행되기 위해서는 해당 스레드가 수행될 프로세스 정보가 있어야 한다.
동기화
스레드가 이야기가 나오면 기본 안주로 함께 등장하는 메뉴가 동기화 문제다. 왜 그럴까? 그 답을 알기 위해서는 “동기화란 무엇인가?” 라는 질문에 대한 답을 먼저 찾아야 한다. 동기화란 바로 코드가 실행되는 순서를 정하는 일을 말한다. 어떤 코드를 먼저 실행할지 어떤 코드를 나중에 실행할지 순서를 정하는 일이다. “프로그램은 항상 프로그래머가 정해둔 순서대로 실행되는 것 아닌가요?”라는 의문을 가질 수 있다. 맞다. 프로그램은 항상 프로그래머가 정해둔 순서대로 실행된다. 하나만 실행될 때에는 말이다. 하지만 동시에 실행되기 시작하면 문제가 달라진다. 개별 실행 흐름들은 기존과 마찬가지로 순차적으로 수행되지만 그 흐름들이 섞이면 전혀 생각지도 못한 문제를 발생시킨다. 이를 방지하기 위해서 섞여서 실행되는 코드들 사이에 순서를 정하는 일이 필요해진 것이다. 그래서 동기화 문제란 항상 동시성과 같이 나올 수 밖에 없다.
동시성 vs 병렬성
비슷해 보이는 이 두 말은 큰 차이를 가지고 있다. 우선 동시성이란 우리에게 동시에 실행되는 것처럼 보이는 것들을 모두 나타내는 말이다. 따라서 단일 CPU 상에서 시분할 기법을 사용해서 여러 개의 프로그램을 수행하는 것도 동시성에는 포함된다. 반면 병렬성이란 복수의 CPU를 통해서 코드가 진짜 동시에 실행되는 상황을 나타낸다. 이런 의미에서 병렬성이란 물리적인 동시성을 나타낸다고 생각하면 되겠다.
<리스트 1>에는 동기화 문제를 보여주는 간단한 코드가 나와 있다. PinGame 함수는 핀을 서로 하나씩 가져가면서 마지막 핀을 가져가는 사람이 이기는 게임을 묘사한 코드다. 이제 이 함수가 스레드로 여러 개가 동시에 실행된다고 가정해보자. 그러면 개별 스레드는 이 하나의 코드를 순차적으로 실행하겠지만 운영체제 관점에서 보자면 이 코드들이 섞여서 동시에 실행되는 셈이 된다. 이렇게 동시에 실행되면 하나만 실행될 때에는 전혀 생각지도 못했던 문제가 발생하는데 이렇게 동시에 실행되면서 발생하는 문제를 동기화 문제라고 말한다.
우선 동기화 문제를 보다 효과적으로 설명하기 위해서 간단한 표현식을 정의하자. “(숫자)”는 숫자에 해당하는 스레드로 컨텍스트가 변경됐음을 나타낸다. a, b와 같은 기호는 코드 상의 주석에 나타나 있는 지점이 실행됐음을 의미한다. 따라서 “(1)ab”라는 것은 1번 스레드가 a, b라는 코드를 실행했음을 나타낸다. 마찬가지로 “(1)ab(2)a”라는 것은 1번 스레드가 a, b를 수행하고 2번 스레드로 컨텍스트 전환돼서 a라는 코드가 실행됐음을 나타낸다.
리스트 1 동기화 문제를 가진 코드
view plaincopy to clipboardprint?
int pin = 2;
void PrintWinner()
{
for(;;)
{ // ... a
if(pin == 1) // ... b
{
--pin; // ... c
printf("you win\n"); // ... d
break;
}
else
--pin; // ... e
}
}
자 그렇다면 앞서 정의한 표현식을 토대로 <리스트 1>의 코드에서 동기화 문제가 발생하는 흐름을 찾아보도록 하자. 바로 “(1)abea(2)ab(1)bcd(2)cd”가 그것이다. 문제는 결국 “you win”이라는 문자열이 화면에 두 번 출력된다는 것이다. 이런 코드들을 보여주고 여기까지 설명하면 대부분의 학생들은 <리스트 1>의 코드를 고침으로써 문제를 해결할 수 있다고 생각한다. 그리고는 거의 대부분 코드를 <리스트 2>와 같이 고친다.
리스트 2 동기화 문제를 가진 코드
view plaincopy to clipboardprint?
int pin = 2;
void PrintWinner()
{
for(;;)
{
if(pin <= 0)
break;
--pin; // … a
if(pin == 0) // … b
{
print("you win\n");
break;
}
}
}
그렇다면 과연 <리스트 2>의 코드는 문제가 없을까? 언뜻 보기에는 뭔가 좀 더 명확해 보여서 문제가 없어 보이지만 좀 깊이 생각해보면 <리스트 2>의 코드도 문제가 생기는 흐름을 찾아낼 수 있다. “(1)a(2)abc(1)bc”가 그것이다. 이 코드는 동기화 문제가 어디에서 비롯되는지 보다 명확하게 보여준다. 바로 값의 변경과 비교 사이에 발생하는 컨텍스트 전환이다. 이 말은 pin의 값 변경과 0과 비교하는 부분이 하나의 덩어리로 뭉쳐서 연산이 되지 않고서는 절대로 이 문제를 해결할 수 없다는 걸 의미한다.
여기까지 이야기하면 “if(--pin == 0)”과 같은 코드를 쓰면 된다고 생각하는 사람들이 있다. 하지만 “if(--pin == 0)”과 같은 표현식도 C언어 상으로는 한 줄로 표기되기 때문에 한번에 실행된다고 생각하기 쉽지만 컴파일러가 생성해낸 기계어는 <리스트 2>의 코드와 마찬가지로 여러 개의 기계어로 구성되어 있기 때문에 실행하는 사이에 컨텍스트 스위칭이 발생할 수 있고, 최종 프로그램에서는 동일한 문제가 발생한다.
이를 해결하기 위해서는 앞에서 우리가 내린 결론, 값의 변경과 비교가 한 덩어리가 되어서 실행되도록 만들어줄 어떤 도구가 필요하다. 이런 기능을 제공해주는 도구가 바로 운영체제에서 지원해주는 동기화 객체다. <리스트 3>에는 이러한 도구 중 하나인 크리티컬 섹션을 사용해서 문제를 해결한 코드가 나와있다.
리스트 3 크리티컬 섹션을 통한 동기화 문제 해결
view plaincopy to clipboardprint?
CRITICAL_SECTION cs;
EnterCriticalSection(&cs); // … a
--pin; // … b
if(pin == 0) // … c
{
LeaveCriticalSection(&cs); // … d
print("you win\n"); // … e
break;
}
LeaveCriticalSection(&cs); // … f
크리티컬 섹션은 해당 객체를 진입한 상태에서 다른 스레드가 다시 진입하지 못하도록 만드는 기능을 한다. “(1)a(2)”는 가능하지만 “(1)a(2)a”는 불가능하다는 말이다. “(1)a(2)(1)b(2)(1)c(2)”와 같이 1번 스레드가 a를 수행하고 나면 1번 스레드가 d를 수행하기 전까지 다른 스레드로의 컨텍스트 스위칭은 발생할 수 있지만 해당 스레드가 a를 수행 시키는 것은 불가능하다. 결국 실행 흐름의 입장에서는 중간 중간 잡음이 섞이긴 하지만 결과론적으로 b와 c가 항상 한번에 수행되는 것과 동일한 효과를 나타낸다.
그렇다면 운영체제는 어떻게 이런 것들을 만들 수 있었을까? 운영체제가 만든 코드라고 하더라도 결국 CPU 상에서 동작하기는 우리가 만든 코드와 다를 수 없기 때문이다. EnterCriticalSection 내부에서도 언제든지 컨텍스트 전환이 발생할 수 있지 않을까? 당연한 이야기다. 이 문제를 해결하기 위해서는 크게 두 가지 종류의 해법이 있다. 하나는 운영체제 스케줄러를 특수하게 만들어서 EnterCriticalSection과 같은 함수의 수행 도중에는 절대로 컨텍스트 전환이 발생하지 않도록 만드는 것이다. 다른 하나는 보다 낮은 단계에서 값의 변경과 비교를 한번에 수행하는 연산을 사용하는 것이다. x86/64 계열의 CPU에는 이러한 목적을 위해서 cmpxchg라는 명령어를 제공한다. 비교와 변경을 한번에 수행하는 명령어다. Windows는 결국에는 이러한 명령어를 사용해서 동기화 객체를 구현한다. 이런 맥락에서 우리가 처음에 만든 프로그램도 cmpxchg라는 명령어를 사용하도록 만든다면 동기화 객체를 사용하지 않고도 문제를 해결할 수 있다.
지금까지의 논의는 단일 CPU 상에서 동시에 실행되는 코드들에 대한 것이었다. 멀티코어가 되면 문제가 좀 더 복잡해진다. 멀티코어란 CPU가 두 개 이상인 시스템을 말한다. 이런 시스템에서는 진짜 동시 실행이 가능해진다. 이 말은 지금까지 논의했던 방식으로는 멀티코어 환경에서 문제를 해결할 수 없다는 것을 의미한다. 앞서 동기화 문제를 해결하는데 일등 공신이었던 cmpxchg라는 명령어를 생각해보자. n개의 CPU가 있다고 가정한다면 n개의 CPU에서 동시에 cmpxchg가 실행될 수 있다. 결국 문제를 해결하기 위해서는 cmpxchg라는 명령어가 n개의 CPU가 아닌 한번에 하나의 CPU에서만 실행될 수 있도록 만들어주는 메커니즘이 필요하다. x86/64 계열의 CPU에서는 lock이라는 접두어가 이런 역할을 한다. lock cmpxchg를 하면 해당 시점에는 한 녀석만 메모리에 접근하도록 만들어준다. 재미있는 사실은 동시성에서 비롯된 동기화 문제를 해결하기 위해서는 결국 동시에 실행되지 않는 무엇인가가 필요하다는 점이다.
컨텍스트, 컨텍스트, 또 컨텍스트
스레드 이야기에는 필연적으로 다양한 종류의 컨텍스트라는 말이 등장한다. 의미는 다른데 이를 표현하는 말은 모두 컨텍스트이기 때문에 처음 접하는 개발자는 상당히 혼란스러울 수 있다. 여기에서 잠깐 이런 컨텍스트라는 말의 정체에 대해서 알아보고 넘어가도록 하자. 컨텍스트를 우리 말로 번역하면 문맥이라는 말이 된다. 문맥이란 무엇인가? 우리가 일상생활에서 접하게 되는 문맥이라는 말의 의미는 다음과 같은 간단한 대화 속에서 쉽게 파악할 수 있다.
영희: 너 밥 먹었니?
철수: 응. 먹었어.
일반적으로 구두 표현은 상황을 통해 유추할 수 있는 정보는 대부분 삭제된다. 우리는 철수의 대답에는 포함되지 않았지만 상황을 통해 ‘먹었어’라는 말을 철수가 밥을 먹었다라는 사실로 자연스럽게 확장시킬 수 있다. 이렇게 유추의 근거를 제공하는 말이 놓인 상황을 우리는 문맥이라고 부른다. 프로그래밍에서 말하는 것 또한 이와 별반 다르지 않다. 일반적인 프로그래밍 환경에서 말하는 컨텍스트라는 말은 해당 코드가 바인딩되어 실행되는 환경을 일컫는다. 물론 이렇게 이야기를 하더라도 바인딩되어 실행되는 환경이라는 것이 무엇인지 감이 잡히지 않는다. 이를 좀 더 구체적으로 살펴보기 위해서 <리스트 4>의 코드를 살펴보자.
리스트 4 콜백 함수를 사용한 프로그램
view plaincopy to clipboardprint?
std::list GlobalList;
void Callback()
{
GlobalList.push_back(GetTickCount());
}
int main()
{
RegisterCallback(Callback);
for(;;)
{
if(!GlobalList.empty())
{
cout << GlobalList.front(); << endl;
GlobalList.pop_front();
}
}
return 0;
}
<리스트 4>의 코드에서 RegisterCallback 함수는 입력으로 들어간 콜백 함수가 랜덤 주기로 호출되도록 등록하는 함수다. 만약 RegisterCallback 함수 설명에 ‘입력으로 들어온 콜백 함수는 등록한 스레드 컨텍스트에서 호출된다’라는 말이 있다면 위 코드는 아무런 문제 없이 동작한다. 하지만 이와는 다르게 ‘입력으로 들어온 콜백 함수는 시스템 스레드 컨텍스트에서 호출된다’는 말이 있다면 위 코드는 잘못 동작한다. 이유는 Callback이 호출되는 스레드와 main이 실행되는 스레드가 다르기 때문이다. 서로 다른 스레드가 GlobalList를 동시에 접근함에도 동기화 처리가 되어 있지 않기 때문에 최악의 경우에는 프로그램 크래시가 발생한다. 이와 같이 Callback이라는 코드가 바인딩되어 실행되는 스레드를 우리는 컨텍스트라는 말로 표현한다.
여기서 더불어 살펴보아야 할 표현이 하나 있다. 바로 “임의의 스레드 컨텍스트”라는 표현이다. 대부분의 콜백 함수 설명에는 등록한 콜백 함수는 임의의 스레드 컨텍스트에서 호출된다라는 말이 있기 때문이다. 여기서 “임의의”라는 말은 정해지지 않았음을 나타내는 말이다. 그러니 “임의의 스레드 컨텍스트”라는 말은 달리 표현하면 “정해지지 않은 스레드 컨텍스트”가 된다. 그렇다면 도대체 정해지지 않은 스레드 컨텍스트라는 표현이 개발자에게 해주고 싶은 속내는 무엇이었을까? “정해지지 않았음”이 프로그래머에게 해주고 싶은 진짜 이야기는 이 말이다. “네 멋대로 특정 스레드 컨텍스트에서 호출된다고 생각하지 말아라. 이 코드는 네가 생각지도 못한 스레드 컨텍스트에서도 호출될 수 있다.”
“해당 콜백 함수는 임의의 스레드 컨텍스트에서 호출된다”는 문장을 보는 순간 여러분이 베스트 개발자라면 다음과 같은 생각을 반드시 해야 한다. “아, 이 함수가 실행되는 스레드는 정해지지 않았구나. 콜백 함수가 전역 데이터에 접근하는 경우에는 반드시 동기화 처리를 해줘야 하겠구나.” 반대로 “해당 콜백 함수는 콜백을 등록한 스레드와 같은 컨텍스트에서 호출된다”는 문장을 보게 되면 역으로 콜백과 등록한 스레드에서만 사용하는 공유 데이터가 있다면 동기화 처리를 생략해서 최적화 작업을 할 수 있겠다라는 생각을 하는 것이 정석이다.
지금까지 특정 함수가 수행되는 컨텍스트에 대해서 알아보았다. 이와 마찬가지로 특정 스레드도 해당 스레드가 수행되는 컨텍스트가 존재한다. 바로 프로세스다. 앞서 Windows에서 스레드의 개념을 설명할 때 특정 프로세스 내에서 수행되는 실행 흐름이라고 표현했다. 따라서 스레드가 동작하기 위해서는 반드시 어떤 프로세스 컨텍스트에서 동작할지를 알아야 한다는 말이다. 일반적으로 프로그램에서 생성하는 모든 스레드는 그 코드를 수행하는 스레드가 참조하는 프로세스 컨텍스트로 생성된다. 하지만 커널 모드 코드들의 경우에는 이 참조하는 프로세스 컨텍스트를 임의의 변경할 수 있다. 따라서 코드가 호출되는 스레드 컨텍스트와 마찬가지로 스레드가 수행되는 프로세스 컨텍스트도 변경될 수 있음을 알아야겠다.
초기 인터넷 세상에서는 웹 서버 라는 용어로 모든걸 통칭해 사용했지만, 시간이 지나면서 사용자에게 원활한 서비스를 제공하기 위해 기능적인 계층(Layer)를 나누게 되었습니다. 여기서 웹 서버와 웹 애플리케이션 서버와 차이가 생기게 됐다고 보면 됩니다. 그럼 웹 서버와 웹 애플리케이션 서버가 어떤 차이가 있는지 확인해보고, 실제로 각 서버를 이용해 웹 사이트를 구성하는지 알아보겠습니다.
웹 서버 (Web Server)란?
인터넷 상에서 웹 브라우저 클라이언트로부터 HTTP 요청을 받아들이고, HTML 문서와 같은 웹 페이지들을 보내주는 역할을 하는 프로그램입니다. 간단히 말하면 HTTP 요청에 따라 서버에 저장되어 있는 적절한 웹페이지를 클라이언트에게 전달하는 것입니다. 웹 페이지 뿐만 아니라 그림, 스타일 시트, 자바스크립트도 해당합니다.
주로 서버에 있는 리소스를 전달하는게 주된 기능이기도 하지만, 클라이언트로부터 콘텐츠를 받는 것도 웹 서버 기능에 포함합니다.
웹 서버에는 다음과 같은 종류가 있습니다.
제품명
제작사
최신 버전
라이선스
아파치
Apache 재단
2.4.4
오픈소스
IIS
마이크로소프트
8.0
상용(윈도우 서버 사용시 무료)
nginx
NGINX, Inc
1.5.1
오픈소스
GWS
구글
웹 애플리케이션 서버 (Web Application Server/WAS)란?
인터넷 상에서 HTTP를 통해 사용자 컴퓨터나 장치에 애플리케이션을 수행해 주는 미들웨어라고 합니다. 단순하게 WAS라고도 합니다. Servlet, ASP, JSP, PHP 등의 웹 언어로 작성된 웹 애플리케이션을 서버단에서 실행된 후 실행 결과값을 사용자에게 넘겨주게 되고, 우리가 가진 브라우져가 결과를 해석해서 화면에 표시하는 순으로 동작을 합니다.
웹 애플리케이션 서버는 다음과 같은 3가지 기본 기능을 가지고 있습니다.
- 프로그램 실행 환경과 데이터베이스 접속 기능을 제공(JDBC객체를 tomcat이 가지고 있다)
- 여러 개의 트랜잭션을 관리
+nginx처럼 보안의 기능. nginx가 외부에서 오는 (80번포트) 요청을 모두 받고,nginx을 바라보는 웹프로젝트 들에게 다시 포워딩 해주는 기능
+servlet이 내부적으로 가지고 있는 html로부터 신호를 받아 서버쪽으로 송신할 수 있는 request객체, 서버내부에서 서로 데이터를 주고받을 수있는 session객체그외 application객체, pageContext등등의 객체들처럼 등등 처럼 내부의 객체를 통해 서버가 업무를 처리하는 다양한 비즈니스 로직 수행하도록 함
그러나 웹 애플리케이션 서버의 명확한 정의가 존재하지 않아 일부 기능만 가진 웹 애플리케이션 서버도 있습니다. 웹 애플리케이션 서버는 다음과 같은 종류들이 있습니다. 들어본 것들도 있고, 처음 본 것들도 많이 있네요.
제품명
제작사
최신 버전
라이선스
제우스
한국티맥스소프트
7.C
상용
웹로직
미국오라클
10.3.6
상용
웹스피어
미국 IBM
7.C
상용
레진
미국 Caucho
4.0.7
상용
글래스피시
미국오라클
3.1.2.2
오픈소스(CDDL,GPL)
제이보스
미국레드햇
7.1.0.CR1b
오픈소스(LGPL)
인터스테이지
일본후지쯔
9.0.0
상용
아파치 톰캣
Apache 재단
7.0.41
오픈소스
레진(Resin)
Caucho
4.0
상용
제이런(Jrun)
Adobe
4.0
상용
Winstone Servlet Container
Rick Knowles
0.9.10
오픈소스
Jetty
Eclipse 프로젝트
3.0
오픈소스
웹 서버와 웹 어플리케이션 서버의 차이 및 구성
위에서 설명한 각 서버에서 보듯이 기능적인 차이로 구분을 지어 사용합니다. 웹 서버는 정적 데이터를 처리하는 용도로, 웹 애플리케이션 서버는 동적 데이터를 처리하는 용도로 말이지요. 하지만 톰캣의 경우처럼 웹 애플리케이션 서버에 웹 서버 기능을 포함된 서버 프로그램도 존재합니다. 간단히 집에서 웹서버 기능이나 웹 애플리케이션을 이용하고자 한다면 톰캣만 설치해도 됩니다. 반대로 웹 서버에서 내부에 애플리케이션을 동작할 수 있는 기능을 내장하기도 합니다. 간단한 웹 사이트를 구축한다면 웹 서버와 웹 애플리케이션 서버를 구분 지어 사용할 필요가 없습니다. 톰캣 하나만 설치하면 되니까요.
그럼 웹 서버와 웹 애플리케이션 서버를 어떻게 구성해 사용하는지 살펴 보겠습니다.
1. 스위치 - WAS
그림
웹 사이트의 가장 기본적인 구성 환경입니다. 모든 컨텐츠를 WAS에 모아 놓고, WAS가 웹서버와 웹 애플리케이션 서버 역할을 동시에 수행합니다. 트래픽이 많지 않고, 간단한 웹 사이트 서비스를 제공하거나, 개발 및 테스트 시스템 구성시 활용하기도 합니다.
스위치로 로드밸런싱을 하기 때문에 쉽게 다른 WAS를 설치하여, 부하를 분산 시킬 수 있는 장점이 있는 반면에, WAS가 웹서버와 웹 애플리케이션 서버 역할을 동시에 수행하기 때문에 각각의 기능이 다른 기능 수행시 부하를 발생 시킬 수 있기 때문에 성능 저하가 나타날 수 있는 단점을 가지고 있습니다.
2. 스위치 - 웹 서버 - WAS
그림
웹 서버와 WAS의 기능적 분류를 통해 효과적인 분산을 유도한 형태라고 합니다. 정적인 데이터는 웹 서버가, 동적인 데이터는 WAS가 담당하게 함으로써 간단한 1번 구조보다 더 나은 성능을 발휘 합니다.
3. (스위치 - 웹 서버 - WAS) + 이미지를 위한 웹 서버
그림
초고속 인터넷이 발달함에 따라 고화질의 이미지나 동영상을 제공하는 페이지가 증가하고 있습니다. 이러한 페이지는 네트워크 비중의 상당 부분을 차지합니다. 그래서 고화질 이미지나 동영상 데이터 제공을 위한 웹서버를 따로 추가하여, 기존 네트워크 비중도 줄이고, 기존의 웹 서버와 WAS를 좀 더 효율적으로 사용할 수 있도록 하는 구성입니다.
이러한 구조는 다양한 환경의 대한 네트워크 이슈를 좀 더 용이하게 대처할 수 있지만, 구조를 정확하게 이해하지 않았을 경우 개발 및 테스트에 많은 시간이 소요 됩니다.
4. 스위치 - 웹 서버 - WAS(프리젠테이션) - WAS(비즈니스)
그림
이 구조는 2번째 구조를 변경한 형태입니다. WAS단의 프로그램들이 많은 비중을 차지할 때, Presentation Logic을 담당하는 프로그램과 Business Logic을 담당하는 프로그램을 구분하여 각각의 WAS가 처리하도록 분리하는 형태입니다.
이러한 구조는 계층 구조의 부하를 적절히 분산할 수 있는 반면, 구조가 복잡해 유지보수가 어려워지는 단점을 가지고 있습니다.











 jhkim-140117-RegularExpression-09
jhkim-140117-RegularExpression-09
