TCP/IP 프로토콜 구조
인터넷을 통해 통신을 수행하는 개체는 크게 호스트와 라우터로 나눌 수 있습니다.

호스트(host): 최종 사용자(end-user) 응용 프로그램을 수행하는 주체
라우터(router):호스트에서 생성된 데이터를 여러 네트워크를 거쳐 전송함으로써 서로 다른 네트워크에 속한 호스트 간에 데이터를 교환할 수 있게 하는 장비

호스트와 라우터, 라우터와 라우터 그리고호스트와 호스트가 통신하려면 정해진 절차와 방법을 따라야 하는데 이를통신 프로토콜이라고 부릅니다.
인터넷에서 사용하는 핵심 프로토콜은 TCP와 IP로, 이를 비롯한 각종 프로토콜을 총칭하여 TCP/IP 프로토콜이라고 부릅니다. 통신을 수행하는 주체이자 통신의 최종 목적지는 호스트 자체가 아닌 호스트에서 수행하는 응용프로그램입니다.
응용 프로그램끼리 통신시 요구사항의 예
통신할 대상을 지정하는 상호 약속된 방법
전송 오류 확인 기능
오류 발생 시 재전송 기능
데이터의 순서 관계 유지
이와 같은 기능은 프로토콜 수준에서 자동으로 제공됩니다. 따라서 응용 프로그래머는 다양한 프로토콜의 특성을 이해하고, 필요한 기능에 적합한 프로토콜을 선택할 수 있어야 합니다. 일반적으로 프로토콜은 기능별로 나누어 계층적으로 구현하는데, TCP/IP 프로토콜도 이 구조를 따릅니다.
TCP/IP 프로토콜 구조
- 네트워크 접근 계층:물리적 네트워크를 통한 실제 데이터 송수신 담당. 물리 주소 사용.
- 인터넷 계층:큰 인터-네트워크를 구성하려면 물리 주소와 무관한 단일 주소 지정방식이 필요한데, IP 주소가 이런 요구 사항을 만족합니다. IP 주소의 유일성과 하드웨어 독립성 덕분에 TCP/IP 프로토콜은 다양한 네트워크 기술과 하드웨어에서 작동할 수 있으며, 이를 통해 전 세계적인 네트워크인 인터넷(Internet)을 만들 수 있게 되었습니다. 네트워**크 접근 계층의 도움을 받아 데이터를 목적지 호스트까지 전달(라우팅), IP 주소 사용**
- 전송 계층: 최종 통신 목적지를 지정하고 오류없이 데이터를 전송하는 역할. 포트번호 사용
- 응용 계층:전송 계층을 기반으로 한 다수의 프로토콜과 응용 프로그램을 포괄
IP주소는 통신에 참여하는 호스트를 유힐하게 지정하는 방법을 제공하지만, 실제 통신을 하려면 전송경로를 결정하고 그에 따라 데이터를 전달하는 절차가 필요한데 이를 라우팅이라고 부릅니다. 라우팅은 데이터를 목적지까지 전달하는 일련의 작업을 가리키는 용어로, 라우팅에 필요한 정보를 수집하는 작업과 라우팅 정보를 기초로 실제 데이터를 전달하는 작업을 포함합니다.
인터넷 계층의 IP가 제공하는 전송 서비스는 최선을 다하지만(best-effort) 신뢰성은 없다는 특징이 있습니다. 즉, 데이터에 문제가 생기면 목적지ㅏ에 도달하지 못하는 상황이 발생할 수 있고, 목적지에 도달해도 실제 데이터의 내용이 손상됐을 가능성도 있습니다. 전송 계층에서는 이러한 데이터 손실 또는 손상을 검출해 잘못된 데이터가 목적지에 전달되는 일을 방지합니다.
TCP의 특징
- 연결형(connection-oriented) 프로토콜: 연결 설정 후 통신 가능
- 신뢰성 있는 데이터 전송: 데이터를 재전송
- 일대일 통신(unicast)
- 데이터 경계 구분 안함: 바이트 스트림(byte-stream) 서비스
UDP의 특징
- 비연결형(connectionless) 프로토콜: 연결 설정 없이 통신 가능
- 신뢰성 없는 데이터 전송: 데이터를 재전송하지 않음
- 일대일 통신(unicast), 일대다 통신(broadcast, multicast)
- 데이터 경계 구분: 데이터그램(datagram) 서비스
응용 계층은 전송계층을 기반으로 한 다수의 프로토콜과 이 프로토콜을 사용하는 응용프로그램을 포괄합니다. 소켓을 사용한 네트워크 프로그램도 여기에 속합니다.
데이터 전송 원리
송신 측 호스트의 응용 프로그램이 보내는 데이ㅏ터를 수신 측 호스트의 응용 프로그램에 전송하려면 각 프로토콜에서 정의한 제어정보(IP 주소, 포트 번호, 오류 체크 코드 등)가 필요합니다. 제어 정보는 위치에 따라앞쪽에 붙는 헤더(header)와뒤쪽에 붙은 트레일러(trailer)로 나뉩니다. 데이터는 이러한 제어 정보가 결합된 형태로 전송되며, 이를 패킷(packet)이라고 부릅니다.즉, 패킷은 [제어정보 + 데이터]로 정의할 수 있습니다.
송신 측 응응용 프로그램에서 보낸 데이ㅏ터는 TCP/IP/이더넷 계층을 지나면서 헤더 또는 트레일러 형태의 제어 정보가 덧붙어서 패킷이 생성됩니다. 이 패킷이 수신 측에 도달하면 이더넷/IP/TCP 계층을 지나면서 헤더 또는 트레일러 형태의 제어 정보가 제거되고 최종적으로 수신 측 응용 프로그램이 데이터를 받게 됩니다.응용 프로그래머는 주고받을 데이터에만 집중하여 구현하고, 나머지는 운영체제가 제공하는 프로토콜이 처리하도록 맡기면 됩니다.

인터넷 계층은 호스트와 라우터에 모두 존재하며, IP 주소와 라우팅 기능을 이용해 패킷 전송 경로를 결정합니다. 실제 패킷 전송에는 네트워크 접근 계층이 제공하는 물리 주소를 사용하는데, 이런 물리 주소는 패킷이 라우터를 통과할 때마다 다음 지점의 물리 주소로 계속 변경됩니다.
IP 주소:인터넷에 존재하는 호스트를 유일하게 식별, 32비트(IPv4) 또는 128비트(IPv6) 주소를 사용.
포트 번호:통신의 종착점(하나 혹은 여러 프로세스)을 식별, 부호 없는 16비트 정수 사용.
루프백 주소:시스템 자신을 나타내는 의미로 내무적으로만 사용, IPv4 (127.0.0.1) IPv6(0:0:0:0:0:0:0:1)
포트번호를 관리하는 공식 사이트(http://www.iana.org/assignments/port-number) 참고.
클라이언트-서버 모델
네트워크 프로그램은 일반적으로 클라이언트-서버 모델로 작성합니다.클라이언트-서버 모델을 한 컴퓨터에서 실행되는 두 프로그램에 적용할 경우에는 다양한 프로세스 간 통신(IPC, Inter-Process Communication) 기법을 사용해 데이터를 주고 받을 수 있습니다.반면, 네트워크로 연결된 컴퓨터에서 실행되는 두 프로그램에 적용할 경우에는 반드시 통신 프로토콜을 사용해야만 데이터를 주고받을 수 있습니다.
서로 다른 호스트에서 실행되는 두 프로그램이 상호 접속하는 경우를 가정해보면, 접속이 성공하려면 반드시 상대 프로그램이 실행 중이어야 합니다. 그러나 이와 같이 동시 접속 모델을 사용하면 타이밍 문제 때문에 접속이 실패할 확률이 높아지고, 결과적으로 통신할 수 없는 경우가 자주 발생하게됩니다.
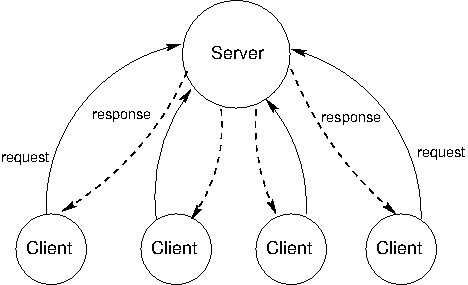
반면, 클라이언트-서버 모델에서는 이와 같은 문제가 자연스럽게 해결됩니다. 한 프로세스가 먼저 실행하여 대기하고, 다른 프로세스가 나중에 실행하여 접속하면 됩니다. 클라이언트가 서버에 접속하려면 서버의 IP 주소와 포트 번호를 알고 있어야 합니다.반면, 서버는 클라이언트의 주소를 미리 알 필요가 없습니다. 클라이언트가 보낸 패킷에는 클라이언트의 주소 정보가 모두 들어 있기 때문에, 서버는 이 정보를 이용해 언제든지 해당 클라이언트에 데이터를 보낼 수 있습니다.
- 출처:https://12bme.tistory.com/61[길은 가면, 뒤에 있다.]
'C Lang > 버리기는 아까운 IT잡지식' 카테고리의 다른 글
| REST API 제대로 알고 사용하기 (0) | 2019.06.07 |
|---|---|
| 구글링의 고수가 되는 검색 트릭 14 (1) | 2019.06.06 |
| tcp프로토콜과 udp프로토콜 (0) | 2019.06.04 |
| tcp/ip프로토콜의 전반적인 흐름 설명 (0) | 2019.06.04 |
| base64 란 뭘까? (0) | 2019.01.21 |