그런데 코드블럭의 줄간격이 너무 넓은 경우가 있습니다. 스킨의 줄 간격 기본설정을 따라가기 때문인데 스킨편집의 css 탭에서 아래와 같이 추가합니다. 위치는 적당히 중간쯤 해 두세요. 나중에 찾기 쉽게 주석처리도 해 놓읍시다.
/* 코드 블럭 줄간격 */.hljs {
line-height: normal;
}
이제 영롱한 syntax highlighter를 갖게 되었습니다!
티스토리에서는 현재 10개의 언어만 지원하고 있지만, cdn을 통해 가져온 highlight.js는 기본 22개의 언어를 제공합니다. 고로 에디터의 마크다운이나 HTML 편집모드에서 클래스명만 맞춰준다면 티스토리에서 제공하지 않는 언어도 얼마든지 하이라이트할 수 있습니다.
다운로드 페이지에서 직접 필요한 언어를 골라 총 185개의 언어를 사용할 수도 있으니 확인해 보세요.
When an API request fails due to request errors or server errors, an error response message is returned in JSON format.
An error response message is returned in JSON format even for endpoints that support other MIME types. The error response message includes error message itself, a description of the error, a unique error code for the endpoint, an HTTP response message, and an HTTP response code.
The error response includes following fields:
message: the error message
details: a field for additional information, which may or may not be populated
description: description of the specific error
code: Unique error response code
http_response:
message: HTTP response message
code: HTTP response status code
For example, the following API request attempts to get information about a non-existent reference set that is called “test-set”
An HTTP404response code and the following JSON error response message are returned:
{ "message": "test_set does not exist", "details": {}, "description": "The reference set does not exist.", "code": 1002, "http_response": { "message": "We could not find the resource you requested.", "code": 404 } }
The following table provides more information about the HTTP response error categories returned by theIBM® Security QRadar®REST API:
어느 날 뜬금없이 대학교 친구에게 전화가 왔습니다. 그러더니 ‘야, REST API가 정확히 뭐 어떤 거야? 하는 질문에 가슴에 비수가 날아와 꽂힌 듯한 느낌을 받았습니다. 며칠 전 카톡으로 요즘 보통 웹서비스들은 ‘REST API형태로 서비스를 제공한다’고 아는 척을 조금 했던 기억이 머릿속을 빠르게 스쳐 지나갔고 그 순간 대충 얼버무리며 ‘아, 그거 REST하게 클라이언트랑 서버간에 데이터를 주고 받는 방식’을 말한다며 얼렁뚱땅 마무리 지었던 기억이 납니다. 실제로 REST API의 서비스를 직접 개발도 해보고 사용도 해봤는데도 막상 설명을 하자니 어려움을 겪었던 적이 있으셨을 텐데요. 그래서 이번에 REST API에 대해 정리하게 되었습니다. 기본적인 REST API에 대한 내용 외에도 REST API를 설계하실 때 참고해야 할 몇 가지 TIP들에 대해 공유해보도록 하겠습니다.
1. REST API의 탄생
REST는 Representational State Transfer라는 용어의 약자로서 2000년도에 로이 필딩 (Roy Fielding)의 박사학위 논문에서 최초로 소개되었습니다. 로이 필딩은 HTTP의 주요 저자 중 한 사람으로 그 당시 웹(HTTP) 설계의 우수성에 비해 제대로 사용되어지지 못하는 모습에 안타까워하며 웹의 장점을 최대한 활용할 수 있는 아키텍처로써 REST를 발표했다고 합니다.
2. REST 구성
쉽게 말해 REST API는 다음의 구성으로 이루어져있습니다. 자세한 내용은 밑에서 설명하도록 하겠습니다.
자원(RESOURCE) - URI
행위(Verb) - HTTP METHOD
표현(Representations)
3. REST 의 특징
1) Uniform (유니폼 인터페이스)
Uniform Interface는 URI로 지정한 리소스에 대한 조작을 통일되고 한정적인 인터페이스로 수행하는 아키텍처 스타일을 말합니다.
2) Stateless (무상태성)
REST는 무상태성 성격을 갖습니다. 다시 말해 작업을 위한 상태정보를 따로 저장하고 관리하지 않습니다. 세션 정보나 쿠키정보를 별도로 저장하고 관리하지 않기 때문에 API 서버는 들어오는 요청만을 단순히 처리하면 됩니다. 때문에 서비스의 자유도가 높아지고 서버에서 불필요한 정보를 관리하지 않음으로써 구현이 단순해집니다.
3) Cacheable (캐시 가능)
REST의 가장 큰 특징 중 하나는 HTTP라는 기존 웹표준을 그대로 사용하기 때문에, 웹에서 사용하는 기존 인프라를 그대로 활용이 가능합니다. 따라서 HTTP가 가진 캐싱 기능이 적용 가능합니다. HTTP 프로토콜 표준에서 사용하는 Last-Modified태그나 E-Tag를 이용하면 캐싱 구현이 가능합니다.
4) Self-descriptiveness (자체 표현 구조)
REST의 또 다른 큰 특징 중 하나는 REST API 메시지만 보고도 이를 쉽게 이해 할 수 있는 자체 표현 구조로 되어 있다는 것입니다.
5) Client - Server 구조
REST 서버는 API 제공, 클라이언트는 사용자 인증이나 컨텍스트(세션, 로그인 정보)등을 직접 관리하는 구조로 각각의 역할이 확실히 구분되기 때문에 클라이언트와 서버에서 개발해야 할 내용이 명확해지고 서로간 의존성이 줄어들게 됩니다.
6) 계층형 구조
REST 서버는 다중 계층으로 구성될 수 있으며 보안, 로드 밸런싱, 암호화 계층을 추가해 구조상의 유연성을 둘 수 있고 PROXY, 게이트웨이 같은 네트워크 기반의 중간매체를 사용할 수 있게 합니다.
4. REST API 디자인 가이드
REST API 설계 시 가장 중요한 항목은 다음의 2가지로 요약할 수 있습니다.
첫 번째, URI는 정보의 자원을 표현해야 한다. 두 번째, 자원에 대한 행위는 HTTP Method(GET, POST, PUT, DELETE)로 표현한다.
다른 것은 다 잊어도 위 내용은 꼭 기억하시길 바랍니다.
4-1. REST API 중심 규칙
1) URI는 정보의 자원을 표현해야 한다. (리소스명은 동사보다는 명사를 사용) GET /members/delete/1
위와 같은 방식은 REST를 제대로 적용하지 않은 URI입니다. URI는 자원을 표현하는데 중점을 두어야 합니다. delete와 같은 행위에 대한 표현이 들어가서는 안됩니다.
2) 자원에 대한 행위는 HTTP Method(GET, POST, PUT, DELETE 등)로 표현
위의 잘못 된 URI를 HTTP Method를 통해 수정해 보면
DELETE /members/1
으로 수정할 수 있겠습니다. 회원정보를 가져올 때는 GET, 회원 추가 시의 행위를 표현하고자 할 때는 POST METHOD를 사용하여 표현합니다.
회원정보를 가져오는 URI
GET /members/show/1 (x) GET /members/1 (o)
회원을 추가할 때
GET /members/insert/2 (x) - GET 메서드는 리소스 생성에 맞지 않습니다. POST /members/2 (o)
[참고]HTTP METHOD의 알맞은 역할 POST, GET, PUT, DELETE 이 4가지의 Method를 가지고 CRUD를 할 수 있습니다.
METHOD역할
POST
POST를 통해 해당 URI를 요청하면 리소스를 생성합니다.
GET
GET를 통해 해당 리소스를 조회합니다. 리소스를 조회하고 해당 도큐먼트에 대한 자세한 정보를 가져온다.
PUT
PUT를 통해 해당 리소스를 수정합니다.
DELETE
DELETE를 통해 리소스를 삭제합니다.
다음과 같은 식으로 URI는 자원을 표현하는 데에 집중하고 행위에 대한 정의는 HTTP METHOD를 통해 하는 것이 REST한 API를 설계하는 중심 규칙입니다.
URI에 포함되는 모든 글자는 리소스의 유일한 식별자로 사용되어야 하며 URI가 다르다는 것은 리소스가 다르다는 것이고, 역으로 리소스가 다르면 URI도 달라져야 합니다. REST API는 분명한 URI를 만들어 통신을 해야 하기 때문에 혼동을 주지 않도록 URI 경로의 마지막에는 슬래시(/)를 사용하지 않습니다.
REST API에서는 메시지 바디 내용의 포맷을 나타내기 위한 파일 확장자를 URI 안에 포함시키지 않습니다. Accept header를 사용하도록 합시다.
GET / members/soccer/345/photo HTTP/1.1 Host: restapi.example.com Accept: image/jpg
4-3. 리소스 간의 관계를 표현하는 방법
REST 리소스 간에는 연관 관계가 있을 수 있고, 이런 경우 다음과 같은 표현방법으로 사용합니다.
/리소스명/리소스 ID/관계가 있는 다른 리소스명 ex) GET : /users/{userid}/devices (일반적으로 소유 ‘has’의 관계를 표현할 때)
만약에 관계명이 복잡하다면 이를 서브 리소스에 명시적으로 표현하는 방법이 있습니다. 예를 들어 사용자가 ‘좋아하는’ 디바이스 목록을 표현해야 할 경우 다음과 같은 형태로 사용될 수 있습니다.
GET : /users/{userid}/likes/devices (관계명이 애매하거나 구체적 표현이 필요할 때)
4-4. 자원을 표현하는 Colllection과 Document
Collection과 Document에 대해 알면 URI 설계가 한 층 더 쉬워집니다. DOCUMENT는 단순히 문서로 이해해도 되고, 한 객체라고 이해하셔도 될 것 같습니다. 컬렉션은 문서들의 집합, 객체들의 집합이라고 생각하시면 이해하시는데 좀더 편하실 것 같습니다. 컬렉션과 도큐먼트는 모두 리소스라고 표현할 수 있으며 URI에 표현됩니다. 예를 살펴보도록 하겠습니다.
http:// restapi.example.com/sports/soccer
위 URI를 보시면 sports라는 컬렉션과 soccer라는 도큐먼트로 표현되고 있다고 생각하면 됩니다. 좀 더 예를 들어보자면
sports, players 컬렉션과 soccer, 13(13번인 선수)를 의미하는 도큐먼트로 URI가 이루어지게 됩니다. 여기서 중요한 점은 컬렉션은 복수로 사용하고 있다는 점입니다. 좀 더 직관적인 REST API를 위해서는 컬렉션과 도큐먼트를 사용할 때 단수 복수도 지켜준다면 좀 더 이해하기 쉬운 URI를 설계할 수 있습니다.
5. HTTP 응답 상태 코드
마지막으로 응답 상태코드를 간단히 살펴보도록 하겠습니다. 잘 설계된 REST API는 URI만 잘 설계된 것이 아닌 그 리소스에 대한 응답을 잘 내어주는 것까지 포함되어야 합니다. 정확한 응답의 상태코드만으로도 많은 정보를 전달할 수가 있기 때문에 응답의 상태코드 값을 명확히 돌려주는 것은 생각보다 중요한 일이 될 수도 있습니다. 혹시 200이나 4XX관련 특정 코드 정도만 사용하고 있다면 처리 상태에 대한 좀 더 명확한 상태코드 값을 사용할 수 있기를 권장하는 바입니다. 상태코드에 대해서는 몇 가지만 정리하도록 하겠습니다.
상태코드
200
클라이언트의 요청을 정상적으로 수행함
201
클라이언트가 어떠한 리소스 생성을 요청, 해당 리소스가 성공적으로 생성됨(POST를 통한 리소스 생성 작업 시)
상태코드
400
클라이언트의 요청이 부적절 할 경우 사용하는 응답 코드
401
클라이언트가 인증되지 않은 상태에서 보호된 리소스를 요청했을 때 사용하는 응답 코드
(로그인 하지 않은 유저가 로그인 했을 때, 요청 가능한 리소스를 요청했을 때)
403
유저 인증상태와 관계 없이 응답하고 싶지 않은 리소스를 클라이언트가 요청했을 때 사용하는 응답 코드
(403 보다는 400이나 404를 사용할 것을 권고. 403 자체가 리소스가 존재한다는 뜻이기 때문에)
405
클라이언트가 요청한 리소스에서는 사용 불가능한 Method를 이용했을 경우 사용하는 응답 코드
상태코드
301
클라이언트가 요청한 리소스에 대한 URI가 변경 되었을 때 사용하는 응답 코드
(응답 시 Location header에 변경된 URI를 적어 줘야 합니다.)
500
서버에 문제가 있을 경우 사용하는 응답 코드
글을 마치며
RESTFul한 API를 설계하실 때 도움이 될만한 내용들을 제 나름의 우선순위를 가지고 정리해 보았습니다. 정리를 하면서 다시 한 번 느낀 것은 정확히 알지 못하면 '설명할 수 없다'는 것입니다. 누군가가 그런 말을 하였습니다. '당신이 어떤 것을 할머니에게 설명해 주지 못한다면, 그것은 진정으로 이해한 것이 아니다.' 저 문구를 항상 가슴 깊이 새기고 앞으로 무엇인가 새로운 지식을 학습해 실무에 적용할 때에도 '대충'이 아닌 '정확한 이해'를 바탕으로 문제를 해결해 나가도록 해야겠다는 다짐과 함께 글을 마무리 짓도록 하겠습니다. 마지막으로 REST API는 정해진 명확한 표준이 없기 때문에 REST API를 사용함에 있어 '무엇이 옳고 그른지'가 아닌 개발하는 서비스의 특징과 개발 집단의 환경과 성향 등이 충분히 고려되어 설계되어야 할 것입니다.
부족한 내용이나 잘못된 내용이 있다면 댓글 부탁 드립니다. 긴 글 읽어주셔서 감사합니다.
Reference
마크 메세 (2015), 일관성 있는 웹 서비스 인터페이스 설계를 위한 REST API 디자인 규칙 (김관래, 권원상 역), 한빛미디어
구글은 생각보다 많은 기능을 가진 검색엔진이다. 이제까지 구글 검색을 잘 활용해 왔다고 생각하는 사람들 중 구글의 기능을 다 꿰고 있는 사람은 많지 않을 것이다.
허핑턴포스트가 세계에서 가장 유명한 검색 엔진을 효율적으로 활용하는 방법을 소개한다. 단 몇 개의 키만 입력하면 누구보다 빠르고 쉽게 구글링을 할 수 있다.
"Define"을 앞에 붙여라
상황: 단어 게임을 하는데, 어떤 바보가 "야, '파나케이아(panacea: 만병통치약)라는 단어는 없어!"라고 말한다.
해결방법: 찾으려고 하는 단어 앞에 "define"을 붙여라. 그러면 곧장 사전적 정의가 뜬다.
정확한 순서의 단어를 찾아라
상황: 인용문을 하나 찾으려는데, 원래 문장이 뭔지 모르겠다면?
해결방법: 찾으려는 문장에 직접 인용부호 " " 를 붙이면 쉽게 검색이 된다.
마크 트웨인의 명언이 정확히 기억나지 않는다면? 따옴표를 붙여라!
연관 단어를 찾아라
상황: '대체 에너지(alternative energy)'에 대해 검색하고싶은데, '재생에너지(renewable energy)'와 같은 수많은 동의어도 함께 찾고 싶다.
해결방법:검색어 앞에 ~ 를 붙여라. 연관된 문서들을 찾을 수 있다.
특정 단어를 배제하라
상황: '효모(yeast)'라는 단어가 들어가지 않은 제빵 방법(bread recipes)을 검색하고 싶다.
해결방법: 검색할 단어(bread recipes)를 입력한 다음, 배제하고 검색할 단어(yeast) 앞에 마이너스 표시 (-)를 붙인다.
특정 가격 범위 내에서 찾아라
상황: 특정 가격 범위에 속하는 디지털 카메라를 찾고 싶다
해결방법: 검색어를 입력한 후 최저 가격과 최고 가격 사이에 마침표를 두 개(..) 찍는다. 날짜 범위를 설정해 검색할 때도 똑같은 방법이 적용된다. 특정 날짜 대에 발행된 기사를 찾을 때 유용하다.
특정 웹사이트의 컨텐츠를 찾아라
상황: 허핑턴포스트에서 넬슨 만델라에 대한 재밌는 기사를 읽었다. 그런데 기사를 쓴 사람이나 제목이 기억나지 않는다.
해결방법: "site:" 뒤에 찾고자 하는 웹사이트의 주소를 넣은 다음 검색어를 입력한다. 허핑턴 포스트에서 넬슨 만델라의 기사를 찾고 싶다면 "stie:huffingtonpost.com nelson mandela"를, 허핑턴포스트코리아에서 브라질 월드컵에 대한 기사를 찾고 싶다면 "site:huffingtonpost.kr 브라질 월드컵"을 검색창에 치면 된다.
빈칸을 채워라
상황: 예전에 팝락스(Pop Rocks)라는 입에서 톡톡 튀기는 캔디와 '무엇'을 섞으면 '어떻게 된다'는 말을 들은 거 같은데, 기억이 안 난다.
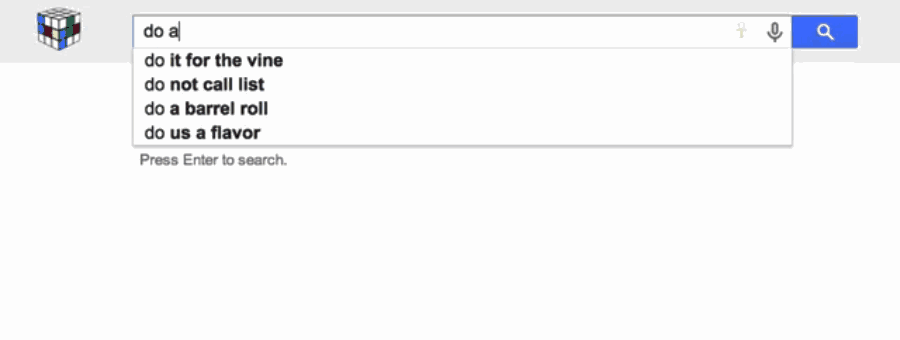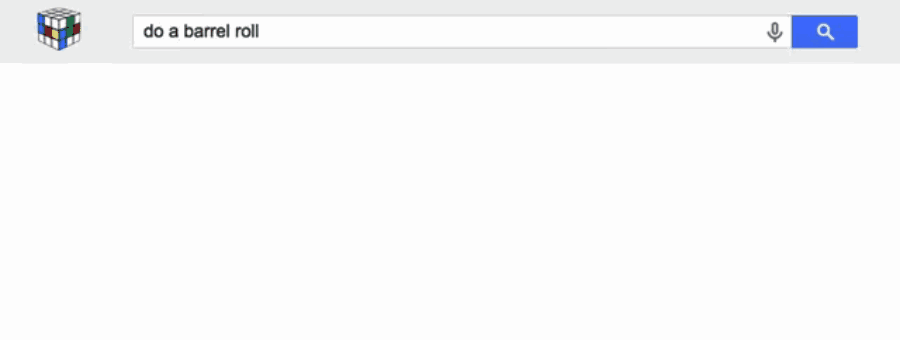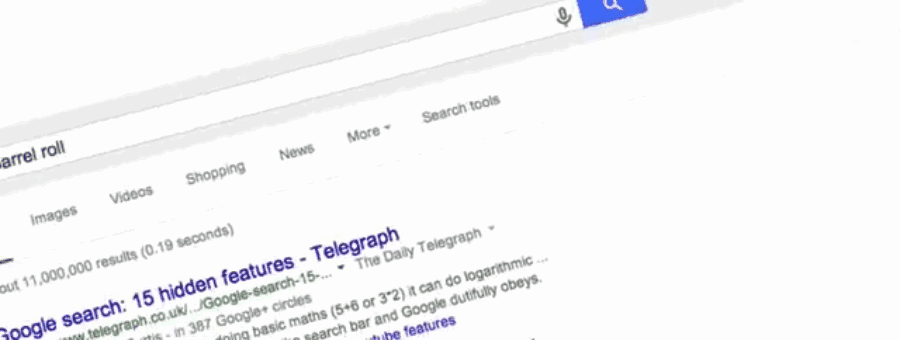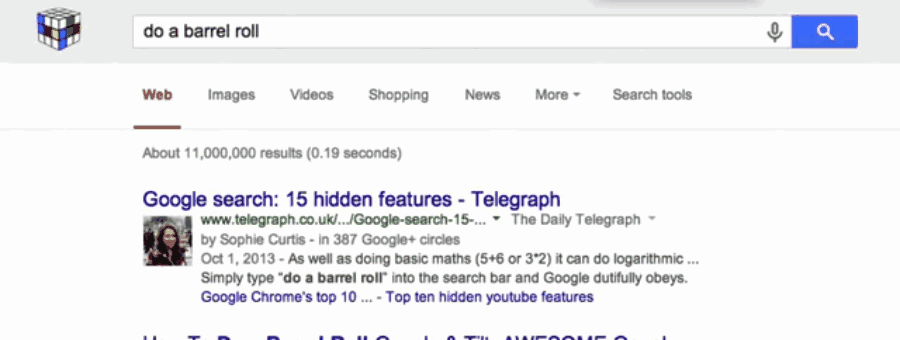
해결방법: 모르겠는 부분에 별표(*)를 대신 넣어라. 구글이 가능성있는 단어를 찾아줄 거다. (한글도 똑같이, "콜라에 *를 넣으면"으로 검색할 수 있다.)
특정 파일 형태를 찾아라
상황: 1920년대 미국 슬랭(속어)에 관한 PPT(파워포인트 프레젠테이션) 파일을 찾고 싶다.
해결방법: 검색어 뒤에 "filetype: PPT"를 붙인다. (한글도 똑같이, "지방선거 filetype:PPT" 이렇게 검색할 수 있다. txt, ai, psd 등도 가능하다)
타이머를 설정해라
상황: 머리도 좀 식힐 겸 유튜브에서 동영상을 보며 놀고 싶다. 하지만 정신 못 차리고 계속 빠져있긴 싫다.
해결방법: "set timer for"을 검색창에 치면 구글 타이머가 뜬다. 원하는 시간을 시, 분, 초 단위로 설정할 수 있다. 시간이 다 되면 "삐삐삐" 알람 소리가 난다.
수학 기능을 써라
상황: 수학실력이 젬병이거나, 혹은 꽤 잘하지만 복잡한 계산을 해야 한다면?
해결방법: 검색창에 방정식을 입력하면 구글이 알아서 계산해준다. 예를 들어 3200의 30%를 알고 싶다면? "30% of 3200"을 치면 된다.
환전 기능을 써라
상황: 태국에 여행갈 일이 있는데 달러로, 혹은 원화로 얼마 가져가야 하는지 모르겠다.
해결방법: "현재 가지고 있는 화폐", "to", "바꿀 화폐"를 차례로 입력한다. 예를 들어 원화를 바트로 바꾸려면 "wons to baht"를 입력하면 된다.
해결방법: "intitle:" 다음에 "졸업앨범(yearbook)"을 입력하고 "조 바이든(Joe Biden)"을 더한다. 그러면 "졸업앨범"이 제목으로 들어간 조 바이든의 사진을 우선으로 찾아준다. 또 다른 예로, '타코 만들기'를 검색하고 싶다면 "intitle: 타코 만들기"를 입력하라. "intitle:" 명령어는 바로 뒤에 온 단어만 인식한다. 그래서 제목에 "타코", 내용에 "만들기"가 들어간 문서를 찾아준다. "타코" "만들기" 두 단어가 모두 들어간 제목을 찾고자 할 땐 "allintitle:"을 쓰면 된다.
라우터(router):호스트에서 생성된 데이터를 여러 네트워크를 거쳐 전송함으로써 서로 다른 네트워크에 속한 호스트 간에 데이터를 교환할 수 있게 하는 장비
호스트와 라우터, 라우터와 라우터 그리고호스트와 호스트가 통신하려면 정해진 절차와 방법을 따라야 하는데 이를통신 프로토콜이라고 부릅니다.
인터넷에서 사용하는 핵심 프로토콜은 TCP와 IP로, 이를 비롯한 각종 프로토콜을 총칭하여 TCP/IP 프로토콜이라고 부릅니다. 통신을 수행하는 주체이자 통신의 최종 목적지는 호스트 자체가 아닌 호스트에서 수행하는 응용프로그램입니다.
응용 프로그램끼리 통신시 요구사항의 예
통신할 대상을 지정하는 상호 약속된 방법
전송 오류 확인 기능
오류 발생 시 재전송 기능
데이터의 순서 관계 유지
이와 같은 기능은 프로토콜 수준에서 자동으로 제공됩니다. 따라서 응용 프로그래머는 다양한 프로토콜의 특성을 이해하고, 필요한 기능에 적합한 프로토콜을 선택할 수 있어야 합니다. 일반적으로 프로토콜은 기능별로 나누어 계층적으로 구현하는데, TCP/IP 프로토콜도 이 구조를 따릅니다.
TCP/IP 프로토콜 구조
- 네트워크 접근 계층:물리적 네트워크를 통한 실제 데이터 송수신 담당. 물리 주소 사용.
- 인터넷 계층:큰 인터-네트워크를 구성하려면 물리 주소와 무관한 단일 주소 지정방식이 필요한데, IP 주소가 이런 요구 사항을 만족합니다. IP 주소의 유일성과 하드웨어 독립성 덕분에 TCP/IP 프로토콜은 다양한 네트워크 기술과 하드웨어에서 작동할 수 있으며, 이를 통해 전 세계적인 네트워크인 인터넷(Internet)을 만들 수 있게 되었습니다. 네트워**크 접근 계층의 도움을 받아 데이터를 목적지 호스트까지 전달(라우팅), IP 주소 사용**
- 전송 계층: 최종 통신 목적지를 지정하고 오류없이 데이터를 전송하는 역할. 포트번호 사용
- 응용 계층:전송 계층을 기반으로 한 다수의 프로토콜과 응용 프로그램을 포괄
IP주소는 통신에 참여하는 호스트를 유힐하게 지정하는 방법을 제공하지만, 실제 통신을 하려면 전송경로를 결정하고 그에 따라 데이터를 전달하는 절차가 필요한데 이를 라우팅이라고 부릅니다. 라우팅은 데이터를 목적지까지 전달하는 일련의 작업을 가리키는 용어로, 라우팅에 필요한 정보를 수집하는 작업과 라우팅 정보를 기초로 실제 데이터를 전달하는 작업을 포함합니다.
인터넷 계층의 IP가 제공하는 전송 서비스는 최선을 다하지만(best-effort) 신뢰성은 없다는 특징이 있습니다. 즉, 데이터에 문제가 생기면 목적지ㅏ에 도달하지 못하는 상황이 발생할 수 있고, 목적지에 도달해도 실제 데이터의 내용이 손상됐을 가능성도 있습니다. 전송 계층에서는 이러한 데이터 손실 또는 손상을 검출해 잘못된 데이터가 목적지에 전달되는 일을 방지합니다.
TCP의 특징
- 연결형(connection-oriented) 프로토콜: 연결 설정 후 통신 가능
- 신뢰성 있는 데이터 전송: 데이터를 재전송
- 일대일 통신(unicast)
- 데이터 경계 구분 안함: 바이트 스트림(byte-stream) 서비스
UDP의 특징
- 비연결형(connectionless) 프로토콜: 연결 설정 없이 통신 가능
- 신뢰성 없는 데이터 전송: 데이터를 재전송하지 않음
- 일대일 통신(unicast), 일대다 통신(broadcast, multicast)
- 데이터 경계 구분: 데이터그램(datagram) 서비스
응용 계층은 전송계층을 기반으로 한 다수의 프로토콜과 이 프로토콜을 사용하는 응용프로그램을 포괄합니다. 소켓을 사용한 네트워크 프로그램도 여기에 속합니다.
데이터 전송 원리
송신 측 호스트의 응용 프로그램이 보내는 데이ㅏ터를 수신 측 호스트의 응용 프로그램에 전송하려면 각 프로토콜에서 정의한 제어정보(IP 주소, 포트 번호, 오류 체크 코드 등)가 필요합니다. 제어 정보는 위치에 따라앞쪽에 붙는 헤더(header)와뒤쪽에 붙은 트레일러(trailer)로 나뉩니다. 데이터는 이러한 제어 정보가 결합된 형태로 전송되며, 이를 패킷(packet)이라고 부릅니다.즉, 패킷은 [제어정보 + 데이터]로 정의할 수 있습니다.
송신 측 응응용 프로그램에서 보낸 데이ㅏ터는 TCP/IP/이더넷 계층을 지나면서 헤더 또는 트레일러 형태의 제어 정보가 덧붙어서 패킷이 생성됩니다. 이 패킷이 수신 측에 도달하면 이더넷/IP/TCP 계층을 지나면서 헤더 또는 트레일러 형태의 제어 정보가 제거되고 최종적으로 수신 측 응용 프로그램이 데이터를 받게 됩니다.응용 프로그래머는 주고받을 데이터에만 집중하여 구현하고, 나머지는 운영체제가 제공하는 프로토콜이 처리하도록 맡기면 됩니다.
인터넷 계층은 호스트와 라우터에 모두 존재하며, IP 주소와 라우팅 기능을 이용해 패킷 전송 경로를 결정합니다. 실제 패킷 전송에는 네트워크 접근 계층이 제공하는 물리 주소를 사용하는데, 이런 물리 주소는 패킷이 라우터를 통과할 때마다 다음 지점의 물리 주소로 계속 변경됩니다.
IP 주소:인터넷에 존재하는 호스트를 유일하게 식별, 32비트(IPv4) 또는 128비트(IPv6) 주소를 사용.
포트 번호:통신의 종착점(하나 혹은 여러 프로세스)을 식별, 부호 없는 16비트 정수 사용.
루프백 주소:시스템 자신을 나타내는 의미로 내무적으로만 사용, IPv4 (127.0.0.1) IPv6(0:0:0:0:0:0:0:1)
네트워크 프로그램은 일반적으로 클라이언트-서버 모델로 작성합니다.클라이언트-서버 모델을 한 컴퓨터에서 실행되는 두 프로그램에 적용할 경우에는 다양한 프로세스 간 통신(IPC, Inter-Process Communication) 기법을 사용해 데이터를 주고 받을 수 있습니다.반면, 네트워크로 연결된 컴퓨터에서 실행되는 두 프로그램에 적용할 경우에는 반드시 통신 프로토콜을 사용해야만 데이터를 주고받을 수 있습니다.
서로 다른 호스트에서 실행되는 두 프로그램이 상호 접속하는 경우를 가정해보면, 접속이 성공하려면 반드시 상대 프로그램이 실행 중이어야 합니다. 그러나 이와 같이 동시 접속 모델을 사용하면 타이밍 문제 때문에 접속이 실패할 확률이 높아지고, 결과적으로 통신할 수 없는 경우가 자주 발생하게됩니다.
반면, 클라이언트-서버 모델에서는 이와 같은 문제가 자연스럽게 해결됩니다. 한 프로세스가 먼저 실행하여 대기하고, 다른 프로세스가 나중에 실행하여 접속하면 됩니다. 클라이언트가 서버에 접속하려면 서버의 IP 주소와 포트 번호를 알고 있어야 합니다.반면, 서버는 클라이언트의 주소를 미리 알 필요가 없습니다. 클라이언트가 보낸 패킷에는 클라이언트의 주소 정보가 모두 들어 있기 때문에, 서버는 이 정보를 이용해 언제든지 해당 클라이언트에 데이터를 보낼 수 있습니다.













































{kind=link}