서버리스(Serverless)를 직역하자면, “서버가 없다” 라는 의미가 있습니다. 하지만, 사실상 서버가 없는건 아닙니다. 그저, 특정 작업을 수행하기 위해서 컴퓨터를 혹은 가상머신에 서버를 설정하고, 이를 통하여 처리 하는 것이 아님을 의미합니다.
그 대신에,BaaS (Backend as a Service)혹은FaaS (Function as a Service)에 의존하여 작업을 처리하게 됩니다. BaaS 를 제공하는 서비스 중에선, Firebase, Parse (지금은 서비스종료 됨), Kinvey 등이 있고, FaaS 를 제공하는 서비스 중에선, AWS Lambda, Azure Functions, Google Cloud Functions 등이 있습니다.
앞으로 작성 될 튜토리얼은 주로 FaaS 에 대하여 다뤄보게 될 것이며, 이번 포스트에서는 FaaS 는 기존의 기술들과 어떠한 차별성이 있는지 다뤄보겠습니다.
기존의 기술들
자체적 시스템 설계
시스템에서 필요한 모든 인프라를 직접 관리하는 것을 의미합니다.전산실이라는 키워드를 생각하시면 이해하기 쉬울 것입니다. 공간, 하드웨어, 네트워크, 운영체제, 모두 직접 관리를 해주는 거죠. 이 방식에서의 가장 큰 문제점은 시스템이 엄청 커지면 전산실을 유지 할 관리자가 필요 할 것이고, 이 인력에 대한 비용이 나간다는 점입니다.
IaaS (Infrastructure as a Service)
그리고, AWS, Azure 등의 서비스가 만들어지기 시작했죠. 더 이상 서버자원, 네트워크, 전력 등의 인프라를 모두 직접 구축 할 필요 없어졌습니다. 이러한 인프라를 가상화하여 관리하기 쉽게 해주는 서비스 서비스를 통하여, 관리자패널에서 인프라를 구성하고, 사용하면 되죠. 사용자는 가상머신을 만들고, 네트워크를 설정하고, 하드웨어도 설정하고, 거기에 운영체제를 설치해서 애플리케이션을 구동 할 수 있습니다. 사용량을 쉽게 모니터링 할 수 있습니다.
PaaS (Platform as a Service)
IaaS 에서 한번 더 추상화된 모델이라고 생각하시면 됩니다. 네트워크, 그리고 런타임까지 제공이됩니다. 사용자는 이제 애플리케이션만 배포하면 바로 구동시킬 수 있습니다. 대표적으로 AWS Elastic Beanstalk, Azure App Services 등이 있습니다. 이를 사용하면 Auto Scaling 및 Load Balancing 도 손쉽게 적용 할 수 있습니다.
Serverless! – BaaS 와 FaaS
Serverless, 즉 서버가 없다는 의미입니다. 이는 BaaS 와 FaaS, 이렇게 두가지로 나뉘어질 수있는데요, 서버가 없다는건, 그냥 표현일 뿐, 사실 작업을 처리하는 서버는 존재하긴 합니다. 다만, “서버의 존재”에 대해서 신경쓰지 않아도 됩니다. 서버가 어떤 사양으로 돌아가고있는지, 서버의 갯수를 늘려야 할지, 네트워크는 어떤걸 사용할지, 이런걸 설정할 필요가 없습니다.
BaaS (Backend as a Service)
보통, 우리가 모바일 혹은 웹 애플리케이션을 만들게 될 때, 백엔드 서버개발을 진행하게 됩니다. 엄청 단순하게 생각하자면, 계산기, 혹은 그림판 수준으로 프론트엔드 쪽 코드로만 충분히 이뤄질 수 있다면, 백엔드 서버를 만들 필요가 없겠죠. 하지만, 데이터를 저장하고, 다른 기기에서도 접근하고, 공유하기 위해서는, 백엔드 개발은 필수적입니다.
서버 개발을 하다보면, 고려할 사항이 꽤 많죠. 유저가 늘어나게 된다면 서버의 확장도 고려해야 하고, 보안성 또한 고려해야 하죠. 그래서 탄생한 서비스가, Firebase 같은 BaaS 입니다. 이 시스템에서는, 앱 개발에 있어서 필요한 다양한 기능들 (데이터베이스, 소셜서비스 연동, 파일시스템 등)을 API로 제공해 줌으로서, 개발자들이 서버 개발을 하지 않고서도 필요한 기능을 쉽고 빠르게 구현 할 수 있게 해주고, 비용은 사용 한 만큼 나가게 되죠. 서버의 이용자가 순식간에 늘어나게 되어도, 따로 대비를 안해주어도 알아서 확장이 됩니다.
현존하는 BaaS 중 가장 대중화 되어있는것은 Firebase 이기 때문에, 이 포스트에선 Firebase 를 사용한다는 가정하에 장점과 단점들을 나열해보도록 하겠습니다.
BaaS를 사용함에 있어서, 가장 큰 장점은 개발 시간의 단축 (회사 입장으로서 생각한다면, 인건비), 서버 확장 작업의 불필요함입니다. 백엔드에 대해서 지식이 별로 없더라도, 아주 빠른 속도로 개발이 가능합니다. 특히, Firebase 에서는 실시간 데이터베이스를 사용하여 데이터가 새로 생성되거나, 수정되었을 때 소켓을 사용하여 클라이언트에게 바로 반영시켜주는 기능이 있는데요, 이러한 기능은 직접 개발하게 된다면 구조 설정에 꽤 많은 시간이 필요 할 수도 있는데 이를 단지 코드 몇줄만으로 구현 할 수 있게 해주는 멋진 기능들을 지니고 있습니다. 추가적으로, 일정 사용량 만큼 무료로 사용 할 수 있기 때문에 토이 프로젝트, 소규모 프로젝트의 경우 백엔드로서 매우 유용하게 사용 할 수 있습니다.
하지만, 무조건 장점만 있는것은 아닙니다. BaaS를 사용함으로서, 발생하는 대표적인 단점으로는 다음과 같은것들이 있습니다.
1. 클라이언트 위주의 코드
이 부분은 어떻게 관리하냐에 따라 다르긴 하겠지만, BaaS 를 사용함으로서, 백엔드 로직들이 클라이언트쪽에 구현이 됩니다. 예를들어 이메일 발송, 결제 처리 등의 작업들을 클라이언트에서 수행하고 싶지는 않겠죠?
Firebase 의 경우에는 서버쪽에서도 사용이 가능하긴 합니다. Firebase SDK 를 불러와서 사용하는거죠. 일부 로직을 직접 서버측에서 구현할 바에, 그냥 모든 로직을 직접 구현하는건 어떨까요?
추가적으로, 데이터단의 로직이 변경되면… 클라이언트 코드의 수정이 이뤄지게됩니다. 그러면, 재배포를 해야되겠죠? 웹어플리케이션이라면 JS 를 새로 받아야하는데, 이건 별로 큰 일은 아니지만, 모바일 앱이라면, 앱 업데이트를 해야합니다. 그리고 상황에 따라서 구버전 사용자를 강제 업데이트해야 하는일이 발생 할 수도 있겠죠.
2.가격
Firebase 의 경우엔 초반엔 무료입니다. 이는 소규모 프로젝트에는 정말 매력적으로 다가 올 수 있는 장점인데요, 하지만 앱의 규모가 커지면, 가격이 꽤 비쌉니다. 실시간 데이터베이스에 10G 가 쌓이고, 한달 전송되는 데이터의 양이 20G 정도면 데이터베이스 비용으로만 $70 가 발생합니다.
참고로 클라우드 컴퓨팅 호스팅을 해주는 서비스 Vultr 의 가격대를 보면, $10 면 40GB SSD, 2000GB 월 대역폭을 사용 할 수 있습니다.
따라서, 사용자가 별로 없을 것 같은 서비스면 Firebase 는 정말 좋은 선택입니다. 하지만, 서비스의 규모가 커질수록 직접 구현을 했을 때 대비 지출되는 비용이 늘어날 것입니다.
3. 복잡한 쿼리가 불가능함
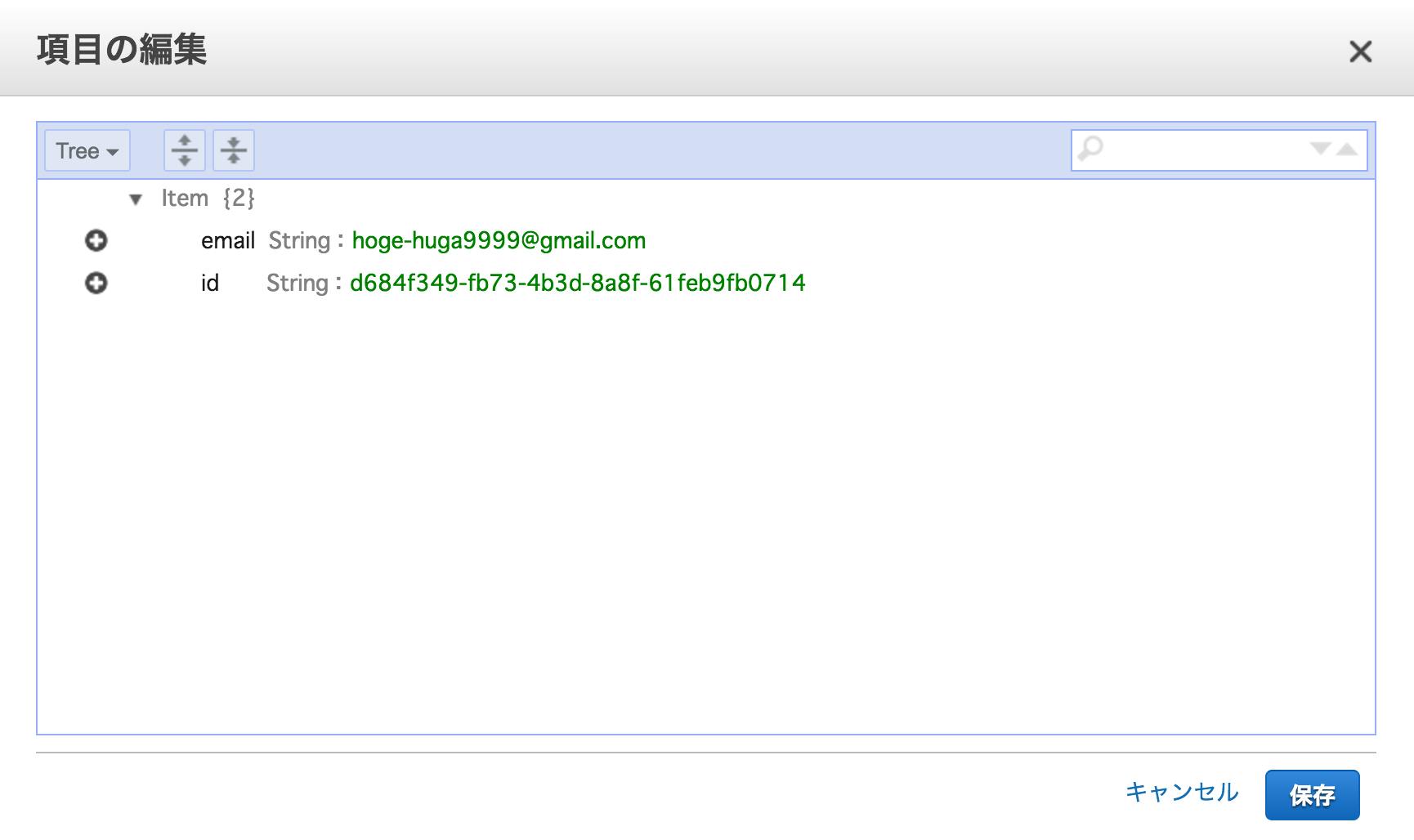
Firebase 는 데이터베이스가 하나의 큰 JSON 객체로 구조화 되어있습니다. RDBMS 의 테이블, 관계 같은 개념이 존재하지 않기 때문에 최대한 데이터베이스 모델을 비정규화 하여 사용하는 것이 좋습니다. 예를들어서 게시글을 조회한다고 가정해봅시다.
Firebase 를 통하여 다음과 같은 작업은 할 수 있습니다
2018년 1월 1일 ~1월 31일 사이에 작성된 글 조회
velopert 가 작성한 글 조회
그런데 이런건 못합니다.
velopert 가 1월 1일 이후에 작성한 글 조회
그래서, 이러한 작업을 하려면 모델링을 할 때 다음과 같이 username_date 라는 필드를 만들어야 합니다.
그렇게 하고 나서, username_date 를 가지고 쿼리를 해야합니다. 불가능한건 아닌데… 이렇게 까지 해야하나 싶죠. 저는 맘에 안듭니다.
저의 경우엔 Firebase 를 사용하여 특정 유저를 팔로우하고, 팔로우한 유저의 글을 모아보는 기능을 구현하다가 Firebase 만으로는 해결 할 수 없는 한계를 느껴 때려치고 백엔드 개발을 처음부터 다시 한 경험이 있습니다.
정리
정리를 하자면, Firebase 는 어떠한 개발자들은 매우 강력한 도구로서 사용 하는 반면에, 저를 비롯한 어떠한 개발자들은 Firebase 의 구조를 불편해하고, 한계를 느끼는 사람들도 있습니다. 그리고 분명히, 그러한 한계는 이런저런 꼼수를 사용하여 극복할 수 있다고 생각하지만, 굳이 그렇게해야하나 싶습니다.
실시간 데이터베이스가 정말로 필요한 서비스라면, 일부 기능에서 Firebase 를 사용하는것은 정말 좋은 선택일 수도 있습니다. 비용이 비싸질 수도 있지만 그러한 기능을 구현하기 위해서 들어가는 많은 개발 공수가 절약 될 수도 있습니다. 참고로, 실시간 기능을 최소 공수로 구현하고 싶다면Feather.js라는 것도 있으니 참고해보시길 바랍니다! (아, 물론 이건 서버가 필요합니다.)
FaaS (Function as a Service)
FaaS 는 프로젝트를 여러개의 함수로 쪼개서 (혹은 한개의 함수로 만들어서), 매우 거대하고 분산된 컴퓨팅 자원에 여러분이 준비해둔 함수를 등록하고, 이 함수들이 실행되는 횟수 (그리고 실행된 시간) 만큼 비용을 내는 방식을 말합니다.
우리가 등록한 함수는 특정 이벤트가 발생했을때 실행됩니다.
주기적으로 실행되게끔 설정 할 수 있습니다. 5분마다, 1시간마다, 하루마다 이런식으로 말이죠. 크롤링 작업, 주기적 처리를 할 때 좋습니다.
웹 요청을 처리 할 수도 있습니다. 예를 들어서 특정 URL 로 들어오면 어떠한 작업을 하게끔 할 수 있죠. 이를 통하여 백엔드 API 를 구성 할 수도 있습니다.
콘솔을 통하여 직접 호출 할 수도 있습니다.
PaaS 와의 주요 차이점
서버 시스템에 대해서 신경쓰지 않아도 된다는 점이 PaaS 와 유사하기도 한데요, 가장 중요한 차이점은, PaaS 의 경우엔, 전체 애플리케이션을 배포하며, 일단 어떠한 서버에서 당신의 애플리케이션이 24시간동안 계속 돌아가고 있다는 점 입니다.
반면 FaaS 는, 애플리케이션이 아닌 함수를 배포하며, 계속 실행되고 있는 것이 아닌, 특정 이벤트가 발생 했을 때 실행되며, 실행이 되었다가 작업을 마치면 (혹은 최대 타임아웃 시간을 지나면) 종료됩니다.
장점
비용: 특정 작업을 하기 위하여 서버를 준비하고 하루종일 켜놓는것이 아니라, 필요할때만 함수가 호출되어 처리되며 함수가 호출된 만큼만 비용이 드므로, 비용이 많이 절약됩니다.
인프라 관리: 네트워크, 장비 이런것들에 대한 구성 작업을 신경 쓸 필요 없습니다.
인프라 보안: 리눅스 업데이트, 최근 발생한 Intel Meltdown 취약점 보안패치, 이런것들 또한 신경 쓸 필요 없습니다.
확장성: FaaS 는 확장성 면에서 매우 뛰어납니다. 일반적으로, FaaS 를 사용하지 않는다면, 다양한 트래픽에 유연한 대응을 하기 위하여 우리는 AWS 의 Auto Scaling 같은 기술을 사용합니다. 이를 통하여 CPU 사용량, 네트워크 처리량에 따라 서버의 갯수를 늘리는 방식으로 처리를 분산시키는데요, FaaS 를 사용하게 되면 이렇게 특정 조건에 따라 자동으로 확장되는 것이 아닙니다. 그냥, 확장됩니다. 함수가 1초에 1개가 호출되면 1개가 호출되는것이고, 100,000,00 개가 호출되면 100,000,00 개가 호출되는것입니다. 그리고 호출된 횟수 만큼 돈을 내는거죠.
단점
제한: 모든 코드를 함수로 쪼개서 작업하다보니, 함수에서 사용 할 수 있는 자원에 제한이 있습니다. 하나의 함수가 한번 호출 될 때, AWS 에서는 최대 1500MB 의 메모리까지 사용 가능하며, 처리시간은 최대 300 초 까지 사용 가능합니다. 때문에, 웹소켓 같이 계속 켜놔야 하는것은 사용하지 못합니다. 그 대신에, AWS IoT, Pusher 등의 서비스를 사용하면 됩니다.
FaaS 제공사에 강한 의존: AWS, Azure, Google 등의 FaaS 제공사에 강한 의존을 하게 됩니다. 즉, 갑자기 이 회사들이 망해버리면…? 정말 골치 아프겠죠. 물론 가능성은 매우 희박합니다.
로컬 데이터 사용 불가능: 함수들은 무상태적(stateless)입니다. 때문에, 데이터를 로컬 스토리지에서 읽고 쓸 수 없습니다. 그 대신에, AWS 라면 S3, Azure 라면 Storage 를 이용 할 수 있습니다.
비교적 신기술: FaaS 는 비교적 새로운 기술 입니다. 물론 AWS 에서 Lambda 는 2014년에 등장하긴 했지만요, 주관적으로 보기엔, 2016년쯤 사용률이 올라가기 시작했으며, 이제 기업에서 사용한 사례들도 여럿 등장하며 자리를 잡아가고 있습니다. 2018년, 아직까지는, 해외에서는 관련 자료들을 볼 수 있는 반면, 국내에서는 관련 자료를 찾아보기가 힘듭니다. 아마 2020년 쯤에는 조금 더 국내에서도 관련 자료를 많이 찾아 볼 수 있을 것이라 예상합니다.
Use case
그렇다면, FaaS 는 어떤 용도로 사용 될 수 있을까요? 다음 예제들을 살펴보면 감이 잡힐 것입니다.
Backend: 서비스의 백엔드를 FaaS 로 구현 할 수 있습니다.
Crawler: 주기적으로 페이지를 긁어서 수집 할 수 있습니다.
파일 처리: 파일을 업로드하고, 화질/사이즈를 조정하고, S3 같은 스토리지에 저장하는 기능을 구현 할 수 있습니다.
로그 분석 / 실시간 모니터링: 예를 들어, 특정 컴퓨팅 자원이 CPU 사용량이 70% 에 도달 했을 때, Slack 등을 통하여 알림을 받고 싶다면 AWS 의 Cloudwatch/CloudTrail 과 연동하여 알림을 받을 수 있습니다.
자동화 작업들: Netflix 의 경우엔, 동영상이 됐을 때, 인코딩하고, 검증하고, 태깅하고, 공개하는 작업들을 Lambda 를 통하여 자동화 시켰습니다. 그리고 또, 백업 관련 작업도 Lambda 로 처리했다고 합니다.
수많은 것들을 할 수 있습니다!
FaaS 를 어떻게 배워야 할까?
아직까지는, 국내에 자료가 많지 않아서 공부하기가 힘들 수 도 있습니다. 하지만 걱정하지 마세요! 저를 따라오시면 됩니다.:D 우리는 앞으로, Hello World 부터 시작해서, 프로덕션에서도 사용 할 수 있을정도로 학습을 해보도록 하겠습니다.
Amazon Kinesis Data Analytics コンピュータやAmazon Kinesis Data Streams、Amazon Kinesis Data Firehoseから送信されてくるデータをSQLを使って処理できるサービス。
今回はこのうちのAmazon Kinesis Data Streamsについて詳しく説明します。
2 Amazon Kinesis Data Streamsとは
最近、IOTが発達してセンサを通じて大量のデータを収集することができるようになってきました。この収集されたデータは一度保存され、解析してその後のマーケティング等に活かされますが、この収集したデータを保存する部分は一見簡単そうに見えますが、送られてくるデータが膨大なのでそれらを制御するためにはハードウェアの性能面で考えることが多く、実は非常に難しいらしいです。 これを解決してくれるのがAmazon Kinesis Data Streamsです。 Amazon Kinesis Data Streamsはセンサ等のコンピュータかから送られてくるデータを別のサービスまで届けるためのサービスです。
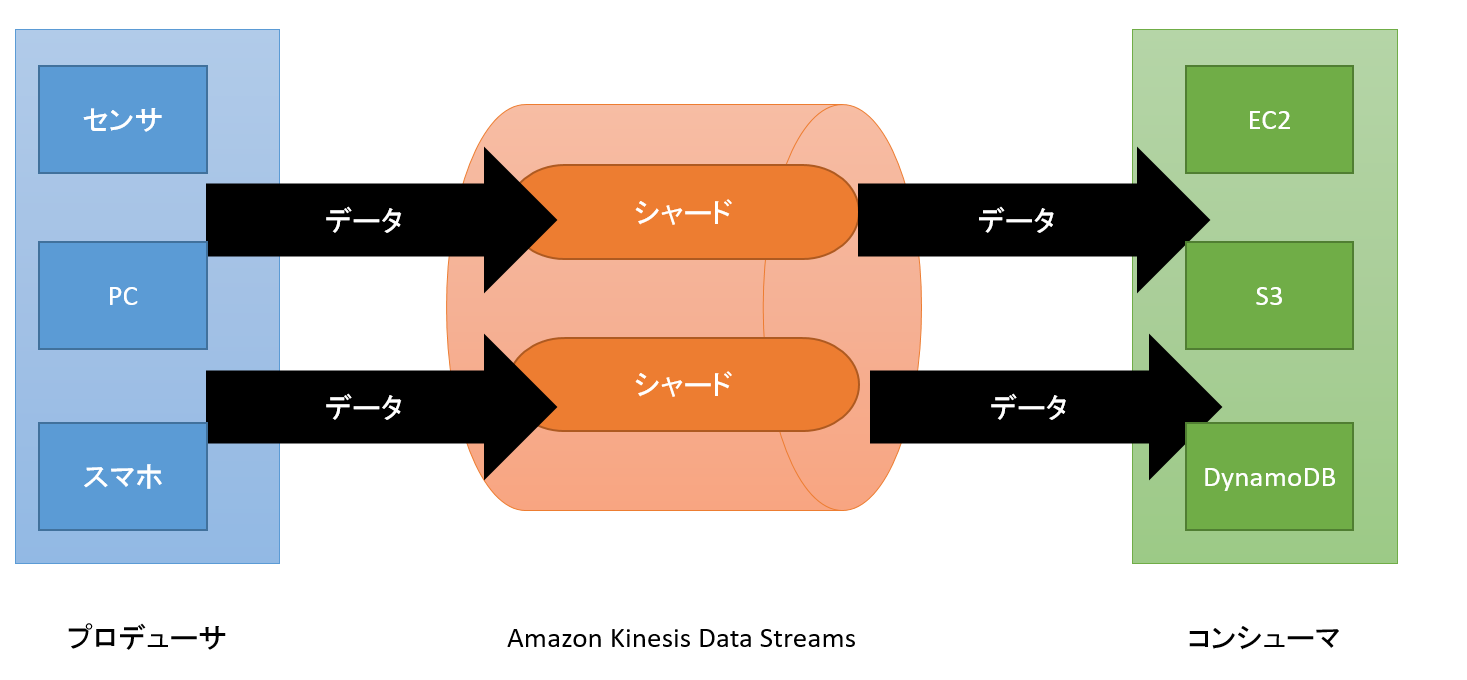
下の図はAmazon Kinesis Data Streamsの処理の流れを記載したものです。
プロデューサ Amazon Kinesis Data Streamsにデータを送信するもの。 センサやPC,スマホ等が該当すします。
Amazon Kinesis Data Streams プロデューサからデータを受け取って管理し、コンシューマへ受け渡すもの。 シャードと呼ばれるもので構成されます。
コンシューマ Amazon Kinesis Data Streamsへデータを受け取るリクエストを送信してデータを取得し、処理を行う。
Amazon Kinesis Data Streamsに送信されたデータはすべてパーティションキーによってシャードに割り当てられ、シーケンス番号が振られます。そしてコンシューマからのリクエストに応じてシャードに入っているデータをコンシューマに送信します。(パーティションキーとかシャードとかイメージがつかない場合、下記にあるCLIコードを見ること!)