Stream API入門
Nodeのアドベントカレンダー、既に終わった枠が空いていて、この際書きたいネタがあったんで参加しました。宜しくお願いします。
アドベントカレンダーの時期だけ出没する弱い日曜Haskellerです。普段の実務ではNode.jsにお世話になってます。宜しくお願いします。
さて、みなさんStream API使ってますか?Node.jsといったら非同期ですよね、やっぱり。しかしながら、JavaScriptでも他の言語でも、非同期処理自体は注目されているものの、まだexperimentalという感じで様々なAPIが考案されては消えていき、また元々そういう文化が根強くなかったところから来た人たちにとって、こういう文化はちょっと立ち入りづらいところもあるかもしれませんね。
今日は、主にそういう人たちに向けて、まず非同期の色々なAPIの紹介、そしてその中でのストリームのメリット、そして実際のStream APIの使い方の紹介、そしてRxJSのススメをちょこっとだけやっておきます。
非同期処理とは
さて、非同期処理とはそもそもどんなものでしょうか?I/Oで便利とか、メモリの圧迫を防げるとか、色々言われるわけですが、実際にはそれらは非同期処理の実装による恩恵であって、非同期処理自体は、あなたがNode.jsを使っていれば身近にある、次のような処理のことです。
const fs = require('fs');
fs.readFile('/path/to/some', (err, data) => {
if (err) {
console.error(err);
return;
}
console.log(`size: ${data.length}B`);
});
このプログラムは、/path/to/someというファイルを読み込んで、そのファイルサイズを出力してくれるものです。しかしながら、注意しなければいけないのは、多くのプログラミング言語と違い、このプログラムのフロー自体はfs.readFileでブロックされるわけではなく、そのまま流れていくということです。どういうことかは動作を見てもらった方が分かりやすいと思うので、以下のようなプログラムに修正して実行結果を見てみましょう。
// test.js
const fs = require('fs');
fs.readFile('/path/to/some', (err, data) => {
if (err) {
console.error(err);
return;
}
console.log(`size: ${data.length}B`);
});
console.log('readFile done');
/path/to/someに16byteのファイルがある時、このプログラムの実行結果は、以下のようになります。
$ node test.js
readFile done
size: 16B
これが非同期の処理の特徴になります。このようなAPIが標準で提供されている処理系はNode.js以外にはそうそう無いでしょう。多くの言語の処理系で提供されているような処理も、もちろんNode.jsでも可能です。それは次のような処理です。
// test-sync.js
const fs = require('fs');
const data = fs.readFileSync('/path/to/some');
console.log(`size: ${data.length}B`);
console.log('readFileSync done');
このプログラムの実行結果は、以下のようになります。
$ node test-sync.js
size: 16B
readFileSync done
さっきと出力順が逆です。このような処理は、非同期処理と対応して同期処理と呼ばれます。つまり、同期処理とはプログラムの処理が同期され順に実行されていく処理のこと、非同期処理とは互いの処理が同期されず、いつ呼ばれるかのタイミングが分からずにそれぞれ実行される処理のことです。
さて、ここまでの説明で、あなたは、「非同期処理とはようは並列処理のことか」と思ったかもしれません。しかしながら、Node.jsの多くのプログラムはシングルスレッドで動いています。つまり、一つの仕事を行なっている間、別の仕事をする術は、標準APIには用意されていません。
どういうことでしょうか?あなたは上のプログラムの実行イメージを次のように考えたでしょう。
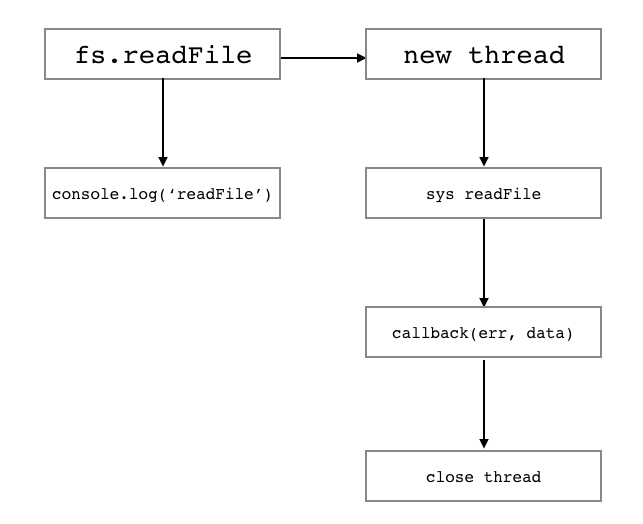
しかしながら、実際の動作はあなたの考えた図とは異なります。Node.jsの動作は以下のような図になっているのです。
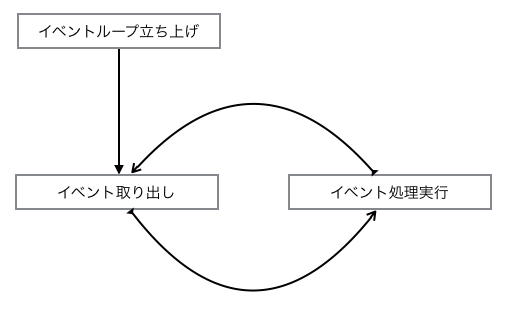
そして、fs.readFileは定期pollによって1イベントを監視するイベント処理を投入するのです。もっと簡単に言えば、大体のI/O操作はシステム(OS)に任せることができ、readFileなどの操作はシステムに任せきることで、Node.jsでは本来の処理に戻り、システムから通知があった段階でコールバックを走らせるということを行います。これはループ処理によってキューがなくなるまで行われる上のような循環図になりますが、誤解を恐れずもっと分かりやすく書くなら、以下のような処理になっているということです。
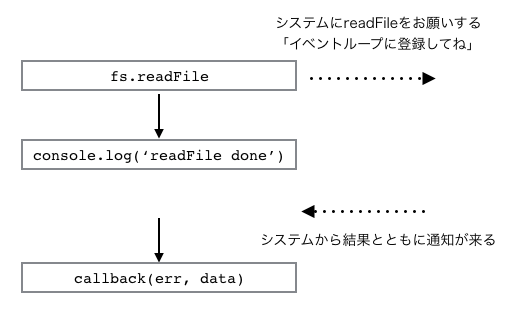
そしてそれぞれのイベント処理がどのタイミングで呼ばれるかは、実装とキューの中身の構成に依存します。
もっと詳細を知りたい方は、今となっては少々機能が足され、実装が変わっていたりしますが、大枠の仕組みは変わっていないので、大津さんのこの資料が参考になると思います2。
さて、これにより、あなたは分かり難いスレッドモデルなどよりもよっぽど簡単に、非同期な処理を実現できます。シングルスレッド内で、容易にインスタンスを共有できますし3、スレッドの発行や終了タイミングについて特に気にかける必要はありません。
非同期処理のAPI色々
さて、ここまでで、あなたはNode.jsにおける非同期処理の実装について、多少の理解ができたと思います。問題なのは、パフォーマンスが優秀でも、やはり非同期処理は並列処理と同様にプログラミングを行う上で扱いにくいということです。私たちは、多くの場合同期的な処理を求めていますし、パフォーマンスに問題がなければ、全てを同期的な処理で書いたでしょう。
Node.jsは、そのパフォーマンスを最大限に引き出すために、古来から様々なAPIを用意してきました。代表的なものがコールバックを受け取る関数です。そしてもう一つがEventEmitterとStreamです。また、それに合わせて、JavaScriptでも近代的な手法を取り入れるべく、様々なAPIが取り入れられてきました。PromiseとGeneratorは既にNodeには搭載されており、それに加え次期Node v8ではasync/awaitの搭載が予定されています。
それぞれの手法が一体どういう用途に向けてのものなのか、それぞれどのように使うのかをまとめておきましょう。
コールバックを受け取るAPI
Node.jsの標準の実装は、多くの場合この形式のAPIで提供されています。引数に、コールバック関数と呼ばれるクロージャを渡し、それをイベント度に呼び出すAPIデザインのことです。上述で使った次の形のAPIですね。
const fs = require('fs');
fs.readFile('/path/to/some', (err, data) => {
if (err) {
console.error(err);
return;
}
console.log(`size: ${data.length}B`);
});
他にも、setTimeoutなどのネイティブなAPIや、Node.jsの主だったライブラリでは、このデザインが用いられています。全てのコールバック関数を受け取るAPIが、非同期処理でないことに気をつけて下さい。例えば、Array.prototype.forEachなどはコールバック関数を受け取りますが、同期処理用のAPIです。つまり、
// test-foreach.js
[1, 2].forEach(n => {
console.log(n);
});
console.log('forEach done');
これの出力結果は以下のようになります。
$ node test-foreach.js
1
2
forEach done
コールバックを受け取る形式のAPIは、古くから使われ、とくにくせがあるわけでは無いため、非常に多くの場所で使われています。しかしながら、表現力が弱いことも確かです。よく槍玉に挙げられるのが、コールバック地獄というものです。以下の例を見てください。
const fs = require('fs');
fs.readFile('/path/to/some', (err, data) => {
if (err) {
console.error(err);
return;
}
data.trim().split('\n').forEach(path => {
fs.appendFile(path, 'done', (err) => {
if (err) {
console.error(err);
return;
}
});
});
});
これはファイルパスの一覧表が書かれているファイルを読み込み、それらのファイルそれぞれの最後に、doneと書き込むプログラムです。見て分かるように、とても単純なプログラムであっても、このようにネストが深く読みづらく書きづらいプログラムになってしまいます。またエラー処理に関しても、冗長で、同じような処理を幾度も書くことになってしまうのです。
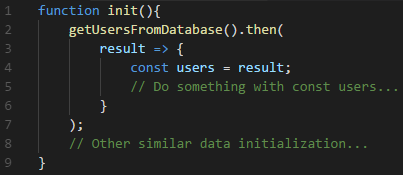
また、他にもこのデザインには問題があります。例えば、よくあることとして、データの取得時と全てのデータの取得が完了した場合の通知を受け取るようなAPIがあったとします。これをコールバックを使って以下のように実装したとしましょう。
function readContents(onNext, onEnd = () => { return; }, onError = err => { throw err; }) {
...
}
これを使うようにプログラムを書いてみます。
readContents(
data => {
console.log(data);
},
() => {
console.log('end');
},
err => {
console.error(err);
},
);
控えめに言っても、見やすいとも使いやすいとも言えませんね。このように非同期処理において、コールバックを受け取るようなAPIデザインは、素朴なアイデアであり、特殊な扱いをしなくて済みますが、その分使い勝手が非常に悪いという欠点がありました。
EventEmitter
Node.jsで複数のイベントをコールバックで扱うのではなく、専用のプロキシオブジェクトを通すことで、使い勝手を向上させようと、考案されたのがEventEmitterです。このオブジェクトは、eventsモジュールから利用できます。では、先ほどのような関数をEventEmitterを利用するよう、書き換えてみましょう。
const EventEmitter = require('events');
class ReadContentsEmitter extends EventEmitter {
...
}
function readContents() {
return new ReadContentsEmitter();
}
readContents()
.on('data', data => {
console.log(data);
})
.on('end', () => {
console.log('end');
})
.on('error', err => {
console.error(err);
})
;
これによってコードの見通しは、コールバック版より随分良くなりました。EventEmitterはイベント駆動の非同期処理を行う場合に非常に便利です。Node.jsでは、netモジュールのServerクラスや、streamモジュールのストリームなど多くのクラスがEventEmitterをベースに作られています。
ところで大事なことですが、EventEmitterは非同期処理をサポートしてくれるようなAPIであって、EventEmitter自体が非同期であるわけではないことには注意が必要です。次の例をみてください。
// test-eventemitter.js
const EventEmitter = require('events');
class MyEmitter extends EventEmitter {}
const emitter = new MyEmitter();
emitter.on('data', data => console.log(`data: ${data}`));
emitter.emit('data', 'sample');
console.log('emit done');
このプログラムの出力は必ず以下の様になります。
$ node test-eventemitter.js
data: sample
emit done
つまり、あくまでEventEmitterは同期的であり、emit()が非同期に行われる場合には非同期になるというだけなのです。
Promise
コールバック地獄を抜け出す方法として、古くから活用されていたのが、Promiseです。
Promiseを広く多用してきた有名なJavaScriptライブラリに、jQueryがあります4。名高い、jQueryのajaxAPIではPromiseがふんだんに活用されていますね。
さて、非同期処理は、非同期とはいうものの、同期したい箇所もあります。以下の例を見てください。
const fs = require('fs');
fs.readFile('/path/to/some', (err, data) => {
if (err) {
console.error(err);
return;
}
fs.appendFile('/path/to/some2', data, (err) => {
if (err) {
console.error(err);
return;
}
});
});
このプログラムでは、二つの非同期処理、readFileとappendFileがありますが、この二つは完全に独立して扱われているわけではありません。appendFileは、readFileが出力した値を使っているため、readFileが実行された後、同期的に、非同期処理appendFileが呼ばれるということになります。このように、非同期処理の中で小さな単位で同期的な処理を必要とする場合があります。非同期処理において、コールバックのネストが深くなるのは、主にそのような場所においてです。
Promiseは、このような非同期処理の同期的関係を内部で管理してくれるオブジェクトです。実際にES2015のPromiseを使って、上のようなプログラムがどのように書けるか見てみましょう。
const fs = require('fs');
new Promise((resolve, reject) => {
fs.readFile('/path/to/some', (err, data) => {
if (err) {
return reject(err);
}
return resolve(data);
});
})
.then(data => new Promise((resolve, reject) => {
fs.appendFile('/path/to/some2', data, (err) => {
if (err) {
return reject(err);
}
return resolve();
});
})
.catch(err => console.error(err))
;
Promiseを使うことにより、同期的な関係をthenというチェインで繋げていくことができます。これによって、ネストはどんなにチェインを繋げても深くなりません。Promiseが考慮されたAPIを用意することによって、記述量もコールバックと大差なく書けるようになるでしょう。
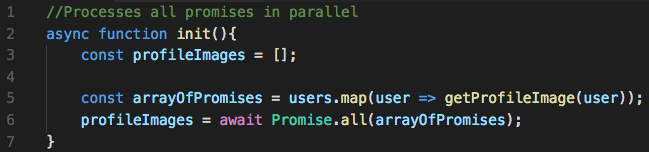
しかし、現状Promiseを考慮したAPIを提供しているライブラリはあまりありません。一つには、あまり処理系においての対応状況がよろしくなかったことなどが理由としてあります。もう一つは、async/await対応が目に見えていたからでしょう。おそらくasync/awaitが本格的に組み込まれれば、Promiseを考慮したAPIは格段と増えるでしょう。
async/await
さて、async/awaitは、Promiseを命令的なコードにおいて扱いやすくしたものです。私たちは多くの場合、非同期処理より同期処理の方が書き慣れています。async/awaitは、いわば、イベント駆動なものを除いた、非同期なコールバック形式のAPIの、完全な代替手段と言ってよいでしょう。async/awaitを使えば、さっきのPromiseのコード例は、次のように書くことができます。
const fs = require('fs');
async function asyncTest() {
try {
const data = await new Promise((resolve ,reject) => {
fs.readFile('/path/to/some', (err, data) => {
if (err) {
return reject(err);
}
return resolve(data);
});
});
await new Promise((resolve, reject) => {
fs.appendFile('/path/to/some2', data, (err) => {
if (err) {
return reject(err);
}
return resolve();
});
});
} catch (err) {
console.error(err);
}
}
asyncTest();
そして、async/awaitは、Generatorの5、Promise向けに特化したものです。つまり、Promiseを扱うGeneratorであり、Promiseを返す関数です。例えば、上のプログラムは、以下のようにGeneratorとPromiseを使った関数に変換することが可能です。
// helper
function generator_to_promise(gen) {
return new Promise((resolve, reject) => {
const generator = gen();
function step(result) {
if (result.done) {
return resolve(result.value);
}
return new Promise(resolveNext => resolveNext(result.value))
.then(
value => {
try {
step(generator.next());
} catch (err) {
reject(err);
}
},
err => {
try {
step(generator.throw(err));
} catch (nerr) {
reject(nerr);
}
}
)
;
}
step(generator.next());
});
}
// main
const fs = require('fs');
function asyncTest() {
return generator_to_promise(function* asyncTest_generator() {
try {
const data = yield new Promise((resolve ,reject) => {
fs.readFile('/path/to/some', (err, data) => {
if (err) {
return reject(err);
}
return resolve(data);
});
});
yield new Promise((resolve, reject) => {
fs.appendFile('/path/to/some2', data, (err) => {
if (err) {
return reject(err);
}
return resolve();
});
});
} catch (err) {
console.error(err);
}
});
}
asyncTest();
少し長いですが、基本を押さえればなんということは無いです。まずawaitは全てyieldに変換できます。Generatorのnext()によって、yieldまで実行した後返ってきた値をPromiseのresolveに投げてやれば、その値がPromiseだろうと普通の値であろうとPromiseオブジェクトの値に変換されます。catchには代替としてgenerator.throwを割り当てることができ、Generator内のtry-catchが処理できれば順次次の処理へ、処理できなければrejectとして返ることになります。あとは、これらを再帰関数でGeneratorのdoneまで順次実行していけば、最終的なPromiseが得られます。generator_to_promiseヘルパーはそのようなことをやっています6。
このように、Generatorと同じようなAPIによって、非同期処理を、あたかも同期的な処理のように記述でき、非同期処理の中でも同期的な部分において、コールバック形式の問題点やPromiseの特殊な記法を払拭できるようになります。
なお、せっかくなので、Promiseとの対応をまとめておきましょう。
| Promise | async/await |
|---|---|
Promise.resolve(obj) | await obj |
Promise.reject(err) | throw err |
promise.then(data => ...) | const data = await promise; ... |
promise.then(() => ...) | await promise; ... |
promise.catch(err => ...) | try { await promise } catch (err) { ... } |
Generator
Generatorは実際には、同期的な処理を担当する機能です。しかしながら、そのアイデアは、非同期処理にも利用できることは、前回見ました。ここで、もう一度Generatorを出しておきたかったのは、Streamの対となる存在としてです。
フライングして、async/awaitでGeneratorの話を出しましたが、今更ながらGeneratorのおさらいをしておきましょう。GeneratorはES2015で取り入れられた機能です。これを使えば、メモリ空間を抑えたり、イテレータの記述を楽に行えたりするようになります。例えば、フィボナッチ数列を求めるプログラムをGeneratorで書いてみましょう。
function* gen_fibonacci() {
let state = {
target: 1,
post: 1,
};
for (;;) {
yield state.target;
const pre = state.target;
state.target = state.post;
state.post = pre + state.target;
}
}
Generatorは、functionに*(アスタリスク)を付けることで、生成できます。yieldで実行が一度止まるようになっており、yieldを返したい値につけることで、値を返せるようになっています。この関数を使ってみましょう。
function get_fibonacci(n) {
const gen = gen_fibonacci();
for (let i = 1; i < n; i++) {
gen.next();
}
return gen.next().value;
}
get_fibonacci(1) // -> 1
get_fibonacci(2) // -> 1
get_fibonacci(3) // -> 2
get_fibonacci(10) // -> 55
このGeneratorによって、あなたは好きな段階でフィボナッチ数列の次の項の計算を計算機に通知でき、フィボナッチ数列の必要な項を取捨選択して保持しておくような処理ができますし、何よりこのジェネレータから取得できる項数には限りがありません7。あなたは、フィボナッチ数列のある項が欲しい時に、何項までを計算させるかを関数に通達する必要は無いのです。
現実には、フィボナッチ数列に関してそこまでの要求することは無いでしょうが、Generatorが色々な面で応用できそうだということは分かってもらえたでしょう。
Generatorのnext()には値を渡せるようになっており、値が渡されるとyieldの返り値になります。最初のnext()の引数は意味がありません。また、next()は返り値を表すvalueと、ステータスを表すdoneというプロパティを持っており、Generatorが終了した場合、doneはtrueになります。
ところで、Generatorの性質は、Streamの性質と対を成しています。Generatorは、 その出力を求められた時 、出力を求める計算を同期的に行い、結果を出します。対して、Streamは、出力を求める計算を行って その出力が求まった時 、その結果を非同期に出すのです。この関係は、GeneratorとStreamの理解を促進し、使い分けを考える上で重要でしょう。

Stream
さて、いよいよStreamについて考える番です。Streamはどんなものでしょうか?Node.jsのStream APIには、Streamに該当するものが大きく三つあるのですが、俗にStreamで大事になるのがReadableStreamというものの特徴です。後の二つは、まあオマケみたいなものです。
ReadableStreamは、いわばPromiseの出力を複数に対応させたものです。といっても、配列を出力するPromiseというわけではなく、出力が複数で、且つそれぞれが非同期になるようなものです。具体的にどういったものなのか、コードを見てもらった方が早いと思うので、見てみましょう。以下は、ファイルをgzipで圧縮して出力するサンプルです。
const fs = require('fs');
const zlib = require('zlib');
fs.createReadStream('/path/to/source')
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream('/path/to/dest'))
;
注目したいのは、createReadStreamの部分です。createReadStreamは、指定されたファイルの内容を一定バイトごとに取得し、それぞれの出力に対しイベントを流すのです。なぜそのようなことをするのでしょうか?
最初に紹介したサンプルでは、「readFileはシステムにファイルの読み込みを任せ、本業を行いながらシステムからの通知を待つことで、効率の良い処理ができる。そしてそれがNode.jsの非同期処理の強みだ」と紹介しました。しかしながら、その後、非同期処理の中には同期的な部分、つまり出力が取得できないと先に進めない処理があること、そしてそれを扱いやすくしたAPIを幾つか紹介してきました。
今回のサンプルプログラムの例を考えてみましょう。ファイルをgzip圧縮して、別ファイルに出力する様なプログラムです。これは、完全に処理が同期しています。ファイルの読み込みが行えなければ圧縮はできませんし、圧縮できなければ出力ができません。つまり、非同期処理をしても何の効率も引き出せないことになります。しかしながら、この様な処理は多くの箇所で出てくるでしょう。
さて、この様な処理においても非同期処理の強みを活かして、もっと効率の良い様な体系を作れないか、と考えてみましょう。gzip圧縮は、簡単に言えば、文字列を前から辿っていき、以前に共通部分があるような箇所を見つけた場合それをポインタに置き換えるようなアルゴリズムです。つまり、いきなり全体像を掴む必要はなく、ある程度文字列の先頭部分を取得できれば、それに対しての前処理を行うことが可能です。つまり、ある程度ファイルの内容が先読みできれば、ある程度処理を短縮できる可能性があります。これが、Streamのモチベーションです。
createReadStreamが行うことはとても単純です。簡単な流れは次の様になります。
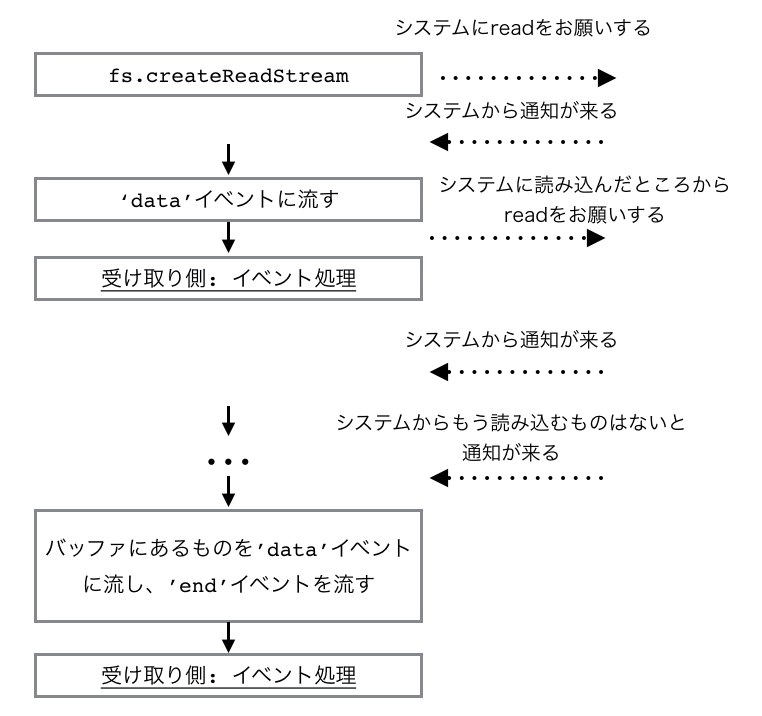
詳しいカスタマイズ方法などは後ほど紹介しましょう。これによって、その後の.pipe(zlib.createGzip())などは、バッファをちょっとずつ受け取り前処理を行いながら次の入力を待てる様になり、処理を前もって行うことができます。これは、非同期の強みをさらに活かせますね。
さて、今までは速さに注目してきたわけですが、Streamにおいては、管理機構によるコストなどから、よほど中間処理が重かったりファイルサイズが大きいというわけでもなければ、一気にreadFileしてしまった方が速度的には速い場合が多いです。想像してみてください。システムに移譲する処理は、普通結構重いわけです。それを細かくやっているわけですから、一回しか移譲処理を行わなくていい場合に比べ、遅くなるというのは当たり前のことですよね。あれ?と思った方が多いでしょう。では、なぜわざわざStream APIが使われるのでしょうか?Promiseでいいはずですよね。
さて、非同期によってI/O待ちをいくらか解消できるというのは、何も速度を最適化するだけが強みではありません。プログラミングにおいては、速度とそれに加えて空間も重要なトピックになります。そしてそれこそが、StreamがPromiseに比べて非同期処理の強みとなる部分です。
あなたは、例えばとても容量の大きなファイルを扱うことが、得てしてあるでしょう。今回の処理で、1Gのファイルを圧縮するといったことは多分に起こります。その様な場合に、一気にファイルを読み込み、圧縮をかけ、新たにファイルに書き込むことを想定してみてください。圧縮といえど、圧縮されたファイルサイズは小さくなるかもしれませんが、中間処理には処理するバッファのサイズ分空間が必要になります。また、1Gのファイルはそのままバッファになるわけですから、少なくとも1G+αのメモリ空間が消費されることになります。これはあまり許容できるものではありません。
一方で、Stream APIを使う場合は、一定量のバッファに対して、次のバッファが来るまでに前処理を行いバッファは捨てることができます。これによって、例え1Gのファイルでも、あなたは少ないメモリ量で、Promiseより少し遅いとはいえ、ある程度のパフォーマンスが出る様なコードが書けるのです。また、細かな単位で処理ができるということは、一気に読み込む場合に比べ、トータルの消費メモリは変わらなくても大きなメモリ消費を行っている時間を短縮できます。1Gのファイルサイズは(最適化を考えない場合!)一気に読み込み処理をする場合、圧縮処理をかけている間ずっと保持されます。それに比べStreamでは、短かな前処理の間細かなバッファを保持しておくだけですみます。Streamの強みはまさにそこにあるわけです。
ところで、async/awaitがただのPromiseを返すのに特化したGeneratorと見ることができた様に、PromiseもStreamが一出力に特化したものと見ることができます。つまり、PromiseはStreamで実装ができます。もちろん、Generatorでasync/awaitを実装するよりもネイティブのasync/awaitの方が最適化がかかっていますし、Promiseも同じです。しかしながら、同じ性質を持つ部分に着目することは、理解の上でも、そしてロジックを再利用する上でも役に立つことは、覚えておいて損は無いでしょう。
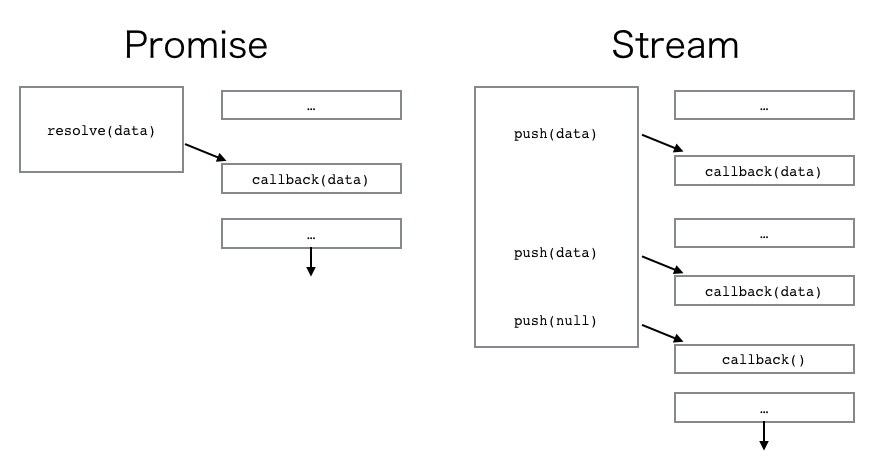
ここまでのまとめ
さて、StreamがPromiseと違う性質を持っていること、そしてStreamが非同期処理においてどのように役に立つのかは分かってもらえたでしょうか?あなたは、そもそもの非同期処理の利点、そして非同期APIそれぞれの利点と、それぞれのAPIによって受ける恩恵が違うことを理解したでしょう。さらに、あなたは一概に非同期にすればいいわけでは無いこと、一概にPromiseやStreamを使えばいいというわけでは無いことを理解したはずです。例えば、あなたはコンフィグを読み込んでmain部分を起動する様なプログラムを書くとき、fs.readFileよりもfs.readFileSyncを活用するべきです。そこで、わざわざイベントループを回すことには、何の意味もありません。
const fs = require('fs');
const main = require('./main');
/** Bad:
fs.readFile('/path/to/config', (err, config) => {
if (err) {
throw err;
}
main(JSON.parse(config));
});
*/
const config = JSON.parse(fs.readFileSync('/path/to/config'));
main(config);
非同期がただのイベントループであることを理解したあなたは、単にreadFileによってイベントをループに登録し待機させるよりも、全く同じことをループにイベントを登録せずに同期APIを使用して行った方が効率が良いと分かるはずです。またここでStreamを使うことにも何の意味もありませんね。configはそれほど大きいファイルではないはずですから。
次の様なプログラムでは、あなたはStreamを使用するのがいいかもしれません。
const fs = require('fs');
const Base64Encoder = require('b64').Encoder;
const Sender = require('./send-anything');
const sender = new Sender();
/** Maybe Bad:
fs.readFile('/path/to/data', (err, data) => {
if (err) {
sender.rollback();
throw err;
}
sender.write(data.toString('base64'));
});
*/
fs.createReadStream('/path/to/data')
.pipe(new Base64Encoder())
.on('data', data => {
sender.write(data);
})
.on('error', err => {
sender.rollback();
throw err;
})
;
base64エンコーディングは、先頭のある程度の位置までが分かれば、そこまでは完全にエンコーディングできる形式ですから、Stream化をうまく行えます。b64はbase64のエンコードとデコードをストリーム上で行える様にしてくれるライブラリです。あなたがどの様なデータを受け取るのかわかりませんが、もしデータの形式が不明な場合はStream化をしておけば汎用的に使えるAPIにできます。対して、もし速度が重要で、データが小さいサイズだと分かっている場合は、単純にasync形式で提供した方がいいかもしれません。
同期的なAPIを使うか非同期的なAPIを使うか、はたまたそのAPIの中でもどの様な形式のものを使うかを、時と場合によって上手に判断することが大事なのです。
Stream APIの使い方
Streamの種類とそれぞれの機能
では、いよいよ本題のStreamの使い方についてです。さて、Streamの名を冠するオブジェクトには、大きく分けて三種類あります。一つはReadable、二つ目はWritable、そして三つ目がその両方の機能を持つStream、Duplexです。
Node.jsのStreamの基本的な概念はとても単純です。それは、ReadableなものとWritableなものはpipeで繋げられる、ということです。

Duplexはどちらの機能も持っているため、どちらとも繋げることができます。想像しやすいのは、蛇口とバケツのイメージです。
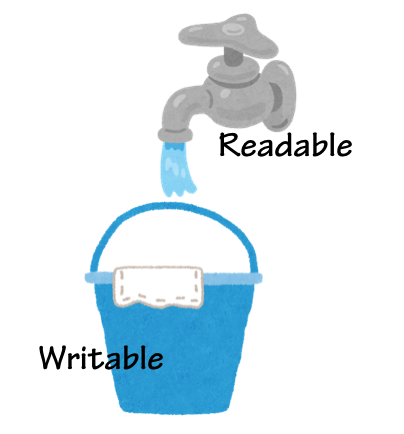
Duplexは蛇口を持ちつつ、バケツの様に蛇口から水を受け取ることもできます。ReadableとWritableはどういったものがあるか想像できるでしょうが、Duplexはパッと思いつかない人もいるかもしれません。Node.jsでは、SocketがDuplexで実装されています。何かを相手に流したり、逆に何かを相手から受け取ったりということが、それぞれReadable、Writableの機能として実装されています。また、一番利用されやすいのがTransformというDuplexから派生したものです。これは、タンクのような役割をするDuplexをユーザーが作りやすくするための基底クラスで、上流のReadableから受け取ったものを加工して、下流のWritableに流すという役割を受け持ちます。
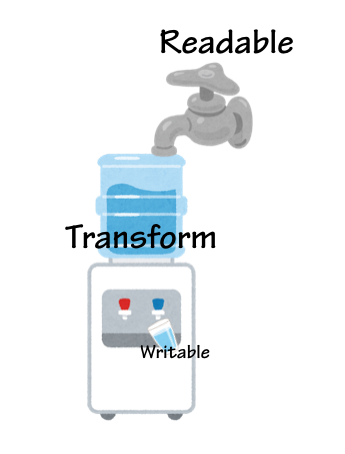
前に紹介したcreateGzipが返すストリームは、Transformを使って実装されています。それぞれの基底クラスを使って、あなたが何かクラスを作ろうという場合、それぞれ実装する必要のあるメソッドがあります。
| 基底クラス | 実装する必要のあるメソッド |
|---|---|
| Readable | _read |
| Writable | _write |
| Duplex | _read/_write |
| Transform | _transform |
例えば、カスタムのReadableの作り方を示しておきましょう。
// test-custom-readable.js
const Readable = require('stream').Readable;
class CustomReadable extends Readable {
constructor(max) {
super();
this.state = 0;
this.max = max;
}
_read(n) {
for(let l = Math.min(this.state + n, this.max); this.state < l; this.state++) {
this.push(this.state.toString());
}
if (this.state === this.max) {
this.push(null);
}
}
}
new CustomReadable(10)
.pipe(process.stdout) // process.stdout implements Writable
;
このプログラムの実行結果は、以下の様になります。
$ node test-custom-readable.js
0123456789
0から与えられた数字までを繋げた文字列を流すストリームです。このように、それぞれのメソッドを実装することで、後は基底クラスの処理に任せることができます。他のクラスの実装の仕方については、Node.jsのStreamモジュールのドキュメントやStream Handbookを読んでみるのがいいでしょう。
さて、StreamクラスはEventEmitterを実装しており、それぞれのイベントを受け取ることもできます。イベントの一覧は次の様になります。
- Readableのイベント
- data: データが取得できるようになった時にそのデータとともに発火
- readable: 取得できるデータがストリーム内に発生した時に発火
- end: データを全て流し終えた時に発火
- error: エラーが発生した時にエラーとともに発火
- close: ストリームのリソースが閉じられた時に発火(全てのストリームがこのイベントを流すわけではありません)
- Writableのイベント
- drain: writeがfalseを返した時に準備ができてから発火
- pipe: Readableからpipeされた時にそのReadableと共に発火
- unpipe: Readableからunpipeされた時にそのReadableと共に発火
- finish: endが呼ばれ、全てのデータを処理し終えた時に発火
- error: エラーが発生した時にエラーとともに発火
- close: ストリームのリソースが閉じられた時に発火(全てのストリームがこのイベントを流すわけではありません)
Writableのdrain以外は、分りやすいと思います。drainに関してですが、このイベントは少し特殊です。一般に、書き込みが読み込みより速いとは限りません。その様な場合に、読み込みが書き込み速度を上回る場合があります。もし上回った状態をそのまま続けた場合、もちろん書き込みは行われないわけですから、Writableの内部バッファに読み込みから流れてきたものが溜まり続ける状態になってしまいます。その様な状況はあまりよろしくありません。そのため、Writableのwriteは、内部バッファが必要になった(つまり書き込みが追いつかなくなった)状態ではfalseを返す様にできています。そして、書き込み待機がなくなった時にdrainを呼び出すのです。通常は、これらを監視して、Readableに的確に処理を待つように通知することが必要です。心配しないでください、まさにpipeがそれを行ってくれるため、通常あなたはこのイベントに関して余計な気を回す必要はありません!
さて、Duplexは両方の機能をもっているわけですが、その機能それぞれに対して、的確にイベントを処理する能力も実装しています。もちろん、Duplexの派生クラスであるTransformもです。
これがNode.jsのStream APIの概略です。簡単ですね!
二つのモード
さて、少しAdvancedな内容として、ReadableStreamの二つの状態について話をしておきましょう。あなたがStream APIをより効果的に活用するなら、知っておかなければならないトピックです。といってもそれほど難しいことはありません。ただ、少し暗黙的な動作が入ってくるため、はたから見ればこれらのAPIの動作は難しく見えることがあります。
さて、ReadableStreamの読み込みモードには二種類の状態があります。二つの状態はそれぞれ以下のものです。
- pausedモード
- イベントループにイベントは投げられますが、読み込みが終わった後もストリーム内のバッファにデータは保持されます
- あなたがもしデータを取得したい場合、readを手動で呼び出せば、バッファからデータを取り出すことができます
- flowingモード
- データの取得後、自動的にデータがイベントに流れます
- あなたがもしデータを取得したい場合、'data'イベントと'end'イベントを監視するか、pipeでWritableを繋げるのがいいでしょう
デフォルトでは、ReadableStreamはpausedモードで取得されます。もし、flowingモードがデフォルトだった場合、あなたがデータを取得したいと思った時には、最初の幾つかのデータがどこかに消えているかもしれません。そのような事態を防ぐため、Readableは内部で取得した分を保持してくれているのです。さて、このモードは次のようなことをするとflowingモードに切り替わります。
'data'イベントにハンドラを登録するresume()メソッドを呼ぶpipe()メソッドにWritableを渡す
このため、あなたは特にこの二つのモードを意識せず、データを取得することができます。あなたがもしpausedモードに戻したければ、次に該当することを行えば切り替わります。
pipe先が無い場合は、pause()メソッドを呼ぶpipe先が存在する場合、全ての'data'イベントハンドラを外し、全てのpipe先をunpipeする
flowingモードへの切り替えに比べ、少々厄介ですね。まあ、大体のケースではflowingモードからpausedモードに差し戻す必要はないため、あなたはそれほど心配をしなくていいでしょう。
詳細については、Node.jsのドキュメントを見てみるといいでしょう。もし、あなたのストリームがうまく作動しない場合、上記のことを思い出してみてください。あなたがちゃんとストリームを扱っている場合、実装側のバグによるところが多いでしょう。その場合そのライブラリがちゃんと二つのモードを扱えているか、確認してみるのがいいでしょう。
オブジェクトモード
さて、Streamの本来の内部データは、Bufferが基本です。I/O操作はシステムとのバイナリ通信が基本だからです。しかしながら、ストリームの内部データとしてオブジェクトを持ちたい時があります。特に、次の様なことをしたい時は頻繁に起こるでしょう。
+----------------+ Buffer +-------------+ Object +----------+
| FileReadStream | -------> | ParseStream | -------> | Analyzer | ...
+----------------+ +-------------+ +----------+
つまり、ファイルのある一定の位置まで分かっていればパース処理ができるような、データフォーマットのデータを解析し、そのデータに対してそれぞれ独立したピュアな解析処理ができる場合です。例えばCSVの各行をJSONに変換し、その上で順に画面に表示していく場合、オブジェクトをストリームで扱えば独自に処理をしなくて済みます。しかしながら、Stream APIはBufferが基本であり、Bufferのために処理に最適化を入れている部分もあるため、当初Stream APIがオブジェクトを扱えるべきかについては慎重でした。Bufferは複数のBufferを結合してもBufferです。それに対してオブジェクトは複数扱う場合一旦配列にしなければなりません。
ただし、需要が大きかったこともあり、現在はobjectModeというものがStream APIに搭載されています。Stream APIの各基底クラスにobjectModeを有効にしたオプションを投げれば、Streamがオブジェクトを扱う様になります。デフォルトでは無効になっており、オブジェクトは扱えないことに注意してください!
const Readable = require('stream').Readable;
class RangeReadable extends Readable {
constructor(n) {
super({
objectMode: true,
});
this.state = 0;
this.max = n;
}
_read() {
if (this.max === this.state) {
this.push(null);
return;
}
this.push(this.state++);
}
}
/** Bad:
new RangeReadable(10)
.pipe(process.stdout)
;
*/
new RangeReadable(10)
.on('data', n => console.log(n))
;
オブジェクトを流す場合は、流すストリームはもちろんのこと、受け取るWritableもobjectModeである必要があることに注意してください!このため、process.stdoutに直接データを流すことはできません。もしデータを流したいなら、データを文字列に変換するTransformを作るといいでしょう。objectModeは他にも通常のストリームとAPIの仕様が少し異なったりするので注意が必要です。
しかしながら、あなたのストリームプログラミングをより豊かで便利なものにしてくれるでしょう。このobjectModeを使った強力なライブラリも幾つかあります。通常のストリームとの違いには注意しつつも活用していくといいでしょう。
Streamの活用例とライブラリ
Node.jsのStream APIは、Node.jsの至る所で活用されています。また、Stream APIのサポートを行っているライブラリも多くありますし、よりStream APIを便利に使うためのライブラリも多数用意されています。ここでは、そのうちの幾つかを紹介しておきましょう。
Node.jsが標準でストリームによって機能を提供しているモジュールは以下のものがあります。
- process.stdin: 標準入力を読むReadable
- process.stdout/process.stderr: 標準出力/標準エラーに書き込むWritable
- fs.createReadStream: ファイルの内容を読むReadableを取得する
- fs.createWriteStream: ファイルに内容を書き込むWritableを取得する
- http.get: レスポンス内容を読むReadableを取得する
- net.connect: ソケットを扱うためのDuplexを取得する
- zlib.createGunzip: Gzipを解凍するTransformを取得する
- zlib.createGzip: Gzip圧縮を行うTransformを取得する
色々ありますね。これで全てではありません。他にもいくつかあります。もちろん、ストリームでなくコールバック形式のAPIも同様に用意されています。これらをうまく使い分けていきましょう。
Stream APIの対応をしている有名なライブラリとしては、csv-stringifyやrequestなどがあります。また、gulpはオブジェクトストリームのヘビィユーザーで、vinylというオブジェクトをストリームに流すデザインを設計することで、とても扱いやすいAPIを提供しているビルドツールとして有名です。
また、ストリームの機能を拡張するものとして、次の様なライブラリも提供されています。
- merge-stream: ストリームのマージを行う
- through2: Transformをより扱いやすくしたもの
- event-stream: 様々なストリームユーティリティライブラリをまとめたもの
さらに詳細なことが知りたければ、Node.jsのStreamモジュールのドキュメントやStream Handbookを読んでみるのがいいでしょう。
RxJSのススメ
さて、Stream APIの使い方を今まで紹介してきましたが、Stream APIには、使用上注意しなければいけないことも、幾つかあります。
現状のStream APIの大きな問題点は、エラーハンドリングに関してです。次のコードを見てください。
const fs = require('fs');
const zlib = require('zlib');
fs.createReadStream('/path/to/some')
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream('/path/to/dest')
.on('error', err => {
// handling error
...
})
;
あなたは、エラーが発生した場合、そのエラーを受け取って特殊なエラーハンドリングを行わなければ、システムが壊れてしまうようなプログラムを書いていたとしましょう。あなたは、onでエラーをハンドリングしたと思っていますが、実際に何かしらのハードディスクトラブルでreadに失敗した場合、あなたのシステムは壊れるでしょう。Node.jsのStream APIがエラーを伝搬しないことによって、エラーハンドリングが直感的でないことは幾人かから既に指摘を受けていますが、諸事情により簡単に直せる問題ではありません。
Node.jsのエラーハンドリング事情については、StackOverflowのこのスレッドが参考になるでしょう。また、どういう経緯でこうなったのか、Stream APIの変遷についてはこの記事を読んでみると良いと思います(コメントで補足をもらいました。そちらも参照してください)。
また、もう一つの問題として使いにくさがあります。非同期コールバック、Promise、async/awaitと進化していった、一つの出力を持つ非同期体系に対し、Node.jsのStream APIは簡単に操作できるものではありませんし、様々なライブラリをimportする必要が出てきます。また、分岐や取得タイミングの調整についても、暗黙的な動作を採用してしまったために、かえって適切に調整することが難しくなっています。
そこで今日最後に紹介しておくのが、RxJSです。標準でサポートされている機能を蹴ってまで、RxJSを使う魅力があるのか、と思われる方も多いでしょうが、RxJSを操れるようになればその考え方は大きく変わるはずです。
RxJSの特徴は、多数のプリミティブなオペレータというものを提供していることと、HotとColdという概念によって、より効率良く的確にストリームのリソースを管理する方法を提供していることです。RxJSの主なストリーム処理のイメージは以下の様になります。
+------------+ +----------+ +-----------+
| Observable | >>> | Operator | >>> ... >>> | subscribe |
+------------+ +----------+ +-----------+
Node.jsのStream APIと同じ様な概念に見えますね!ObservableはReadable、OperatorはTransform、subscribeはWritableに対応します。では、それぞれを繋ぐ、pipeの役割はどのようなメソッドが持つのでしょうか?ここで、あなたはRxJSのサンプルコードを見た時、少し驚くかもしれません。
const rx = require('rx');
const rxNode = require('rx-node');
const fs = require('fs');
const source = rxNode.fromReadableStream(process.stdin)
.map(s => s.toString())
.map(s => s.replace(/\s/g, ''))
.filter(s => s !== '')
.map(s => Buffer.from(s, 'utf8'))
;
rxNode.writeToStream(source, process.out, 'utf8');
そう、オペレータとは、RxJSが常備しているメソッドのことです。そして、これらはとても多くのものが提供されています。このため、あなたはNode.jsのStream APIよりもRxJSがとてもユーザーフレンドリーで扱いやすいと思うようになるでしょう。
また、RxJSではありがたいことに、Stream APIで問題だった、エラーが伝播しない問題を解決します。あなたはPromiseのように好きな時にエラーを回収し、またエラーを投げ、はたまた最後にまとめてエラーハンドリングを行うことも可能なのです。さらにデフォルトでオブジェクトを扱う様できているため、あなたはobjectModeに関して気にする必要は全くなくなります。また、Hot/Coldの概念やSubjectをうまく使えば、効率良くストリームを分岐し、リソースを管理することができます。
もし、あなたがRxJSに興味を持ったなら、ぜひ使ってみてください。なお、RxJSは現在バージョン5が出ており(まだ5.0.0リリースから一ヶ月も経ってない気がしますが。ついでに、このサンプルはバージョン4のものです ![]() )、多数のAPIの変更がありました。おそらく古い資料も多いので、あなたがもし5から始めたいのなら、Learn RxJSを参照してください。
)、多数のAPIの変更がありました。おそらく古い資料も多いので、あなたがもし5から始めたいのなら、Learn RxJSを参照してください。
最後に
Node.jsにおける、非同期処理のためのAPIを色々見てきました。そして、その中でのStream APIと使い方、そしてStream APIのデメリットとRxJSが解決してくれる点について書きました。
それぞれの使い分けをしながら、高パフォーマンスで且つ使いやすいプログラムを書いていけるといいですね。
なお、この記事では非同期処理だけを念頭に置いてきましたが、上述の通り非同期処理は魔法でもなんでもなく、ただ単なるシングルスレッドで動くイベントループです。あなたがもし非常に重たい処理を行う場合、非同期処理は何の助力にもなってくれないでしょう。
そのような場合、あなたは計算のパフォーマンスを最大限引き出すため、クラスタ化を行っておく必要があるでしょう。clusterモジュールやthrongなどの導入を検討する必要があります。
Node.jsが、シングルスレッドで非同期処理を、簡単に利用できるようにしているからといって、並列処理が必要なくなるわけではありません。並列処理と非同期処理、それぞれを使い分けながらプログラミングを行うことは、あなたのプログラムをより快適に動作させるでしょう。
では、よい非同期ライフを!
(イラストには、いらすとやさんの画像を遣わしていただきました。毎度お世話になっています。ありがとうございます)
親しみやすいようpollにしましたが、実際には環境にあった最適のシステムコールが実行されることになります ↩
最近、最新のに追いついてる分かりやすい記事を読んだんですがURLを忘れてしまった・・・誰か、もっといい記事があったら紹介してもらえると助かります ↩
実際にはデッドロックやメモリリーク、インスタンスの破壊などのバグが発生しないよう、共有インスタンスの扱いには注意する必要があるでしょう ↩
jQueryではDeferredという名前で、現在のES2015に取り入れられているPromiseと、中身が少し異なりますが、広義にはPromiseとして扱われます ↩
Generatorがどういうものか分からないという方は、まず次の項目を見てから戻ってきた方がいいかもしれません ↩
このヘルパーは、TypeScriptのものを、余計なところを省いて、この処理向けに特殊化し、分かりやすくしたものです ↩
もちろん、データの表現値としての限界はありますが ↩
'C Lang > JS Technic' 카테고리의 다른 글
| gulp (0) | 2018.09.26 |
|---|---|
| javascript로 guid발급 (0) | 2018.09.08 |
| 파라미터의 유효성체크(validation check of parameter) (0) | 2018.08.31 |
| async-await, async-await를 사용한 비동기처리와 generator-yield를 사용한 비동기처리의 차이 (0) | 2018.08.27 |
| in 연산자 (0) | 2018.08.23 |