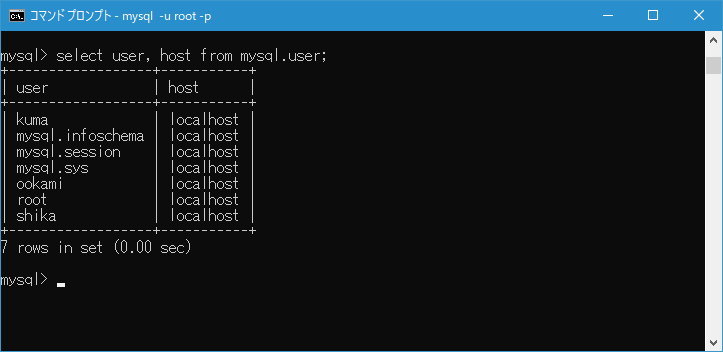
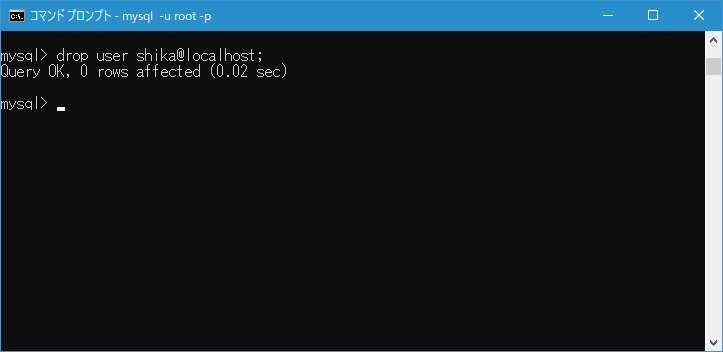
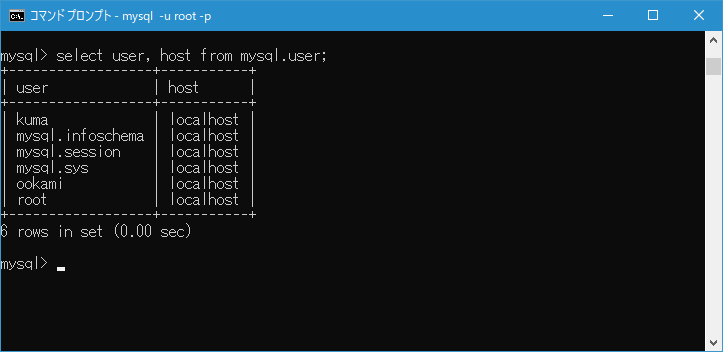
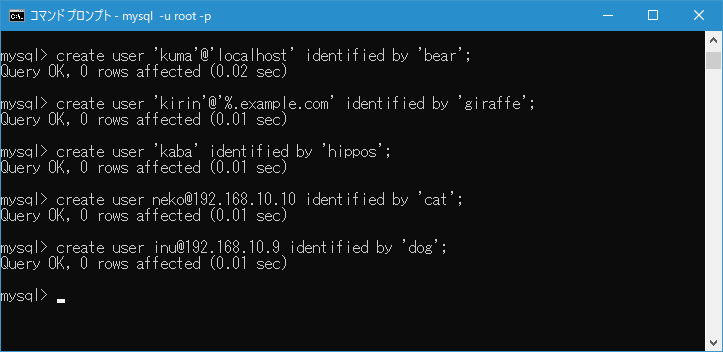
엔지니어로 근무하고 반드시 직면하는 고민. 그것은 "어떤 관계형 데이터베이스 (이하 RDB)를 선택하는 것이 최선인가?"입니다.
RDB마다 장점과 단점이 다릅니다. 따라서 자사 서비스에 일치하지 RDB를 선택해 버리면 그것이 병목이 개발 · 운용에 문제가 생기는 경우가 적지 않습니다.
그 중에서도 자주 비교 검토되는 것이 PostgreSQL과 MySQL. 모두 오픈 소스 RDB의 사실상의 표준이며, 높은 성능과 다양한 기능을 가지고 있습니다.
양자는 구체적으로 어떤 장단점이있는 것입니까? 그것을 철저 해부하기 위해, PostgreSQL 전문가 인 사와다: 마사히코 씨와 MySQL 전문가 인 다나카: 날개 씨의 대담을 실시. 각 기능마다 특징을 비교했습니다.
RDB에 대해 일본 최고 수준의 지식을 가진 2 명의 의견. 꼭 PostgreSQL과 MySQL을 선정 할 때 참고하세요!
사와다: 마사히코 (사와다: · 마사히코) @sawada\_masahiko (사진 왼쪽)
2012 년 NTT 데이터에 입사. 이후 PostgreSQL에 관한 업무에 종사 주로 PostgreSQL의 본체 개발, 기술 지원 및 국내외 불문하고 다양한 컨퍼런스에서 강연을하고있다. 2016 년부터 NTT OSS 센터에 근무. PostgreSQL 커뮤니티는 Contributor으로 복제, VACUUM 분산 트랜잭션 기능의 개발 및 버그 수정을 통해 코어 개발에 기여.
다나카: 날개 (타나카 날개) @ yoku0825 (사진 오른쪽)
Linux 서버 운영자가 MySQL 기관을 거쳐 GMO 미디어에서 MySQL 전문 DBA로서 경력을 쌓는다. 주요 저서로 「MySQL 즉각적인 쿼리 튜닝」(임프레스 2016 년). MySQL 분야의 Oracle ACE에서 "MySQL 5.7 Community Contributor Award '를 수상한 핑크 두부.
[비교 포인트 ①\] DDL 작업의 비 차단
[비교 포인트 ②\] DML 문 성능
[비교 포인트 ③\] 테이블 조인 (JOIN) 알고리즘
[비교 포인트 ④\] 트랜잭션 처리의 격리 수준
[비교 포인트 ⑤\] 저장 프로 시저, 트리거
[비교 포인트 ⑥\] 복제 논리 형과 물리 형
[비교 포인트 ⑦\] 중 하나의 DB에만있는 편리한 기능
[비교 포인트 ⑧\] 데이터 형의 느슨 함, 유형 변환, 문자열 비교
\[결론\] 어느 쪽을 어떤 서비스에 사용하나요?
관련 기사
DDL: Data Define Language 의 약자로, 스키마/도메인/테이블/뷰/인덱스를 정의/변경/제거할 때 사용하는 언어이다.
테이블을 생성하고, 테이블 내용을 변경하고, 테이블을 없애버리는 것.
흔히CREATE, ALTER, DROP을 떠올리면 된다.
DML: Data Manipulation Language 의 약자로, Query(질의)를 통해서 저장된 데이터를 실질적으로 관리하는 데 사용한다.
테이블 안의 데이터 하나하나를 추가하고 삭제하고 수정하는 것.
흔히INSERT, DELETE, UPDATE를 떠올리면 된다.
DCL: Data Control Language 의 약자로, 보안/무결성/회복/병행 제어 등을 정의하는데 사용한다. 데이터 관리 목적.
흔히COMMIT, ROLLBACK, GRANT, REVOKE를 떠올리면 된다.
-COMMIT: Transaction의 변경 내용을 최종 반영한다고 재판 결정하는 것.
-ROLLBACK: Transaction의 변경 내용을 모두 취소하고 이전 상태로 되돌리는 것.
(Transaction : Database에서 하나의 Logical Function을 수행하는 단위. 즉, 작업 하나의 단위. 하나의 Transaction은 COMMIT되거나 ROLLBACK되어야 한다. 하나의 Transaction은 정상적으로 종료되면 COMMIT을 비정상적으로 종료되면 ROLLBACK 수행. )
[비교 포인트 ①] DDL 작업의 비 차단
- 오늘은 잘 부탁합니다. 우선 DDL (데이터 정의 언어)에 대해 비교하고 싶습니다. MySQL에서 무엇입니까?
다나카: MySQL은 많은 DDL 작업을 논 블로킹 (트랜잭션 중에도 테이블에 블록이 들지 않는)에서 실행할 수 있다는 장점이 있습니다. 이 기능은 MySQL 버전 5.6에서 구현되었습니다. 또한 대상의 컬럼 만 검색 같은 ALTER TABLE (컬럼 이름을 변경하는 컬럼을 추가하는 등)의 경우 테이블을 처음부터 다시 빌드하지 않기 때문에 처리 속도가 빠르고, 전체 서버의 부하를 줄일 수 있다는 특징 도 있습니다.
- PostgreSQL는 ALTER TABLE 등의 DDL 작업은 논블로킹은없는 것일까요?
사와다: 그렇네요. 어떤 DDL 문을 발행되었는지에 따라 달라집니다 만, 예를 들어 열을 추가하는 등 테이블을 재 작성 작업은 테이블에 블록이 발생하게 참조 할 수 없게되어 버립니다.
-하지만 프로덕션 DB에 대해 ALTER TABLE을 걸고 싶은 경우도있을 거라고 생각합니다. 그 때 어떤 방법을 취해야하는 이유는 무엇입니까?
사와다: pg_repack는 유지 보수 용 외부 도구가 사용되는 경우가 많습니다. 그것을 사용하면 REINDEX 나 일부 ALTER TABLE 조작을 최소화 잠금에서 실행할 수 있습니다.pg_repack - PostgreSQL 데이터베이스의 테이블을 최소화 잠금으로 재구성합니다
- PostgreSQL을 보수 · 운용하고있는 분은 그 도구의 존재를 꼭 기억 싶네요.
[비교 포인트 ②] DML 문 성능
- 다음은 각종 DML (데이터 조작 언어)을 비교하고 싶다고 생각합니다. 먼저 SELECT 문입니다.
다나카: 간단한 SELECT이라면, MySQL도 PostgreSQL도 크게 다르지 않다고 생각합니다. 좋은 승부 게 아닐까요.
사와다: 그렇네요. SELECT는 크게 다르지 않습니다.
다나카: 그러나 대량 데이터의 정렬이 필요한 SELECT (ORDER BY를 한 후 테이블의 모든 데이터를 검색하는 등)은 MySQL이라고 늦어 져 버립니다. 왜냐하면 PostgreSQL과 비교하면 MySQL은 정렬 알고리즘이 그만큼 우수하기 때문입니다. MySQL은 대량 데이터를 정렬하는 것을 기본으로 유스 케이스로 상정하고 있지 않습니다.
- 어떤 조건의 SELECT이라면, MySQL은 강점을 발휘합니까?
다나카: MySQL은 신규 10 건이나 100 개의 데이터 (TOP n 레코드)를 취득하는, 예를 들어 Twitter와 같은 유스 케이스에 특화되어 있습니다. 그런 장면은 PostgreSQL보다 빠릅니다.
- 다른 DML 문은 어때? 예를 들어 UPDATE는.
다나카: UPDATE, MySQL 쪽이 성능이 우수하네요.
사와다: 저도 그렇게 생각합니다.
- 그 이유는 무엇입니까?
사와다: PostgreSQL을 추기 아키텍처라고해서 UPDATE 할 때 INSERT에 가까운 처리가 실행되고 있습니다. 무슨 말인가하면, 이전의 행 삭제 플래그의 종류를 세운 뒤, 변경된 데이터를 가진 새 행을 추가하고 있구요.
다나카: 한편 MySQL은, UPDATE 대상이되는 행의 값을 직접 덮어 쓸 수 있습니다. 문자 그대로 "업데이트"하고 있구요.
- 아키텍처이면 확실히 MySQL 쪽이 UPDATE 조작은 빨리 될 것 같네요. 그러면, DELETE에 관해서는 어떻습니까?
다나카: 과거 MySQL에 DELETE가 느리다는 단점이있었습니다. 이것은 데이터 삭제 후 보조 인덱스 (클러스터 인덱스를 제외한 모든 인덱스)를 동기화에 붙여 다시하고, 그 처리에 시간이 걸려 있었기 때문입니다.
하지만, 버전 5.5에서 상당히 해소되었습니다. 보조 인덱스의 비동기 체인지 버퍼 (보조 인덱스 항목의 변경을 버퍼링 해 두었다가 서버가 유휴 상태에있을 때 등에 변경 내용을 병합하는 방법)이 효과가있게 되었기 때문에 이전만큼 "DELETE가 느린 "그 말은하지 않습니다.
[비교 포인트 ③] 테이블 조인 (JOIN) 알고리즘
- 다음은 테이블 결합을 비교합니다. 자주 사용되는 테이블 조인 알고리즘은 "네 스티드 루프 조인 (Nested Loop Join)」 「해시 조인 (Hash Join)」 「정렬 병합 조인 (Sort Merge Join)」의 3 종류가 있습니다 만.
다나카: MySQL은 기본적으로 네 스티드 루프 조인 밖에 지원하지 않습니다. 왜냐하면, MySQL은 "복잡한 알고리즘은 가급적 지원하지 않는다 '는 설계 사상에 근거하고 있기 때문입니다.
- 왜 MySQL은 그러한 설계 사상이나요?
다나카: Web 어플리케이션에 사용되기 전에, MySQL은 원래 편입 계 시스템에서 사용 된 것에 기인하고 있습니다.
임베디드 매우 짧 디스크와 메모리에서 DB를 가동시킬 필요가 있고, 복잡한 알고리즘을 최대한 깎아 떨어 뜨리는 정책으로 설계되어 왔어요.
- 납득 이군요. 한 PostgreSQL은 어떻습니까?
사와다: PostgreSQL는 3 종류 모두 지원합니다.
- 각각의 결합 패턴은 어떤 유스 케이스에 향하고있는 것일까 요?
사와다: 결합 할 데이터 량이 많을 때는 해시 조인과 정렬 병합 조인을 사용하는 것이 좋다고 생각합니다. 데이터가 이미 정렬되어있는 경우에는 정렬 병합 조인이 더 좋고, 그렇지 않으면 해시 조인을 추천합니다.
네 스티드 루프 결합이 최선의 선택이 될 것은 결합 된 테이블 중 하나의 데이터 양이 적어 다른 많은 같은 때. 또는 내부 테이블 측이 인덱스 스캔을 사용할 경우군요. 이것은 MySQL에서도 마찬가지입니다.
f : id : blog-media : 20170901185246j : plain
- 다음은 트랜잭션 처리에 대해 묻고 있습니다. PostgreSQL과 MySQL은 각각의 기본 트랜잭션 격리 수준 (트랜잭션 처리를 여러 번 실행 된 경우에 얼마나 많은 데이터 일관성 및 정확성에서 실행하는 방법을 정의하는 것)가 다르다는 이야기 수 있습니다.
다나카: 그렇습니다. MySQL은 기본이 REPEATABLE-READ가 있습니다. 이 방식이라면 읽기 대상 데이터가 도중에 다른 트랜잭션에서 변경되어 버릴 염려가 없습니다.
그러나 팬텀 리드 (동시에 실행되는 다른 트랜잭션이 추가 데이터가 도중에 보여 버리는 현상)이 발생할 수 있습니다. MySQL은 팬텀 리드를 피하기 위해, 넥스트 키 록하는 구조를 채용하고 있습니다.
- 그것은 무엇입니까?
다나카: 트랜잭션이 실행되고있는 동안 레코드가 증가하지 않도록 기본 키의 증가 대상 값까지 잠금을 건다는 것입니다. 이 방법을 통해 데이터의 안정성은 유지 될 것입니다 만, 동시에 이로 인해 의도하지 않은 잠금이 걸려, 고장의 원인이되어 버릴 수도 있습니다.
예를 들어, SELECT FOR UPDATE 등으로 WHERE 절에 "<(부등호)"를 사용하고 "ID가 10 이상"레코드를 검색했다고합니다. 그러면 10 개 이상의 키가 모두 잠겨 버립니다.
이렇게되어 버리면 새로운 기본 키를 생성하지 못하고, INSERT 할 수 없게되어 버립니다. 이 사양은 꽤 빠져 그런데이므로주의 해 두는 것이 좋습니다.
잠금 경합을 줄이기 위해 트랜잭션 격리 수준을 낮은 READ-COMMITTED (항상 커밋 된 최신 데이터를 읽는 형식)로 변경하여 운용하는 경우도 있습니다.
- PostgreSQL에서는 기본 트랜잭션 격리 수준은 무엇입니까?
사와다: READ-COMMITTED입니다. 이 방식의 경우, 팬텀 리드 및 비 반복 가능한 읽기를 (동일한 트랜잭션에서도 동일한 데이터를 읽어 들일 때마다 값이 변하는 현상)이 발생할 수 있기 때문에 운용에서는 그 점을 조심해야합니다.
또한 PostgreSQL에서는 트랜잭션 격리 수준을 REPEATABLE-READ로 변경하더라도 넥스트 키 잠금을 차지하지 않고 다른 방법으로 팬텀 리드를 막고 있습니다. 따라서 잠금 충돌을 방지 쉽다는 점은 MySQL보다 더 있을지도 모릅니다.
- 저장 프로 시저에 대해서는 어떻습니까?
사와다: PostgreSQL은 SQL 이외에도 Python 등을 이용한 외부 프로 시저를 사용할 수있는 것은 장점이라고 생각합니다.
다나카: MySQL은 SQL만을군요. 또한 MySQL 단체에서는 저장 프로 시저의 단계 수행 할 수 없다는 단점이 있습니다.
- 트리거에 대해서는?
다나카: MySQL 5.6 이전 버전에서는 테이블 당 최대 6 개까지만 다중 트리거가 건 수 없다는 단점이있었습니다. 또한 BEFORE INSERT TRIGGER가 테이블 당 1 개 밖에 설치되고 않았기 때문에 상당히 제한이 있었어요.
현재는 트리거 개수의 제한은 없으며되어 있습니다. 그러나 MySQL 트리거는 FOR EACH ROW 밖에 없어서 FOR EACH STATEMENT이 없기 때문에, 그 점은 고려되어야합니다.
[비교 포인트 ⑥] 복제 논리 형과 물리 형
- 다음은 복제에 대해.
다나카: MySQL의 경우 복제는 논리 형 (SQL 문 자체를 복사) 또는 물리 형 (변경 후 행 이미지를 복사) 중 하나를 선택할 수있게되어 있습니다. 종래는 논리 형이 기본 설정이었던 것입니다 만, MySQL 5.7 이상에서 물리 형이 기본이되었습니다.
사와다: PostgreSQL는 물리 형만군요. 다만, 현재 베타 버전으로 출시 된 버전 10에서 부울도 사용할 수있게되어 있습니다.
- MySQL에서 "물리적 형태가 기본이됐다"는 얘기가있었습니다 만, 논리 형은 어떤 단점을 안고 있었다 있을까요?
다나카: 논리 형은 좋든 나쁘 든 유연한 곳이 있고, 예를 들어 마스터 테이블과 종속 테이블의 스키마가 다소 달랐다하더라도 SQL조차 통해서 버리면 오류가 안되나요.
그 사양을 사용하여 캐주얼 운용 할 수 있다는 장점이 있습니다 만, 마스터와 슬레이브에 차이가 있어도 인식하지 못할 수있는 데이터 안정성 측면에서 보면 문제가 있습니다. 따라서 "안전 측면을 기본으로한다"는 사상에서 물리 형이 기본이 된 거죠.
[비교 포인트 ⑦] 중 하나의 DB에만있는 편리한 기능
- 어느 하나에 만 유용한 기능은 있을까요?
다나카: 지금까지는 부분적으로 잘라낸 결과 집합에 집계 함수를 적용 할 수있는 윈도우 함수와 SELECT 문을 실행하기 전에 하위 쿼리를 만들 수 WITH 절 등 집계에 적합한 기능이 PostgreSQL에만있었습니다. 따라서 분석 시스템의 처리는 PostgreSQL 쪽이 강했다입니다.
단, 창 함수 WITH 절에도 MySQL도 버전 8.0에서 도입 될 예정입니다.
- 그렇게되면, 분석 계 처리는 미래에 차이가 없어 질지도 모르 네요. 다른 한쪽에 있고 다른 한쪽에는없는 기능이 있습니까?
사와다: 병렬 쿼리입니까. 이것은 처리 속도를 빠르게하기 위해 여러 CPU를 활용하여 쿼리를 실행하는 것입니다.
그리고, 많은 엔지니어가 PostgreSQL를 선택하는 이유로 꼽는 것이 PostGIS는 타사의 OSS 도구 네요. 지도와 기하 데이터 정보를 처리하는 것입니다. MySQL의 것보다 기능이 풍부하고 PostgreSQL가 가진 장점 중 하나라고 생각합니다.
PostGIS - Spatial and Geographic Objects for PostgreSQL
다나카: 뭔가 PostgreSQL로 부럽다 기능 있었던 걸까. 그래, pg_basebackup이 굉장히 편리하네요. 온라인하고 원격 데이터베이스 클러스터 기반 백업이 잡히므로.
MySQL의 경우 온라인에서 물리적 백업 수단이 XtraBackup 또는 Enterprise Backup 밖에 없기 때문에, 온라인하고 원격으로 기반 백업을 수행 할 수 없어요.
[비교 포인트 ⑧] 데이터 형의 느슨 함, 유형 변환, 문자열 비교
- 마지막 데이터 형식의 느슨 함 (암시 적으로 실시되는 형태 변환과 문자열 비교의 엄격함 등)에 대해 들려주세요.
다나카: 버전 5.6 이전의 MySQL에서는 데이터 형식의 느슨 함이 문제가되는 경우가 많았습니다. 하지만 5.7에서는 전체적으로 카타 방법으로 수정되어 이전보다 데이터 형으로 인해 버그가 발생하는 경우가 줄었습니다.
하지만 몇 가지주의해야 할 사례가 존재하고, 예를 들어 이것.
(int) 1 = (string) '1'= (string) '1Q84'
MySQL의 경우,이 3 개는 "같은 값이다"라고 인식되는 것입니다.
- 어! ? 그 이유는 무엇입니까?
다나카: 왜인가하면, 숫자 "1"과 문자열 "1"을 비교할 때 암시 적으로 문자열에서 숫자의 형태 변환이됩니다. 그래서 첫 번째와 두 번째는 같은 값으로 인식되는 것입니다.
그리고 숫자 "1"과 문자열 "1Q84"를 비교할 때에도 "1Q84"를 숫자로 암시 적 형식 변환합니다. 그러면 무슨 일이 일어나는가하면, 데이터를 전방에서 읽기 넣고해서 숫자로 인식 할 수있는 부분까지 형식 변환하는 것입니다.
- 그렇군요. 즉 「1Q84」의 「1」까지가 메모리에 적재된다고.
다나카: 것. 그래서 "같은 값"이라고 인식되어 버리는 것이군요.
그 밖에도 암시 적 형식 변환되는 경우가 있고, 예를 들어 날짜 형식 "2017-07-01"에서 숫자 "1"을 당기면 '20170700'라는 정수가 반환됩니다. 버그의 원인이되기 쉽다 사양이므로 MySQL을 사용하는 경우에는 조심하는 것이 좋다고 생각합니다.
- 형식 변환에 대해 하나의 PostgreSQL는 어떤 사양입니까?
사와다: PostgreSQL는 다양한 형식 변환에 관해서는 꽤 카타쪽에 걸고 있습니다. 방금 다나카: 씨가 말씀하신 것 같은 문자열에서 숫자 유형으로 암시 적 변환은 일어나지 않기 때문에 SQL을 쓰는 사람이 명시 적으로 캐스팅해야 안 되네요. 혹은 묵시적 형 변환을 사용자가 정의하는 것으로 대응하는 방법도 있습니다.
- 문자열 비교는 어떻습니까?
다나카: MySQL은 기본적으로 문자열 비교에서 대소 문자를 구분하지 않습니다. 또한 버전 8.0부터는 기본 설정이라고 탁음과 반 탁음를 구별하지 않습니다. '은'과 '파'와 '토바'동일시되고 있으며, '병원'과 '아름다움 요인'도 동일시됩니다.
- 그 사양 것은 뭔가 이유가 있나요?
다나카: Unicode 사양에 의존하고있는 것입니다. Unicode 데이터 정렬 (정렬)의 엄격함 설정이 레벨 1부터 레벨 4까지 단계적으로 나누어 져 있습니다.
'은'과 '파'와 '토바'를 구별하기 위해서는 레벨 2 이상의 비교 '병원'과 '아름다움 요인'을 구별하기 위해서는 레벨 3 이상의 비교가 필요한 만, MySQL 기본 설정에서는 1 수준 밖에 사용하지 않는 비교되어 있습니다.
레벨을 올리면 문자열의 구분은 정확하게됩니다 만, 처리는 무거워지고 있습니다. MySQL은 "간단한 처리 속도를 향상시키는 '라는 디자인 철학을 기반으로 만들어져 있기 때문에 처리 속도를 버리면 서까지 문자열 비교의 엄격함을 가지고 같은 것은하지 않을 것입니다.
- 그렇군요. 그런 사양에서 DB의 설계 사상을 엿볼 수있는 것은 매우 재미 있네요.
[결론] 어느 쪽을 어떤 서비스에 사용하나요?
- 마지막으로 총괄로 PostgreSQL과 MySQL이 각각 어떤 서비스를 향하고 있는지를 말해 줄 수 있습니까?
사와다: PostgreSQL는 "다기능 인 것 '이 가장 큰 장점이기 때문에 그 특징이 사는 같은 시스템에는 적합하다고 생각합니다. 예를 들어, Oracle Database로부터의 마이그레이션 및 SIer 계 기업에서 사용되는 경우가 많다는 인상을 개인적으로 가지고 있습니다.
다음은 분석 기반 시스템에서 자주 사용됩니다. 그러나 이것도 전술 한 바와 같이 MySQL의 분석 기능이 서서히 충실 해오고 있기 때문에 미래에 차이는 적게 오는 것입니다.
- MySQL 분은 어떻습니까?
다나카: 기본적으로 간단한 Web 서비스에 적합하다고 생각합니다.
일정 수의 결과 세트를 가지고 와서 그 데이터를 표시하는 같은 느낌의. 예를 들어 Twitter와 같은 타임 라인의 시작 부분을 표시하고 아래로 스크롤하면 다음의 데이터를 읽어들이 같은 서비스는 MySQL에 특히 잘 어울린다 생각합니다.
하지만 버전이 올라갈 때마다 PostgreSQL도 MySQL도 고성능 해지고 있기 때문에 결국은 사용하고 싶은 분을 절대로 좋지 않을까요.