심볼 테이블 ( Symbol table )
파이썬에서 모든 데이터는 객체의 형태로 저장됩니다.
그리고 변수는 단지 객체의 이름일 뿐인데, 이를 심볼( Symbol )이라 합니다.
심볼은 파이썬에서만 있는 용어가 아닙니다.
Java로 따지면 실제 주소의 레퍼런스( hashcode() )가 심볼입니다.
파이썬에서는 이름과 레퍼런스를 저장하는 테이블이 따로 있는데, 이를 심볼 테이블( Symbol Table )이라 합니다.
심볼 테이블이란,
1) 변수의 이름과 데이터의 주소를 저장하는 테이블입니다.
2) 심볼 테이블의 내용을 살펴 보기 위해서는 globals(), locals() 내장 함수를 사용하며, 함수 호출로 반환된 테이블은 스코프( scope )를 나타냅니다.( global table , local table ) 그리고 테이블의 내용은 Dictionary 타입의 객체로 반환합니다.

심볼 테이블은 위와 같이 객체의 이름( 변수 )과 주소가 함께 저장되어 관계를 갖게 됩니다.
또한 객체마다 심볼 테이블이 존재하여 객체에서만 사용할 수 있는 변수를 정의할 수 있습니다.
예를들어 위 그림에서 전역으로 할당된 name, age , foo class 변수가 저장되어 있는 table을 Global Symbol table( 전역 심볼 테이블 )이라 하고,
foo 클래스를 인스턴스화한 객체는 또 다른 Symbol table이 생성되어 객체에서 사용 가능한 변수( i, j )들이 저장됩니다.
그리고 위 그림에서 등장하지 않았지만, 블록 단위에서 생성된 객체에 대해서는 Locals Symbol Table이 생성되고, 블록이 끝나면 테이블이 사라집니다.
즉 Local Symbol Table은 객체가 존재하는 동안 일시적으로 생성되었다가 사라지는 테이블입니다.
이 내용은 뒤에서 예제로 자세히 살펴보겠습니다.
심볼 테이블이 존재한다는 것은, 객체의 확장이 가능하다는 의미입니다.
당연하게도 내장 객체가 아닌, 개발자가 생성한 객체는 동적으로 변수를 추가할 수 있습니다.
반면, 내장 함수는 심볼 테이블이 존재하지 않으며, 내장 클래스의 객체( str, tuple, dict 등 )는 심볼 테이블이 존재하지만 확장이 불가능합니다.
print(print.__dict__) # AttributeError: 'builtin_function_or_method' object has no attribute '__dict__'
str.a = 'foo' # TypeError: can't set attributes of built-in/extension type 'str'
__dict__ 는 네임 스페이스를 확인하는 속성입니다.
내장 함수 print의 네임 스페이스를 확인하려 하니, __dict__라는 속성이 없다고 하며,
내장 객체 str에 a속성을 추가하려고 하니, 속성을 추가할 수 없다고 합니다.
심볼 테이블의 개념은 약간의 무리는 있지만, 자바스크립트의 prototype과 느낌이 비슷합니다.
차이점이라면 JS에서는 prototype을 이용해서 내장 객체를 확장할 수 있지만,
파이썬은 파이썬이 제공해주는 객체의 확장을 막아 놓았습니다.
참고로 Symbol Table과 name space( 네임 스페이스 )는 다릅니다. ( 스택 오버 플로우 - 링크 )
class foo:
goo = "hello"
print(goo) # symbol table로 접근
print(foo.goo) # name space로 접근
예를들어 foo 클래스의 goo 변수를 접근하기 위해서,
foo 클래스 내부에서는 " goo "로 직접 접근이 가능하지만,
foo 클래스 외부에서는 " foo.goo "와 같이 네임 스페이스를 거쳐야 합니다.
제가 지금까지 말한 것은 네임 스페이스가 아닌, 심볼 테이블과 관련된 얘기임을 참고해주세요.
이제 예제를 통해 심볼 테이블을 확인해보도록 하겠습니다.
심볼 테이블 예제
global_a = 1
global_b = 'global'
def foo():
local_a = 2
local_b = 'local'
print(locals())
class MyClass:
x = 10
y = 20
# 1. global symbol table 확인
print(globals()) # 'global_a': 1, 'global_b': 'global', 'foo': <function foo at 0x00000228D8A05268>, 'MyClass': <class '__main__.MyClass'>}
# 2. local symbol table 확인
foo() # {'local_b': 'local', 'local_a': 2}
# 3. 정의된 함수 객체 확인
# symbol table이 있다는 것은 확장이 가능함을 의미한다.
# 그리고 __dict__를 통해 접근이 가능하다.
foo.c = 'hello'
print(foo.__dict__) # {'c': 'hello'}
# 4. MyClass 객체
print(MyClass.__dict__) # {'x': 10, 'y': 20, '__dict__': <attribute '__dict__' of 'MyClass' objects>,}
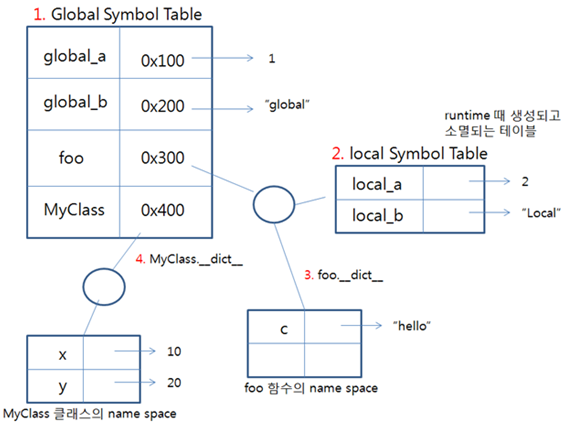
Symbole Table 예제를 도식화 하면 위와 같을 것입니다.
함수도 객체이며, 객체마다 name space가 존재하다는 것을 확인할 수 있습니다.
id()함수 - 객체의 아이디 확인
is - 레퍼런스 비교 연산자
id() 함수는 객체의 아이디를 반환하는 함수이고, is는 두 객체의 레퍼런스를 비교하는 비교 연산자입니다.
i1 = 10
i2 = 10
print(hex(id(i1)), hex(id(i2))) # 0x6c39e3a0 0x6c39e3a0
print(i1 is i2) # True
s1 = 'hello'
s2 = 'hello'
print(s1 is s2) # True
l1 = [1, 2, 3]
l2 = [1, 2, 3]
print(l1 is l2) # False
t1 = (1, 2, 3)
t2 = (1, 2, 3)
print(t1 is t2) # False
모든 객체는 자신이 생성될 때 id가 생성됩니다.
그런데 정수와 문자열 값이 같으면, 같은 객체를 참조하는 것을 확인할 수 있습니다.
List와 Tuple의 경우에는 값이 같아도 다른 객체를 참조하네요.
그러면 같은 값을 갖는 두 객체가 어떤 때는 같은 객체를 참조하고, 어떤 때는 다른 객체를 참조하는 것일까요?
20글자 이하의 문자열, 또는 리터럴로 표현된 정수는 같은 객체를 가르킵니다.
그런데 257 이상의 정수가 연산으로 얻어진 결과라면 다른 객체를 가르킵니다. ( 스택 오버 플로우 - 링크 )
명확한 것은 모든 객체는 자신이 생성될 때 id가 생성된다는 것입니다.

i1 = 256
i2 = 255 + 1
print(i1 is i2) # True
i1 = 257
i2 = 256 + 1
print(i1 is i2) # False
i1 = 257
i2 = 257
print(i1 is i2) # Ture
s1 = "a"*20
s2 = "a"*20
print(s1 is s2) # True
s1 = "a"*30
s2 = "a"*30
print(s1 is s2) # False
이상으로 심볼 테이블과 객체에 대해 알아보았습니다.
이번 글은 개념적이 이야기가 많았네요.
심볼 테이블은 변수의 이름과 주소가 관계를 맺고 있는 테이블이며, Global Symbol Table , Local Symbol Table이 있습니다.
그리고 객체가 생성되면 고유의 id 값이 생성된다는 점과, 문자열과 정수의 경우 같은 값을 갖더라도 특정 조건에 따라 같은 객체를 가르킬 수 있습니다.
'C Lang > Python Basic' 카테고리의 다른 글
| class 정리 - 클래스 속성과 인스턴스 속성 (0) | 2019.06.14 |
|---|---|
| class 정리 - 클래스 기본적인 사용 (0) | 2019.06.14 |
| 클래스 - 멤버, 생성자/소멸자, 연산자 오버로딩 (0) | 2019.06.11 |
| pycharm에 가상환경 적용하기 (0) | 2018.11.16 |
| 가상환경 사용하기(python기본인터 프리터를 통한 가상환경, conda를 통한 가상환경) (0) | 2018.10.26 |








