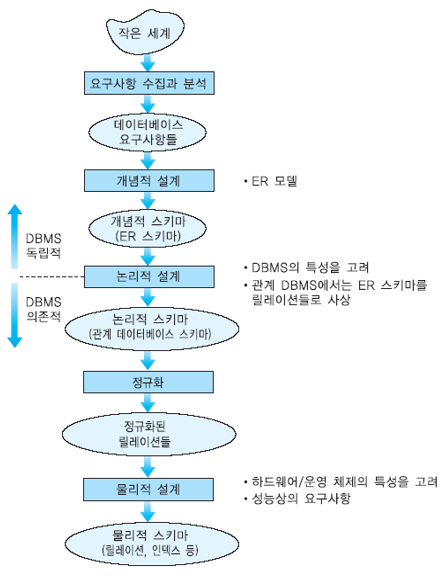
・개념적설계는 뭐하는 거냐면여~
-수집한 요구사항을 분석해 엔티티와 관계를 추출
-엔티티와 어트리뷰트들, 관계에 속한 어트리뷰트인지를 분류
-최종적으로 er다이어그램을 그리는 것
・개념적 설계 방식
-bottom up 상향식:최소단위의 정보들을 상위개념의 정보 그룹으로
-top down 하향식 : 상위 그룹의 내용을 쪼개 하위그룹으로 나아가는 것
-주로 하향식 방법을 사용함
-그 이유는 전체의 큰그림을 그린 후 작은단위로 나아가기 때문에 넓게보기 좋음
-상향식 방법은 최소단위가 빠질 것을 우려해 보안책으로 사용함
・개념적 설계 플로우
데이터베이스 요구사항 ->엔티티 추출(약한, 강한 엔티티타입 설정) -> 관계설정 -> 카디날리티 설정 -> 애트리부트 설정(키 애트리뷰트 설정, 의도된 애트리뷰트 설정, 다치 애트리뷰트 설정) -> er다이어그램
・K대학교의 데이터베이스 요구사항
<학생관리>
학번,이름주소,생년월일 등 개인정보를 관리, 그리고 학생은 하나의 전공학과에 속해야하며 , 한분의 지도교수 밑에서 전공지도를 받는다. 매 학기마다 강의를 신청하여 수업을 듣는다.
<과목관리>
교내에 개설된 과먹에 대한 정보를 관리한다(과목번호, 과목명, 과목개요) 그리고 각 과목은 여러개의 섹션으로 나누어서 관리한다. 단 섹션이 존재하지 않는 과목이 존재할 수도 있다.
<교수관리>
교수의 이름, 전공분야, 보유기술 등의 정보를 관리. 특히 보유기술은 여러가지가 있을 수 있음.그리고 교수는 관련 과목을 강의하고 지도학생을 보유한다.
<학과관리>
학과의 학과명, 사무실 위치, 전화번호 등의 정보를 관리한다. 그리고 각 학과의 교수들 중 학과장을 임명한다. 학과장은 임명날자가 있다.
<수강신청>
학생들은 과목을 수강하기 위해 등록을 한다.
・1.엔티티 추출하기
-엔티티 : 실체가 명확히 존재하는 것, 각 엔티티는 독립적으로 고유식별이 가능해야함(사람 vs 물건 과 같이, 미시가 잘되어야함)
-1.명사 정제하기 : 디비 요구사항으로부터 얻어낸 명사들중 엔티티라고 생각되는 명사를 추출, 구분보통 문장에서 명사가 엔티티인 경우가 많더라.. 이 명사들을 구분지어 엔티티 생성
-엔티티 네이밍 센스 : 중복x, 너무 길지않은, 의미없는 수식어x
-2.명사 그룹짓기 : 대표하는 명사로 그룹의 이름을 붙이고, 다른 그룹에 속하는 단어를 옮기기,
다른 그룹과 연관된 명사 제거(전공학과, 수강과목, 지도교수, 지도학생, 학과장 제거)
-3.엔티티 정의내리기
-4.엔티티 표기하기




학생:학번 이름 주소 생일 전공 과목 교수
과목:과목번호 과목명 과목개요 섹션
교수:이름 전공분야 보유기술 지도학생
학과:학과면 사무실위치 전화번호 학과장
・2.관계설정하기
-관계 : 문장속에서 주로 동사인 경우가 많음.
엔티티 간의 관계를 설명하는 동사나 이벤트를 나타내는 동사를 찾음
<그림설명>
-섹션이라는 엔티티는 독립적으로 존재할 수 없고, 과목이 존재해야만 존재할 수 있는 엔티티 이다
따라서 약한 엔티티타입이라고 할 수 있다(이중마름모)
-1,2,3,4,5는 문장으로된 요구사항이다. 각 문장의 명사인 주어 목적어와 동사를 구분하면 엔티티타입과 관계를 구분할 수 있다.

・3.카디날리티 설정
-커디날리티 설정: 한 엔티티타입의 어트리뷰트(그림에서 점)이 한 개의 선만을 가지면 1 여러개의 선을 가지면 n





-하나의 학과는 하나의 교수에게 학과장 당하고, 하나의 교수는 하나의 학과의 학과장한다.
-학생은 여러개의 한 학생은 하나의 학과만을 전공하지만, 한 학과는 여러명의 학생으로 부터 전공당한다.
-한 교수는 여러 과목을 강의하지만, 여러과목은 한 교수에게 강의된다.
-한 학생은 한명의 교수에게 전공지도 받지만, 한 교수는 여러명의 학생을 전공지도한다.
-여러명의 학생은 여러과목을 수강신청하고, 여러과목은 여러학생에게 수강신청 당한다.
・4.키어트리뷰트 설정
-엔티티마다 서로 다른 값을 가지는 고유한 어트리뷰트로 각각 유일한 값을 가져 식별이 가능한 값
-키어트리뷰트의 기준
-어트리뷰트 값이 변하지 않아야한다
-반드시 값을 갖고 있어야한다.
-한 엔티티 타입내에 복수의 키어트리뷰트가 존재할 수 있다.(학생 엔티티타입 내에 학번, 주민번호)
-키어트리뷰트를 설정 후 ,개념적 설계도에서 밑줄을 긋는다!
<개념적 설계 그림설명>
-한 교수가 보유한 보유기술은 여러개가 존재할 수 있으므로 다치 어트리뷰트
-나이는 생년월일을 통해 계산되므로 유도된 어트리뷰트

・5.관계타입 어트리뷰트 정의
-관계타입 어트리뷰트:관계 타입도 엔티티아비과 유사하게 어트리뷰트를 지닐 수 있다.


'DataBase > DataModeling' 카테고리의 다른 글
| [데이터모델링]개념적인 설계에서 논리적인 설계로 나아가기 (0) | 2017.12.28 |
|---|---|
| [데이터모델링]ER모델링 (0) | 2017.12.27 |
| [데이터모델링]요구사항 분석 (0) | 2017.12.26 |
| [데이터모델링]ER데이터 모델(엔티티와 엔티티타입, 애트리뷰트, 관계) (0) | 2017.12.26 |
| [데이터모델링]데이터베이스 설계 과정(라이프 사이클) (0) | 2017.12.26 |































![[그림 6-2-7] IE표기법을 기준으로 작성한 논리 데이터 모델 예](http://www.dbguide.net/publishing/img/dbguide/edu/060614_edu_02.gif)


