인과관계란 두 개 혹은 그 이상의 변수 간의 원인과 결과의 관계를 의미한다. 이때 변수란 대상이 될 수도 있고 사건이 될 수도 있다.(단어가 변수가 될 수도 있고, 문장이 변수가 될 수도 있다)
변수들이 형성하는 다양한 관계 중 인과관계는 비즈니스면이던 과학면이던 가장 중요한 관계로 다루어진다.
인과관계를 이야기할 때 因이 되는 부분을 근거, 원인, 이유 등으로 부르기도 하는데, 근거, 이유란 행동이나 언행이 결론에 이르게 된 까닭, 원인이란 ‘어떤 사물이나 상태를 변화시키거나 일으키게 하는 근본이 된 일이나 사건’을 의미한다.
이처럼 ‘원인’은 일이나 사건을 가리킨다는 점에서 객관적인 사실을 묻는 데 반해 ‘근거, 이유’는 다소 주관적인 사실을 묻는다는 데에 차이가 있다고 할 수 있다.
가설과 인과관계
가설이란 둘 이상의 변인들 간의 관계에 관한 일종의 추측이다. 이때, 관계란 인과관계, 상관관계, 대등관계, 포함관계, 양의관계, 음의관계 등 다양한 관계를 포괄한다.
따라서, 쉬운 말로 하면 인과관계가 아직 검증되지 않았다면 인과관계 자체가 가설이다. 증명되지 않은 인과관계는 가설에 포함되고, 증명된 인과관계는 참인 명제, 사실이 된다.
가설을 통해서 두 변수 간의 관계를 효과적으로 증명할 수 있다.
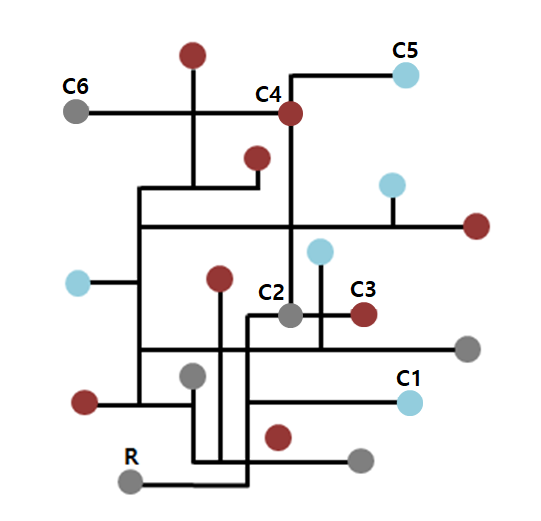
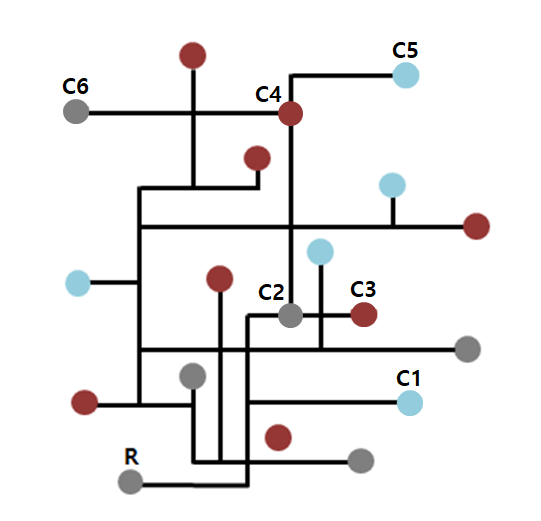
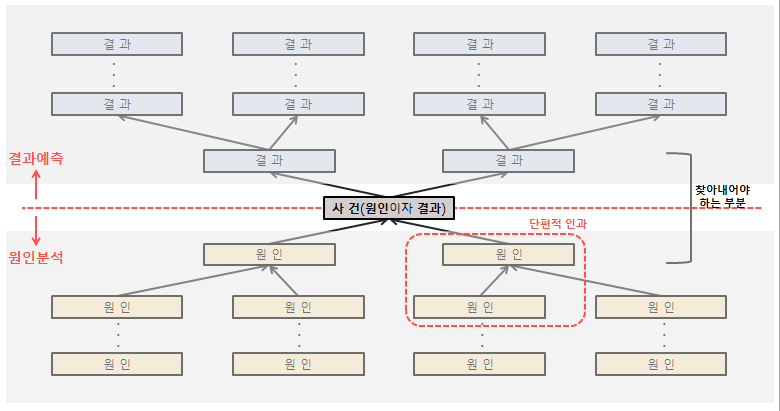
위의 그림에서 R이라는 결과에 기인한 모든 원인을 찾아내는 것은 매우 비효율적고 힘든 일이다. 결과에서 원인을 찾아내는 방향이 아니라 원인에 대해 추측하고 이러한 원인 때문에 그러한 결과가 도출된 것은 아닐까라고 역발상하는 것이 가설의 힘이다. 가설에 대한 구체적 내용은 다음의 링크에서 확인할 수 있다.
인과관계의 타당성 검증
인과관계가 타당성을 갖기 위해서는 아래의 3가지 조건이 만족되어야 한다.
시간적 우선순위(time order)
원인이 되는 변수가 먼저 변화된 후에 종속변수의 변화가 이루어져야 한다는 것이다. 독립변수가 종속변수에 영향을 미치는 것이므로 독립변수의 강도(수준) 변화가 먼저 일어나야 하는 것은 당연한 이치이다. 많은 사람들은 흡연(독립변수)이 폐암(종속변수)의 주된 원인으로 생각하고 있다. 시간적인 우선순위의 가정은 장래의 사건이 과거나 현재의 사건을 결정할 수 없다는 사고에서 비롯되었다고 할 수 있다. 예컨대 음주행위는 취하게 되는 원인으로 시간적으로 취한 결과에 대하여 우선하는 것을 누구나 쉽게 알 수 있다.
시간적 우선순위가 성립하지 않는 가설의 예로, 일이 없어서 일을 하지 않는다 라는 가설이 있다. 이는 일이 없다라는 변수와 일을 하지 않는다라는 변수 사이에 시간적 우선순위가 성립하지 않는다. 일을 하지 않아서 일이 없는것인지, 일이 없어서 일을 하지 않는 것인지 판단할 수 없다.
동시발생조건(concomitant variance)
병발발생조건은 원인변수(독립변수)와 결과변수(종속변수)의 값이 둘 다 변화해야 한다는 것이다. 독립변수나 종속변수 중의 어느 하나가 변하지 않고 고정되어 있으면 두 변수간의 인과관계는 성립될 수 없다. 이를 통계적으로 검증하기 위해서는 얻어진 자료의 변화가 서로 공분산 정도 또는 상관관계가 존재해야 하는데 이 때 상관도가 통계적으로 유의성이 있어야 하는 동시에 그 강도가 일정한 수준 이상으로 크게 나타나야 한다. 예를 들어, 지능지수(IQ)가 높은 학생의 성적이 우수하다면 지능지수는 성적의 원인이 될 수 있다.
다만 동시발생 조건에서 주의해야 할점은 인과관계가 존재하면 상관관계도 존재하지만, 상관관계가 존재한다고 인과관계가 반드시 존재하지는 않는다는 것이다.예를 들어, 목사의 수와 주정뱅이의 수가 양의 상관관계가 있다는 것을 발견한 통계학자가, 「주정뱅이가 늘었기 때문에 목사의 수가 늘었다」라는 인과관계를 주장했다. 이는 상관관계를 인과관계로 판단한 대표적인 오류로, 단순히 인구가 증가하여 주정뱅이도, 목사의 수도 늘어난 현상을 인과관계로써 옳지 않게 해석한 대표적인 예다.
외생변수의 통제(control extraneous variables)
인과관계는 원인변수인 독립변수 이외의 결과변수인 종속변수에 영향을 미칠 수 있는 제 3의 변수의 영향을 제거한 상태에서 독립변수와 종속변수간의 관계가 검증되어야 한다. 제 3의 변수를 통제한 후 독립변수와 종속변수 간의 관련성을 비허위성 이라고 한다. 일반적으로 실험연구에서 외생변수가 독립변수와 종속변수에 미치는 영향을 제거해야 독립변수와 종속변수 사이의 인과관계를 정밀하게 파악할 수 있다. 인과관계가 성립하기 위해서는 제 3의 변수로 설명할 수 있는 허위적인 관계가 존재해서는 안된다.
[예1]
가설1: 20~40대 중 한 달에 한 번 이상 택시를 타는 비율은 30%이다.(두 변인간의 관계를 나타냄)
가설2: 내 주변 친구들 10명중 3명정도는 한 달에 한 번 이상 택시타기 때문에, 20~40대 중 한 달에 한 번 이상 택시를 타는 비율은 30%이다.
(가설2는 가설1을 결론으로 하는 인과관계에 대한 가설)
가설2에 대해 위의 3가지로 타당성을 검증
- 시간적 우선순위: 나의 감각치가 형성된 이후 가설이 존재하므로 타당하다.
- 동시발생조건: 내 주변 친구들이 택시를 타는 횟수가 늘어나면 20-40대 전체의 택시 타는 횟수가 증가하는가?
➡거짓.
- 외생변수 통제: 경제력, 성향등의 외생변수를 모두 통제할 경우에도 위의 가설2가 성립하는가?
➡거짓. 경제력은 가설2의 인관관계에 영향을 미치는 주요 변수중 하나. 따라서, 20-40대를 유효한 축으로 나눌 필요있음. 경제정도라던가.
이때 주의할 점은, 가설2에 대한 타당성을 검증하더라도 어디까지나 가설2에 대한 증명이지, 가설1이 참인지 거짓인지는 증명되지 않는다.
가설2는 가설1이 참임을 전제로 하고 만들어진 가설이다. 가설1을 증명하기 위해서는 별도의 과학적 방법을 통한 조사와 연구가 필요할 것이다.
따라서, 나의 감각치라는 근거는 타당하지 않다.
(Appendix)명제의 타당성 검증
인과관계와 직접적인 연관은 없지만, 실전에서 인과관계의 타당성을 검증할 시 유용하게 사용되는 방법이다. 인과관계란 두 명제 간의 관계인데, 애초에 어느 한 쪽의 명제가 사실이 아니라면 인과관계도 성립되지 못한다. 따라서, 명제의 사실여부가 인과관계의 타당성 검증보다 우선되어야 하는 검증이다.
최근 프로젝트에서 상대측 변호사가 아래와 같은 주장을 해왔다. 순자산가치로 자산 매각 -> 공정가치와 순자산가치와의 차액 발생 -> 배임과 같은 형사상 리스크 발생
언뜻 보면 순자산가치로 자산 매각 -> 공정가치와 순자산가치와의 차액 발생의 인과도 공정가치와 순자산가치와의 차액 발생 -> 배임과 같은 형사상 리스크 발생인과도 꽤나 높은 확률의 인과처럼 보이기 때문에, 설득력있는 주장인 것 같지만, 각 명제의 타당성을 검증해보면 옳지 않은 주장이라는 것을 알 수 있다.
문제가 되는 명제는 공정가치와 순자산가치와의 차액 발생 인데, 기업의 공정가치란 경우에 따라서 여러가지 벨류에이션에 의존할 수 있는 가치이기에 옳은 명제일 수도 있고, 틀린 명제일 수도 있다. 예를 들어, DCF와 같은 벨류에이션을 공정가치로 인정하게 되면 해당 명제는 사실이 되지만, 보충적 평가방법과 같은 벨류에이션을 공정가치로 인정하게 되면 해당 명제는 거짓이 된다.
우리 측에서는 해당 명제의 거짓을 규명하는 로직을 통해 상대의 로직을 격파할 수 있었다.
인과관계 분석의 3가지 시점: 구조화構造化심화深化세분화細分化
인과관계의 구조화
인과관계의 구조화란, 果의 원인이 되는 因을 MESE로 구조화하여 누설없이 파악하는 것이다. 인과관계의 심화와 인과관계의 세분화가 잘되어도 인과관계의 누설이 존재하면 인과관계 분석에 치명적인 허점이 생긴다. 구조화의 방법은 다음의 링크에서 확인할 수 있다.
유럽 지역의 사입코스트가 높은 원인 분석
사입코스트 = 원재료코스트 + 중간 수수료 코스트 + 운송코스트
사입코스트-----┌원재료코스트─ 안전기준이 높아 원재료 가격 자체가 높다.
상승요인 |
|
├중간 수수료 코스트─ 중간 수수료 가격 : null
| └ 중간 수수료 횟수 : 안전기준이 높아 프로세스가 복잡하다.
|
└운송코스트─ 중국과의 거리가 멀어 운송코스트가 비싸다.
└ 땅덩어리가 넓어 운송코스트가 비싸다.
인과관계의 심화
인과관계의 심화란 원인에 대해 why so?의 질문을 반복해가며 가장 깊은 곳에 존재하는 핵심적인 원인을 파악해내는 것이다.
위의 Why 트리에서 제품배송 문의 증가가 콜센터 VOC의 증가로 이어졌다 라는 가설은 반은 맞고 반은 틀렸다. 제품배송 문의 증가는 핵심적인 원인이 아니기 때문이다. 피상적인 원인은 문제해결에 아무런 도움이 되지 않는다. 그에 대한 원인을 더 깊게 파고들어가면, 배송기사 부족문제가 있고 이를 더욱 파고 들어가면 배송기사 낮은 지원률과 높은 이탈률 ← 배송기사에 대한 낮은 처우와 같은 핵심적인 문제의 원인에 다다를 수 있다. 이처럼 문제의 원인을 더욱 깊게 파고 드는 것을 인과관계의 심화라고 한다.
앞서 보여준, Why트리에서 세로축이 구조화의 양이라면, 인과관계의 심화는 가로축을 넓혀가는 것을 의미한다.
인과관계의 세분화(프로세스 사고)
인과관계의 세분화란 이미 설정된 인과 사이를 더욱 잘게 쪼개보는 것이다. 인과관계를 더욱 촘촘히 분해해 분해된 인과의 가능성을 평가하는 것이다. 이때 촘촘히 분해된 인과사이에 가설적 확률을 부여함으로써, 인과의 타당성을 수치화할 수도 있다.
인과관계의 세분화의 장점
불분명한 인과관계에 대한 납득이 가능해진다. 이는 특히 인과관계에 관한 가설에 대해 대략적인 근거(실제 검증 前)를 제시할 때 유용하게 활용된다.
1. 가설: 금리가 상승했기 때문에, 부동산 가격이 하락할 것이다.
금리가 상승했다.
(100%) -> 대출 금리가 상승했다.
(80%) -> 돈을 빌리면 갚아야 되는 돈이 많아진다.
(100%) -> 대출이 감소한다.
(80%) -> 부동산 구매력이 하락한다.
(100%) -> 부동산 수요가 감소한다.
(100%) -> 부동산 가격이 하락한다.
1 * 0.8 * 1 * 0.8 * 1 * 1 = 0.64 = 약 64%
2. 가설: 원유값이 하락하여, 베스킨라벤스의 드라이아이스 제공량을 줄일 것이다.
원유값 하락
(90%) -> 원유제조 공장의 가동률 하락
(100%) -> 원유제조 공정에서 획득되는 이산화탄소량 하락
(90%) -> 인산화탄소를 원료로하는 드라이아이스의 생산 하락
(90%) -> 드라이아이스 구매가 어려움
(90%) -> 베스킨라벤스의 드라이아이스 제공량 하락
0.9* 1 * 0.9 * 0.9 * 0.9 = 0.64 = 약 65%
3. 가설: 인기없는 소프트드링크의 종류를 줄이면, 매출이 상승할 것이다.
인기없는 소프트드링크의 종류를 컷
(100%) -> 인기있는 소프트드링크의 진열 스페이스 증가
└(70%) -> 고객이 소프트드링크를 선택하기 쉬워짐
(80%) -> 소프트드링크의 매출증가
└(100%) -> 상품이 소진될 가능성이 줄어듬
(70%) -> 소프트드링크의 매출증가
인과관계의 타당성을 따지기 쉬워진다.
가설: 해변에 놓여진 출입 금지 팬스를 제거 했기 때문에, 2명의 익사자가 발생했다.
해변에 놓여진 출입 금지 팬스 제거
(80%) -> 해변에 입장
(3%) -> 바다에 입장(안개가 자욱하고 파도가 거셀시)
(10%) -> 익사
0.8*0.03*0.1 = 0.0024 = 약0.24%
「해변에 놓여진 출입금지 팬스 제거」➡「익사」라는 인과관계의 타당성을 검증하는 것보다
「해변에 놓여진 출입금지 팬스 제거」➡「해변에 입장」이라는 인과관계의 타당성을 검증하는 것이 쉽다.
인과관계와 상관관계
한 변수가 변할 때 다른 변수도 변한다면 두 변수 사이엔 상관관계가 있다고 볼 수 있다. 그러나 상관관계에서의 두 변수 사이엔 인과적 선후관계가 없다.
상관관계를 인과관계로 오해하기 쉽다. 인관관계의 타당성 검증을 통해 이러한 논리적 결함을 방지할 수 있다.
[예1]
어떤 제품이 가격이 낮고 시장점유율이 높은 경우를 생각해보자. 이 결우 가격이 낮아서 시장 점유율이 높아졌는지, 혹은 높은 시장점유율로 인해 규모의 경제가 나타나 가격이 낮아졌는지 명확하게 알수 없다.
[예2]
모기를 많은 해에는 아이스 크립 매출이 많아진다?
2007년에는 모기가 유달리 많았다. 그래서 한 단체에서 통계치를 내던중 놀라운 사실이 발견되었다
2002년 2003년 2004년 2005년 2006년 2007년 아이스크림과 모기의 수의 관계는 정확히 양의 상관 관계를 띠고 있었다.
인과루프 사고
인과루프 사고는 논리적 사고의 확장된 형태이다. 논리적 사고는 원인-결과의 관계를 명확히 하는 것을 의미한다. 인과루프 사고는 논리적 사고를 기반으로 나아가서 Reason-Result Web을 전체적으로 파악하는 사고이다.
인과관계를 생각할 때는, 보통 단편적인 인과관계만을 고려하기 쉽다. 이것이 속히 말하는 머리 좋다는 사람과 범인의 차이이다. 전체적인 인과관계는 복수개의 단편적 인과관계의 연결로 이루어져 있다. 어떠한 인과간계든지 간에 전체적인 인과관계의 망을 머리 속에 그려놓고 단편적인 인과관계는 전체적인 인과관계 망 속에서 겨우 한 부분에 속하지 않음을 인지할 필요가 있다.
예를 들어, A빌딩이 붕괴되는 사건이 발생했다. 이에 대한 원인 중 하나로 관리감독에 허점이 있었다는 가능성에 대한 가설을 제시할 수 있다. 또한 A빌딩 붕괴로 인한 결과로 대통령 탄핵이라는 가설을 제시할 수도 있다. 각 가설의 가능성은 실제 검증전 아래와 같은 인과관계의 세분화로 추측이 가능하다.
가설: 관리감독의 허점 -> A빌딩이 붕괴
관리감독의 허점
(70%) -> 건축규정 위반(낮은 질의 자재사용, 부실설계)
(100%) -> 예측 보다 빠른 노후화
(100%) -> 건물 붕괴
가설: A빌딩이 붕괴 -> 대통령 탄핵
A빌딩이 붕괴
(100%) -> A빌딩의 시공사와 정치인B 간의 정경유착 발견
(100%)-> 정치인B와 대통령 친인척 간의 유착 발견
(100%)-> 현 대통령이 친인척에게 유착 지시 포착
(40%)-> 국민들의 탄핵운동
(70%)-> 대통령 탄핵
가설이란: 현실적이고 간단한 정의로는 "개별 사건이든 사건 間의 관계이든 아직 증명되지 않은 것"을 의미한다. "너 아직 밥 안먹었지?" "너 그거 거짓말이지?" "저 여자는 나쁠 거야" "저 남자는 바람을 피고 있을 거야" "어제 밥에 라면을 먹어서 오늘 배가 아픈가?" 와 같이 데이터처럼 과학적 방법으로 증명되지 않은 것들은 모두 가설이라고 할 수 있다.
학문적 정의로는, 둘 이상의 변인들 간의 관계에 관한 일종의 추측이다. 이때, 관계란 인과관계, 상관관계, 대등관계, 포함관계, 정적관계(양의 관계), 부적관계(음의 관계) 등 다양한 관계를 포괄한다. 변수란 대상 혹은 사건이 될 수도 있으며, 이는 변수가 단어나 문장으로 표현될 수 있음을 의미한다.
둘 이상의 변인 또는 현상 간의 관계를 설명하는 검증되지 않은 명제라고 정의하거나, 또는 연구의 문제에 관해 검증할 수 있도록 기술된 잠정적인 응답이라고 정의할 수 있다. 이러한 가설은 일반적으로 독립변인과 종속변인 관계의 형태로 표명된다. 가설은 여러 개를 세우는 것이 가능하다.
과학적 사실 혹은 거짓을 증명하기 위해서는 가설을 되도록 엄밀하게 정의하지만, 비즈니스 측면에서는 가설을 엄밀하게 정의하지 않고 문제에 대한 임시적인 답을 미리 설정하는 것정도로 생각하면 된다.
가설은 반드시 두 변수 도는 그 이상의 변수간의 관계를 미래형으로 진술되어야 한다. 조사 연구나 사례연구에서와 같이 연구 목적이 단순한 현상의 서술에 있을 때에는 문제 진술만 있고, 가설이 필요없다. 가설이 되기 위한 문장으로서 첫째, 가설은 변수로 구성되어야 하며 그들 간의 관계를 나타내고 있어야 한다.둘째, 가설은 검증될 수 있는 것이어야 한다.
가설은 주로 귀납적 추리를 통하여 이미 알려진·개별적 자료들을 대비유추하고 일반화한 데 기초하여 설정된다. 그리고 그것은 주로 연역적 추리를 통하여 가설로부터 끌어낸 논리적 귀결이 현실과 부합되는가 하는 것이 검증됨으로써 진리로 확증된다. 물론 가설은 어디까지나 결론을 이끌어내고 그것을 검증하기 위해 설정된 도구이자 통로이지 결론 그 자체는 아니므로 그후의 오랜 기간의 수많은 이론적 사유와 실험적 검토를 통하여 논박되고 이론을 피지 못할 수도 있다. 이때에는 그 가설 대신에 다른 새로운 가설이 설정되고 검증되는 과정을 통하여 진리의 발견으로 나아가게 된다.
따라서 가설이란, 어떤 문제 상황에서 자신의 인지 구조(기존의 생각들)에 의해서는 해결할 수 없는 문제에 직면했을 때, 인지 구조는 혼란이 일어나게 되며, 이 인지적 비평형 상태를 극복하고 새로운 인지적 평형 상태로 돌아가려는 욕구가 작용하여 만들어진, 어떤 문제에 대한 임시적 해답이나 해결책이다. 가설 설정은 문제 발상과 함께 일반적으로 창의력이 가장 많이 요구된다.
가설적 사고란?: 증명되지 않은 사실이나 사실간의 관계에 대해 증명된 사실이라고 가정하고 논의를 전개해 나가는 것이다.
가설적 사고의 목적
각 원은 인간 세상의 눈에 보이는 현상이고, 선은 현상관의 관계이다.
당신은 세상의 모든 현상 간의 관계를 꾀뚫고 있는 신이다. 신인 당신은 위 그림처럼 현상 간의 관계가 모두 보여서, R이라는 결과의 원인은 C1, C2, C3라는 것을 알고 있다. 신에게는 현상(원)을 잇는 관계(선)가 보이고, 인간에게는 현상(원)은 보이지만 관계(선)는 보이지 않는다.
반면 아무것도 모르는 인간은 각각의 현상만 보인다. R이라는 결과가 왜 나온건지 그 원인은 알 수 없다. 각 현상들은 보이지만 그 관계가 어떻게 이루어져 있는지는 보이지 않는 인간들에게 모든 현상 간의 관계를 조사해보기에는 너무도 복잡하고 힘든 과정이다.
이때 놀라운 통찰력을 가진 천재가 등장한다. 이 천재는 놀라운 직관으로 'C5이기 때문에 R인 것은 아닐까'라고 가설을 세운다. 천재는 C5의 요소에서 R까지의 관계를 하나하나 조사해가며 맞춘다. C5 -> C4 -> C2 -> R. 천재는 C5가 R의 원인임을 알게 되었다.
만약 가설적 사고가 없다면, 위 그림의 모든 요소들간의 관계를 하나하나 고려해보아야 할 것이다. 이는 극히 비효율적이다. 가설적 사고는 주로 사건의 원인파악사건의 결과추정에 사용된다. 가설적 사고를 통해 원인파악과 해결방안에 더욱 빠르게 어프로치 할 수 있다.
가설적 사고의 2가지 적용: 1. 변수(사건)에의 가설 적용 2. 변수사이의 관계에 가설 적용
가설은 변수(사건)자체에 적용할 수도 있고, 변수 사이의 관계에도 적용할 수 있다.아래와 같은 변수(사건)과 변수 사이의 인과관계를 예로 들어보자.
한국은 재생 에너지 빈국(원인변수) ----(인과관계)----> 재생 에너지 부국인 호주로부터 수입량을 늘일 것(결과변수)
변수(사건)에의 가설 적용 아직 한국이 재생에너지 빈국인지 어떤지 증명되지 않은 상태에서 위의 논리가 나왔다면 변수 자체가 아직은 사실이 아닌 가설에 해당하는 것이다. 여기에서의 시사점은 가설이란 반드시 인과관계에 적용되는 것이 아니며 변수 자체에도 가설이 적용될 수 있다는 것이다.
변수사이의 관계에 가설 적용 원인과 결과 간에 인과관계가 존재한다는 사실이 아직 증명되지 않았음에도 불구하고, 존재한다고 가정하는 것이다. 내가 일반적으로 알고 있던 가설의 적용처다.
가설적 사고의 증명: 1. 변수(사건)의 사실 증명 2. 변수사이의 관계 증명
한국은 재생 에너지 빈국(원인변수) ----(인과관계)----> 재생 에너지 부국인 호주로부터 수입량을 늘일 것(결과변수)
1.원인 변수(사건)의 사실 증명 2.결과 변수(사건)의 사실 증명 3.원인과 결과 관계의 인과관계에 대한 사실 증명
1.원인 변수(사건)의 사실 증명: 한국은 정말 에너지 빈국이 맞는지 사실을 증명해야 한다.
2.결과 변수(사건)의 사실 증명: 호주는 정말 에너지 부국인지, 수출량은 충분한지 증명해야 한다.
3.원인과 결과 관계의 인과관계에 대한 사실 증명: 원인측과 결과측의 사실이 증명되었다면 비로소 인과관계에 대한 가설을 증명할 때가 되는데, 한국이 에너지 빈국이라고 해서 에너지 부국인 호주로부터 수입이 가능한지? 다른 나라로 부터 주로 수입하는 건 아닐지, 재생에너지 빈국이지만 원자력으로 해결하려는건 아닐지와 같은 데이터를 통해 인과관계를 증명해야한다.
가설적 사고의 최고 궁합 파트너: 비판적 사고
비판적 사고는 가설적 사고를 더욱 완벽히 한다. 아무리 천재여도 모든 경우의 수를 고려할 수 없는 한, 가설의 예외와 마주하게 된다. 예외가 존재한다는 것은 그 가설이 100% 옳지 않음을 의미하며 가설의 개선 Room을 의미하기도 한다. 가설을 세우고 증명한 후, 비판적 사고를 통해 가설이 옳지 않은 경우의 수를 제안하면, 가설은 그러한 반례를 커버하기 위한 더욱 좋은 가설로 발전하게 된다.
예를 통한 가설의 이해
위의 가설에 관한 정의는 교과서적인 정의다. 그냥 그렇구나하고 넘기길 바란다. 뜬 구름잡는 이해를 명확히 하기 위해 실무와 생활에서 가설을 사용하는 아래의 씬들을 상상해보자.
예1
A클라이언트가 살균기 시장에 진입하려고 하는데, 어느 시장에 진입하는 것이 가장 좋을까? 시장은 지역별로 북미, 동남아, 아프리카, 유럽, 남미시장이 존재하고, 상품별로 공기살균기, 표면살균기, 물살균기 시장이 존재한다.
망라적 사고의 어프로치
모든 시장의 시장조사, 경쟁환경 조사, 고객환경 조사, 시너지를 조사
각 시장별 조사결과를 비교 후 선정
망라적 사고는 모든 것을 조사해야 하므로 시간과 에너지가 많이 든다. 하지만, 누락없이 전체를 볼 수 있다는 장점이 있다.
과제: 어느 살균기 시장에 진입하는 것이 좋을까?
↓
초기가설: 동남아시아의 물살균기 시장에 진입하는 것이 좋다.
↓
가설검증: 논점에 맞추어 조사를 시행한 결과, 동남아시아는 구매력이 낮아 시장 성장율이 더디다.
↓
수정가설: 중국의 공기살균기 시장에 진입하는 것이 좋다.
↓
가설검증: 시장규모/성장율 OK, 경쟁사의 제품차별성 없음, 고객의 구매력 있음, 기존 물살균기를 생산하는 중국 생산공장이 있으므로 시너지 OK
가설적 사고는 타게팅한 목표에 대해서만 조사하며 접근하므로, 답을 효과적으로 찾을 수 있다. 하지만, 위의 가설적 사고의 프로세스에서 눈치챘듯, '혹시 중국 공기살균기 시장보다 남미의 공기살균기 시장이 더 매력적이면 어떻게하지?'라는 반론이 재기될 수 있다. 이처럼, 가설적사고는 전체를 망라적으로 보지 않으므로 판단 누락이 존재하는 단점이 있다.
예2
정보의 평등화가 진행되어, 이전에는 소수만 독식하던 정보에 이제는 누구나 접근할 수 있다. 하지만, 중요한 것은 정보에 접근할 수 있느냐 아니냐의 문제가 아닌, 정보를 어떻게 해석할 것인가, 정보를 통해 어떤 결과를 도출할 것인가이다. 황금알과 같은 정보를 접해도, 정보 해석의 문제에 따라 종잇조각 이상의 가치도 없을 수 있다. 가설적 사고는 정보의 해석에 있어서 탁월한 통찰력을 발휘할 수 있는 사고법이다. 다음의 예를 보자. 「20~30대의 빚투현상」 최근 신문에서 읽은 기사다. 이러한 현상은 어떠한 결과를 낳을까?
망라적 사고의 어프로치
「20~30대의 빚투현상」은 어떠한 결과를 낳을지를 생각하면, 너무 방대하여 사고 어프로치의 방향성이 정해지지 않는다. 이것이 망라적 사고의 가장 큰 문제이다.
가설적 사고의 어프로치
그럼 이번에는 가설적 사고로 어프로치해보자. 가설적 사고는 최종목적 논점(결론)을 정하는 것이 그 시작점이다. 2030대의 빚투현상은 주식시장의 하락을 가져온다라는 가설을 세웠다. 이제 남은 것은 `20\30대의 빚투현상이라는 원인과주식시장의 하락`이라는 결과 사이의 세부적인 인과관계 가설을 설정하고 그 확률을 생각해보면 된다. 결론이 정해진 것 하나만으로 사고 어프로치가 명확해진다. 가설을 설정하면, 최종 결론에 다다르기 위해서 어떠한 논점을 고려해야하는지 큰 그림이 잡힌다.
20~30대의 빚투현상
(100%)-> 채권의무 발생
(40%)-> 1~2년 내에 의무 상환 금액 증가
(40%)-> 주식 처분을 통한 상환 금액 마련
(100%)-> 주식 시장의 유동성 하락
(100%)-> 주가 하락
위에서는 채권의무 발생-> 1\~2년 내에 의무 상환 금액 증가-> 주식 처분을 통한 상환 금액 마련-> 주식 시장의 유동성 하락 이라는 논점을 마련하여, 20\~30대의 빚투현상은 주식시장의 하락을 가져온다라는 가설의 타당성을 고려해보았다. 하지만 1~2년 내에 의무 상환 금액 증가와 주식 처분을 통한 상환 금액 마련이라는 가설은 신용대출의 상환기간은 3~5년정도가 아닐까?, 주식처분을 통한 상환 금액을 마련하는게 아니라, 주식에 있는 돈은 가만히 두고 그동안 벌었던 월급이나 또 다른 대출을 통해서 상환하지는 않을까? 라는 반론의 제기를 통해 가설을 수정할 수 있다. 가설의 수정을 계속적으로 반복하면, 인과관계의 확률이 높은 최종 가설을 마련할 수 있다.
가설의 종류
단순가설과 복합가설 단순가설(simple hypothesis)이란 하나의 독립변수와 하나의 종속 변수간의 기대되는 관계만을 표현한 가설을 말하며, 복합가설(complex hypothesis)은 둘 또는 그 이상의 독립변수와 둘 또는 그 이상의 종속변수 사이의 관계에 대해 가설을 설정한 가설을 말한다. 여러 개의 독립변수로 하나의 현상을 더 잘 설명할 수도 있으며 하나의 독립변수가 여러현상을 설명할 수도 있다.
지시적 가설과 비지시적 가설 지시적 가설(directional hypothesis)은 ‘A가 B보다 클 것이다.’등으로 비교급을 사용하여 변수간의 관계에 대해 기대되는 방향을 제시하는 것이다. 지시적 가설은 특정 검증방향을 결정해줌으로 연구자나 독자에게 분명한 관계를 제시하고, 사용하는 분석방법도 비지시적 가설에 비해 엄격한 방법, 즉 one-tailed test(단측)를 사용하게 된다. 이 가설은 명확한 이론적 근거가 있으나 선행연구에서 그 방향을 제시하고 있을 때, 흔히 사용하는 방법이다. 한편 비지시적 가설(nondirectional hypothesis)은 반대로 관계의 방향을 규정짓고 있지 않다. 이러한 가설들은 관계의 성질을 구체화하지 않고 두 개 또는 그 이상의 변수들을 예측하고 있다. 비지시적 가설은 근거되는 이론이 뚜렷하지 않고, 일관성이 결여된 선행연구 결과에 사용하는 방법이며 분석 방법은 two-tailed test(양측)를 사용하게 된다.
연구가설과 통계적 가설 연구가설(research hypothesis, H1)은 변수들 사이의 기대되는 관계에 관한 진술이다. 통계적 가설(statistical hypothesis, Ho)은 영가설 또는 귀무가설이라고도 하며, 이는 독립변수 사이에 관계가 없다고 진술하는 것이다. 연구 설계 단계에서 연구자는 연구 가설에만 관심을 갖게 된다. 연구 논문에서 귀무가설로 진술하지 않지만, 통계 처리할 때에는 그러한 귀무가설이 있는 것으로 가정한 상태에서 귀무가설이 기각되는지 여부를 검증하며 연구 가설이 채택되는지를 판별하게 된다.
일반가설과 지엽적 가설 일반가설은 가설에 내포된 변수들 간의 관계가 모든 장소와 시간에 관계없이 일반적으로 적용되는 경우의 가설이며, 지엽적 가설은 특별한 경우에만 적용될 수 있는 가설이다. 연구자들은 자신의 가설이 보다 적용 범위가 넓어져서 궁극적으로는 일반 가설로 인정받고자 노력한다. 일반 가설에 가까워질수록 가설의 가치나 설명력과 예측력이 높아지기 때문이다.
가설을 증명하는 방법
관습에 의한 방법(아집적 방법, 고집, method of tenacity) 자기가 믿고 있는 것을 자기 나름대로의 결론을 내리는 방법
권위주의적 방법(method of authority) 권위가 있다고 생각되는 사람들이 말이나 글을 근거로 문제에 대한 결론을 내리는 방법
직관에 의한 방법(method of intuition, 선험적 방법, a priori method) 직관(intuition)에 의하여 결론을 도출하는 방법
과학적 방법(scientific method) 주어진 현상을 기술, 설명하는 과정에서 체계적이고 객관적으로 연구하는 방법
과학적 방법의 종류
관찰적 방법(observational method) 현실을 면밀히 관찰하여 결론을 도출하는 방법
귀납적 방법(inductive method) 구체적・특수한 사실로부터 일반적 원리 또는 결론을 도출하는 방법
연역적 방법(deductive method) 일반화・추상화된 전제(가설)로부터 구체적인 결론 또는 원리를 도출하는 방법
직관적 방법(intuitive method) 연구자가 지식이나 기술을 초월하여 자신의 경험이나 직감으로 결론을 도출하는 방법
가설 연역 방법 19세기 윌리엄 휴얼은 17세기 프랜시스 베이컨에 의해 제기된 귀납을 보완하기 위해 가설 연역 방법을 도입하였다.
가설은 현실적 조건에서는 증명하거나 검증하기 어려운 사물, 현상의 원인 또는 합법칙성에 관하여 예측하는 이론으로, 가설 연역 방법은 크게 이러한 가설을 설정하는 단계와 이를 시험함으로써 가설을 정당화하는 단계로 나뉜다. 가설을 설정하는 단계와 실험 결과로부터 가설을 정당화하는 과정에는 귀납적인 추론이, 가설로부터 검증을 위해 실험을 설계하고 결과를 예측하는 단계에는 연역적인 사고가 요구된다
가설 연역 방법은 측정 가능한 실험 결과를 통해 반증될 수 있는 가설을 통하여, 이론이나 자연법칙을 이끌어내는 과학적 연구 방법 중 하나이다. 가설 연역 방법은 현상 탐구 - 가설 설정 - 결과 예측 - 시험 - 검증 - 법칙 도출의 과정을 가진다.
귀납법과 연역법
귀납법
개별적인 여러 사실로부터, 일반적인 결론을 얻어내는 것.
연역법의 대전제로써 사용되는 경우가 많다.
관찰을 통한 귀납법으로 가설을 설정한다. 예를 들어, 사과가 땅에 떨어지는 것을 보고 만물은 서로 당긴다 라는 가설을 생각한다.
실험 결과로부터 가설을 정당화하는 과정에서 귀납적인 추론이 사용된다.
# 귀납법의 예
맹자는 죽었다
석가도 죽었다.
예수도 죽었다.
공자도 죽었다.
그러므로 모든 사람은 죽는다
연역법
일반적인 원리나 사실을 전제로 개별적이거나 특수한 사실을 결론으로 이끌어내는 것.
가설로부터 검증을 위해 실험을 설계하고 결과를 예측하는 단계에는 연역적인 사고가 요구된다
대/소전제가 참인 명제가 아니면 거짓결론이 도출된다.
# 연역법의 예
1. 대전제가 참인 명제일 때
명제1(대전제) : 모든 사람은 죽는다(A는 B이다) -> 대전제 반드시 필요, 참
명제2(소전제) : 소크라테스는 사람이다(C는 A이다)
결론 : 소크라테스는 죽는다(C는 B이다)
2. 대전제가 참인지 것짓인지 명확하지 않은 명제일 때
명제1(대전제) : 다수의 의견은 타당하다(A는 B이다) -> 대전제 반드시 필요, 거짓
명제2(소전제) : 내 옷이 이상하다는 것은 다수의 의견이다(C는 A이다)
결론 : 내 옷이 이상하다는 것은 타당하다(C는 B이다)
연역법의 명제와 결론의 관계
결론의 주어와 술어는 각각 소전제의 주어와 대전제의 술어가 된다.
일반적으로 말하는 결론에 대한 올바른 근거는 소전제를 말한다.
명제1(대전제) : 모든 사람은 죽는다(A는 B이다) -> 대전제 반드시 필요, 참
명제2(소전제) : 소크라테스는 사람이다(C는 A이다)
결론 : 소크라테스는 죽는다(C는 B이다)
귀납법과 연역법의 타당성 검증
연역법의 대/소전제가 참인 명제인지 평가한다.
명제1(대전제) : 다수의 의견은 타당하다(A는 B이다) -> 거짓인 명제
명제2(소전제) : 내 옷이 이상하다는 것은 다수의 의견이다(C는 A이다) -. 참인 명제
결론 : 내 옷이 이상하다는 것은 타당하다(C는 B이다) -> 거짓인 명제
-> 명제가 거짓이므로 결론도 거짓이다.
명제1(대전제) : 왼쪽 네번째 손가락에 반지를 낀 사람은 결혼한 사람이다.(A는 B이다) -> (사회적 통념상) 참인 명제
명제2(소전제) : 저 여자는 왼쪽 네번째 손가락에 반지를 꼈다.(C는 A이다) -. 참인 명제
결론 : 저 여자는 결혼한 사람이다.(C는 B이다) -> 참인 명제
귀납법의 반례를 찾아낸다.
A : 모든 까마귀는 까만색이야! 왜냐하면 내가 지금 까지 봤던 1000마리의 까마귀는 모두 까맿기 때문이야.(귀납법을 통한 근거제시)
B : 아닌데, 어제 TV동물농장에서 봤던 까마귀는 분홍색이던데?
가설사고의 프로세스
가설 사고로 문제를 해결할 때는 다음과 같은 과정을 거친다.
상황의 관찰/분석 상황을 잘 관찰하고 문제의 배경에 있는 것이 무엇인지를 짐작. 필요하다면 데이터로 증명.
가설 설정 최대한 구체적인 가설을 설정합니다. 이렇게 하면 다음의 과정에서 많은 정보를 얻을 수 있다.
벌써 컨설팅 업계에서 종사한지도 6년 차가 다되어 갑니다. 저는 Accneture, EY Parthenon, Kearney 등 회사를 거쳤는데요. 6년 차가 되어서야 컨설턴트가 이런 측면에서는 돈을 주고 쓸만큼 가치가 있을 수 있겠구나라는 생각이 들어서, 컨설턴트에 가치에 대해 언급해보고자 합니다. 저 뿐만 아니라 많은 컨설턴트들이 이런 생각을 할 겁니다.
전문직도 아니고 기술직처럼 기술에 특화된 직업도 아니고, 도대체 뭐하는 직업이지. 차라리 이 시간에 전문지식이나 기술을 쌓는게 나을거같은데... 이직하고 싶다
저도 6년간 위와 같은 생각을 하면서 컨설턴트로써 살아왔는데, 최근 그것에 대한 답을 드라마보다가 찾았습니다. 손예진과 현진 주연의 사랑의 불시착은 많은 분들이 아실겁니다.(손예진을 먼저 언급한 이유는 제가 손예진을 좋아하기 때문입니다) 꽤나 뒤쪽 에피소드로 기억하는데, 주인공인 윤세리가 첫째 오빠에게 "장학재단 운영해보지 않을래?"라는 제안을 하게 되고, 첫째 오빠는 그 제안을 받아들이게 되는 신이 있습니다. 만약, 비 컨설턴트인 사람에게 돈은 내가 얼마든지 줄테니까 장학재단 하나 만들어봐 혹은 돈은 내가 얼마든지 줄테니까 회사하나 차려봐라는 제안을 한다면, 그러한 프로젝트를 성공적으로 수행해낼 수 있을까요? 아마 힘들 겁니다. 왜냐하면, 돈이 얼마든지 펀딩이 된다고 하더라도, 어디서 시작해서, 일을 어떻게 진행시킬지, 누구한테 연락해서 도움을 청해야할지 등등 무수히 많은 문제해결과 스케쥴 관리에 익숙해져 있지 않기 때문일겁니다.
컨설턴트의 가치는 어떤 일이든(개인의 일이든, 기업의 일이든, 국가의 일이든, 특수 조직의 일이든) 그것을 처음부터 끝까지 설계하고 핸들링해서 원하는 요건을 만족시킬 수 있는 능력에 있습니다.
말은 간단합니다. 하지만, 어떤 일이든 능숙하게 핸들링해서 성공까지 가져가려면 다양한 사고과정에 익숙해져 있어야하고, 스케쥴 관리능력, 커뮤니케이션 능력, 리스크에 대한 민감한 감도 등의 능력이 필요합니다. 이때 컨설턴트로써 필요한 사고과정이 바로 아래와 같은 것들입니다.
사고법이란
아래 제시된 컨설턴트에게 요구되는 사고능력은 문제해결의 과정에서 필요한 사고법들입니다. 문제해결은 크게 요건정의-설계-실행-검증의 단계로 이루어지며, 각 단계에서 다른 사고법이 요구됩니다. 문제해결에 대한 내용은 다음의 링크에서 확인하길 바랍니다.
각 사고법은 what - why - how의 관점에서 검증되어야할 필요가 있습니다. 1. 먼저 이 사고법이 무엇인지? 2. 왜 이러한 사고법이 유용한지? 3. 이 사고 법은 어떻게 활용하는지? 에 대해 자문하면 스스로의 이해를 도울 수 있습니다.
핵심 기초 사고
핵심기초사고는 특정한 케이스에서 활용되는 사고가 아닌, 모든 사고의 베이스가 되는 사고법입니다. 따라서, 가장 중요합니다.
논리적 사고
논리적 사고(Logical Thinking)이란 결론과 근거의 관계를 명확히 하는 것(인과관계)으로, 객관적이고 합리적으로 생각하기 위한 사고법입니다. 쉽게「○○이니까 XX다」라는 여러사고의 가장 기초가 되는 사고법입니다.
비판적 사고
논리의 바름과 그릇을 의심해 보는 것으로 사고의 정확도를 높이는 사고법입니다.
비판적 사고는 결론과 근거의 타당성에 대해 고려하는 것입니다. 결론과 근거에 대한 전제를 타당하지 않게 설정하거나 해석이 다르면 그 주장은 쓸모 없어 지겠죠. 또한, 문제설정 자체가 틀린 경우 어떠한 논리적 사고를 설정해도 의미가 없습니다.
비판적사고는 이러한 논리적사고와 가설적 사고를 보완하는 기능을 합니다. 전제는 올바른지, 주장과 전제의 연결은 올바른지, 결론과 근거의 연결은 올바른지, 객관적이고 비판적인 시선으로 검증합니다. 여기서 비판이란 주장에 단순히 태글을 거는 행위가 아니고 주장을 검증하는 건전한 활동입니다.
가설이란 아직 증명되지 않은 논재로 아무리 천재여도 모든 경우의 수를 고려할 수 없는 한, 가설의 예외와 마주하게 됩니다. 예외가 존재한다는 것은 그 가설이 100% 옳지 않음을 의미하며 가설의 개선 Room을 의미하기도 합니다. 가설을 세우고 증명한 후, 비판적 사고를 통해 가설이 옳지 않은 경우의 수를 제안하면, 가설은 그러한 반례를 커버하기 위한 더욱 좋은 가설로 발전하게 됩니다.
연역적 사고
none
귀납적 사고
none
어브덕션 사고
none
MESE 사고
none
비즈니스 사고・분석 사고
인과루프 사고
인과루프 사고는 논리적 사고의 확장된 형태입니다. 논리적 사고는 원인-결과의 관계를 명확히 하는 것을 의미합니다. 인과관계 사고는 논리적 사고를 기반으로 나아가서 인관관계 망 을 전체적으로 파악하는 사고입니다.
인과관계를 생각할 때는, 보통 단편적인 인과관계만을 고려하기 쉽습니다. 이것이 속히 말하는머리 좋다는 사람과 범인의 차이이죠. 전체적인 인과관계는 복수개의 단편적 인과관계의 연결로 이루어져 있습니다. 어떠한 인과간계든지 간에전체적인 인과관계의 망을 머리 속에 그려놓고단편적인 인과관계는 전체적인 인과관계 망 속에서 겨우 한 부분에 속하지 않음을 인지할 필요가 있습니다.
확률적 사고
인과루프 사고에서 보았던 nested 된 원인과 결과는 100% 확실치 않으며, 일정한 확률을 갖습니다. 확률적 사고의 가장 큰 장점은 확실치 않은 것에 확신하지 않고 일말의 가능성도 존중할 수 있다는 것입니다.
확률적 사고의 예를 들어보기 위해 먼저 가설적 사고를 통해 가설적 결론을 설정해봅시다. 20~30대의 빚투현상은주식시장의 하락을 가져온다라는 가설을 세웠습니다. 이제 남은 것은20~30대의 빚투현상이라는 원인과 주식시장의 하락이라는 결과 사이의 세부적인 인과관계 가설을 설정하고 그 확률을 생각해보면 됩니다. 결론이 정해진 것 하나만으로 사고 어프로치가 명확해집니다. 가설을 설정하면, 최종 결론에 다다르기 위해서 어떠한 논점을 고려해야하는지 큰 그림이 잡힙니다.
20~30대의 빚투현상
(100%)-> 채권의무 발생
(40%)-> 1~2년 내에 의무 상환 금액 증가
(40%)-> 주식 처분을 통한 상환 금액 마련
(100%)-> 주식 시장의 유동성 하락
(100%)-> 주가 하락
위에서는채권의무 발생-> 1~2년 내에 의무 상환 금액 증가-> 주식 처분을 통한 상환 금액 마련-> 주식 시장의 유동성 하락이라는 논점을 마련하여,20~30대의 빚투현상은 주식시장의 하락을 가져온다라는 가설의 타당성을 고려해보았습니다. 하지만1~2년 내에 의무 상환 금액 증가와주식 처분을 통한 상환 금액 마련이라는 가설은신용대출의 상환기간은 3~5년정도가 아닐까?,주식처분을 통한 상환 금액을 마련하는게 아니라, 주식에 있는 돈은 가만히 두고 그동안 벌었던 월급이나 또 다른 대출을 통해서 상환하지는 않을까?라는 반론의 제기를 통해 확률을 매겨볼 수 있고 그에 따라 가설을 더 합리적인 방향으로 수정할 수 있습니다. 가설의 수정을 계속적으로 반복하면, 인과관계의 확률이 높은 최종 가설을 마련할 수 있습니다.
프로세스 사고
프로세스 사고는 0부터 1에 이르기 까지의 모든 단계를 하나하나 따져 보는 사고입니다. 시간적 순서가 존재하는 태스크에 있어서 프로세스 사고는 매우 매우 유용합니다. 시계열은 인과관계의 근거가 되기 때문에, 프로세스 사고의 구체화는 인과관계의 구체화와도 연결될 수 있습니다. 실전에서 프로세스 사고는 인과관계를 판별할 때, 일의 순서를 잡아나 갈 때, 밸류체인과 같이 전체적인 흐름을 파악할 때 등 그 사용법이 폭넓고 유용합니다.
프로세스를 더 이상 세분화할 수 없을 만큼 세분화, 구체화되어서 지금 당장 실행한다고 했을때 누설없이 내가 생각한대로 움직일 수 있을 때만 의미가 있습니다. 내가 위의 프로세스대로 진행하면 의문점 없이 프로세스를 진행할 수 있을지를 머리 속으로 시뮬레이션 해보면, 충분히 세분화, 구체화되었는지 검증할 수 있습니다.
예를 들어, 재료 다듬기 - 삶기 라는 프로세스는 좋지 않습니다. 재료를 다듬는 시뮬레이션을 해봅시자. 먼저 재료라는건 뭔가? 무엇을 다듬을 것인가? 정해지지 않았습니다. 재료가 정해졌다면, 재료를 몇 개나 다듬을 것인가? 어떻게 다듬을 것인가? 껍질만 벗긴째 통째로 사용할 것인가, 썰 것인가? 또, 일반칼을 사용한 것인가 채칼을 이용할 것인가? 삶을 때는 소금을 넣어서 삶을 것인가 맹물에 삶을 것인가? 또 몇 분이나 삶을 것인가? 삶고난 후에는 찬물에 넣을 것인가 그대로 식힐 것인가? 위의 전 프로세스를 언제까지 끝내면 좋을 것인가? 이러한 의문점이 모두 해결된 후에야 프로세스적 사고를 통한 프로세스가 완성됐다고 볼 수 있습니다. 옆집에서 당근 2개 빌리기 - 집앞 천리마 마트에서 오이 1개 사기 - 서랍에서 야채칼 꺼내기 - 당근과 오이를 0.5센치정도로 어슷썰기 - 다썬 야채는 빈 접시에 담아두기 - 냄비꺼내기 - 물을 500ml 넣기 - 물을 끓이기 - 끓는 냄비물에 소금 넣기 - 썰어놓은 야채 중 오이는 그대로 두고 당근만 5분 대치기라는 프로세스로 구체화할 수 있습니다.
동시적 프로세스는 아래와 같은 그림처럼 머릿속에 그려볼 수 있습니다.
소화기 발주받음 - 재고부에 전화 - 창고에서 꺼내기 - 제품 테스트 - 운송부에 소화기 전달 - 발송 --- 일반소비자 A에게 도착
└---- 대학교 B에 도착
└---- 소방서 C에 도착
한 스택홀더가 복수번 등장하는 경우, Sequence 를 이용하면 편리합니다.
구조적 사고
구조화란 한번에 정복하기 힘든 문제가 있을때, 이를 세부적인 부분까지 나누어서 분할한 뒤 각각의 문제를 해결하여 전체적인 문제해결을 도모하는 것입니다. (각개격파하기!)
역시나 정의로만 보면 무슨 소리인지 모르겠습니다. 예를 통해 보도록 하겠습니다. 다음과 같은 발생형 문제를 생각해보겠습니다. 스타벅스의 1일매출을 15퍼센트 늘이기 위해서는? 이라는 과제가 있습니다. 자, 어떤 해결방법들을 생각해낼 수 있을까요? 읽기를 멈추고 생각해보세요.
막막합니다 역시..곧바로 머리속에 드는 생각은 '호객을 열심히 한다' '신메뉴를 개발한다' 커피 값을 올린다' 정도가 되겠네요. WHAT트리나 WHY트리와 같은 분석도구 없이는 직관적인 해결방법에 의존하게 됩니다. 하지만 직관적인 해결방법은 생각의 누출이 많고 논리성을 보장하기 어렵습니다.
그럼 어떻게 접근해야할까요?
먼저 스타벅스의 1일 매출을 구조화 해보겠습니다.
스타벅스 1일 매출 = 구매자수 * 1인당 평균 구매액
= [판매형태에 따라서 구조화] (테이크아웃하는 구매자수 * 1인당 평균 구매액) + (점포내 구매자수 * 1인당 평균 구매액)
= [점포내 구매자수를 더 세분하게 구조화] (테이크아웃하는 구매자수 * 1인당 평균 구매액) + (업소내의 좌석개수 * 시간당 가동율 * 시간당 회전율) * 1인당 평균 구매액
- 테이크 아웃하는 1인당 평균 구매액을 늘이기 위해 : 테이크아웃하는 고객에 대해서 할인 행사를 시행해 더 많이 사가게 하도록 유도한다.
- 업소내의 좌석개수를 늘이기 위해 : 카페내의 빈공간을 효율적으로 사용하고 stand-bar나 카운터석을 늘인다(고객의 만족도가 하락하기 때문에 이후의 검증 과정에서 폐기될 해결방책이긴 하겠지만..)
- 시간당 회전율을 높이기 위해 : 고풍스럽지만 딱딱한 의자를 준비하여 오래 앉아 있지 못하게 한다.
- 1인당 평균 구매액을 늘이기 위해 : 커피 뿐만 아니라 베이커리나 셀러드나 샌드위치와 같은 간단한 식사류를 준비하여 함께 구매하도록 유도한다.
자, 그럼 이번에는 아까보다 생각하기가 훨신 수월해졌다는걸 느낄 수 있겠죠? 문제를 막연히 하나의 큰 덩어리로 보는 것이 아니라 조그만한 덩어리로 쪼개고 보면, 비교적 덜 부담스러운 조그만한 덩어리들에 대해서 각각의 해결책을 마련할 수 있는 생각을 할 수 있게 되기 때문입니다.
또한 각 구조화에서는 MESE가 적용되어 있기 때문에, 생각의 누출이 없고 논리성을 보장할 수 있습니다.
구조화의 종류
여러 포스트에서 손이 닳도록 설명했기 때문에, 이번에는 인덱스만 소개합니다. 세부내용은 다음 링크에서 확인
사칙연산을 통한 구조화(=함수적 사고)
축을 통한 구조화
MESE프레임워크를 통한 구조화
프로세스 분석을 통한 구조화
함수적 사고(사칙연산을 통한 구조화)
함수적 사고는 구조화 사고 중 사칙연산을 통한 구조화를 따로 빼낸 것입니다. 구조화의 하나로써가 아닌, 새로운 이름 까지 붙인 이유는 그만큼 중요도가 높은 사고법이기 때문입니다. 함수적 사고는 함수가 의미하는 바와 같이, 어떤 종속변수에 영향을 미치는 독립변수들을 구조화하고, 독립변수(파라미터)의 변화에 따른 종속변수의 변화를 고려해보는 것입니다. 함수적 사고의 가장 큰 장점은 정성적인 변수를 정량적으로 판단할 수 있는 가설을 세울 수 있는 점 입니다.
예를 들어, 어떤 시장이 명품소비가 가장 활발할지를 생각해볼까요? 명품소비를 독립 변수로 두고, 이에 영향을 미치는 종속변수를 생각해봅시다.
# 명품소비의 함수화
가설1: 전 사회적으로 과시욕이 큰 사람이 많을 수록 명품소비는 증가할 것이다.
가설2: 보상심리에 의해 경제력보다는 성장속도가 빠를 수록 명품소비는 증가할 것이다.
명품소비 = 과시욕 계수 * 경제 성장속도
# 과시욕 계수의 함수화
가설1: 과시할 대상이 많으면 과시욕은 증가할 것이다.
가설2: 물질적 과시에 대한 사회적 인정이 높을수록 과시욕은 증가할 것이다.
과시욕 = 과시대상 인구 * 사회적으로 물질적 과시에 대한 관대한 문화
∴명품소비 = (과시대상 인구 * 사회적으로 물질적 과시에 대한 관대한 문화) * 경제 성장속도
이때 미시적인 관점으로 A사 자동차구매율A사 자동차재구매율에 영향을 미치는 변수를 생각하면, 'A사 제품은 차량 종류' 'B사 자동차' 'A사의 마케팅'와 같은 것을 직관적으로 생각해 낼 수 있겠네요. 하지만 이게 전부일까요?
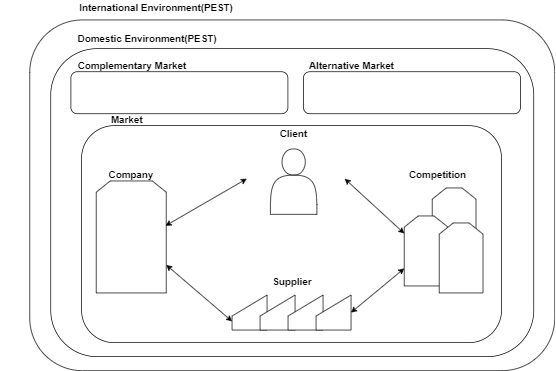
다음의 기업문제 해결에 있어서 가장 기본이 되는 5C-exension을 봅시다.(기존 5C는 company, clinet, competition, channel, cost이지만 그외의 요소들을 개인적으로 확장했습니다.)
직관적으로 언급했던, 'A사 제품은 차량 종류' 'B사 자동차' 'A사의 마케팅'과 같은 요소는 경쟁요소에 의한 변수와, 고객요소에 의한 변수밖에 다루지 않고 있습니다. 매우 미시적인 관점의 분석입니다. 하지만, 5C-exension과 같은, 거시적인 판을 사전에 이해하고 있었다면, A사 자동차구매율A사 자동차재구매율에 영향을 미치는 변수를 아래와 같이 더욱 폭넓게 생각하고, 각 변수에 따른 가설들을 세울 수 있었을 것입니다.
1. International external env FACTORs
2. Domestic external env FACTORs
3. Alternative FACTORs
4. Complementary FACTORs
5. Competitor FACTORs
- 경쟁 기업의 차별화
6. Client FACTORs
- 가격전략
- 유통채널
- UX
- 성장전략(CLMMT)
- 차별화
- 회사 이미지, 고객 충성도
7. Suplier FACTORs
- 교섭력
8. Company FACTORs
- 밸류체인
- 7S
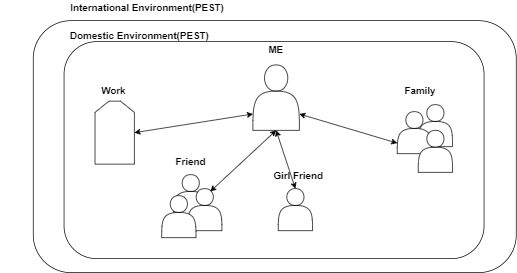
이는 기업의 문제해결 뿐만 아니라 모든 문제를 해결할 때도 마찬가지 입니다. 예를 들어, 해외로 취직을 할지 말지에 관한 개인의 문제를 해결할 때도 전체적인 판을 거시적으로 파악하고 문제해결에 대한 설계 페이즈에 들어가는 것이 합당합니다.
해외로 취직을 할지 말지를 결정하는데, 단순히 일적인 요소여자친구만을 고려하면 생각치 못한 리스크와 마주할 가능성이 있습니다. 국내 외부 환경과 국외 외부 환경이 자신의 결정에 어떠한 영향을 미치는 변수일지도 함께 고려해야 리스크 미리 인지하고 대응책을 준비할 수 있습니다.
시간축을 거시적으로 보기
고객사와 변호사 그리고 전략컨설턴트 3그룹이 함께 들어간 프로젝트가 있습니다. 조인트 벤처를 해산하는 건인데, 가장 먼저 논의하는 것은 termination에 대한 scheme을 정하는 것입니다. JVA나 각 국의 상법, 형사법을 들춰보며, 어떤 스킴으로 해산은 하는 것이 서로에게 이득이 될지 여러모로 논의합니다. 계약의 성립이나 해지의 단계는 변호사들이 가장 활약하는 단계이기도 합니다. 전략 컨설턴트들은 각 스킴의 재무적 시뮬레이션 시행하고 법적 근거를 뒷바침할 시장, 기업 관련 조사들을 시행하죠.
이와 동시에, 숙련된 컨설턴트는 거시적으로 시간축을 관찰 합니다. 현재는 모든 플레이어가 스킴에 대한 논의에 바짝 집중하고 있어서 다른 쪽으로는 시선조차 돌리지 않을 때도, 숙련된 컨설턴트는 이후에 다가올 예상되는 과제들에 대해 미리 숙지하고 전략을 시행하죠. 미리 전략을 시행하는 것은 이후 협상 테이블에서 유리한 카드를 더 많이 내놓을 수 있는 가능성을 매우 높여줍니다. 바로 이런 것이 컨설턴트가 비싼 돈 받으면서 창출해야하는 가치입니다.
M&A와 같이 시간축에 따라 어느정도 해야할 일이 정해진 업무와 같은 경우는 (상황에 따라 매우 세부적인 액션이 조금씩 다르기는 하겠지만) 거시적인 시간축을 조망하기 그나마 용이합니다.
하지만 상대의 액션에 따라 앞으로 나의 액션이 시시각각 변하는 상황에서는 가설적 사고가 전략적 사고에서도 매우 중요하게 작용합니다.
논점을 거시적으로 보기
당장 눈앞에 있는 구조화된 논점 뿐만 아니라 상위 논점까지 시야를 확장해, Top-Down으로 보는 것을 의미합니다.
최근 프로젝트에서 다음과 같은 경험을 한 적이 있습니다. 프로젝트는 향후 탄소중립 트렌드로 인한 대외환경 변화 때문에, 안정적인 신재생에너지 공급을 위한 벤치마킹 전략 안건이었습니다. 좁은 시각에서 주어진 프로젝트만을 바라본다면, 가장 상위 레벨의 구조에 "신재생에너지 공급"이 위치하겠지만, 그 상위 레벨에 다른 논점이 있다는 걸 알아채고 상위 레벨로 시야를 확장하고자 한다면, 더 넓은 배경을 이해할 수 있습니다.
기업의 최종 목적은 이윤창출이고, 이윤창출이야 말로 기업의 모든 이슈의 가장 상단 레벨에 존재하고 있는 논점입니다. "안정적인 신재생에너지 공급"을 고민하는 위와 같은 프로젝트에서도 이윤창출을 가장 상단에 넣고 논점을 구조화해나갈 수 있습니다. 이윤창출 > 안정적인 원재료 공급 > 에너지 공급 > 에너지의 구성 중 재생에너지 > 근데 재생에너지 괜찮나? 안정적 공급 가능한가? > 안정적인 재생에너지 공급 으로 문제 인식이 흘러갔을 가능성이 높습니다.
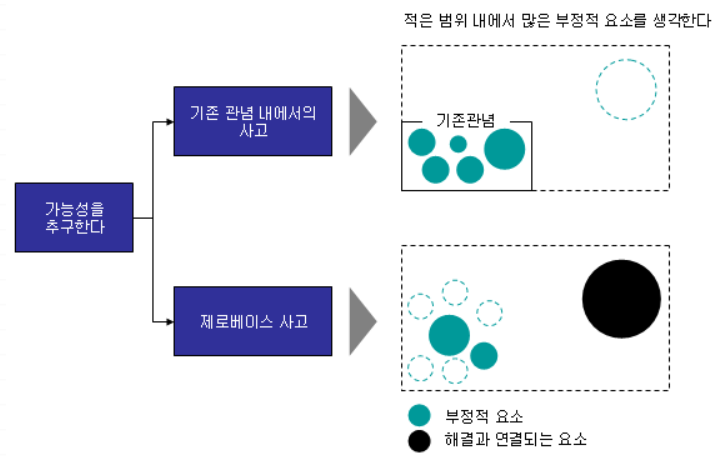
제로베이스 사고: 지금 생각이 너무 복잡하게 얽혀있어, 우리 처음부터 요점만 다시 생각해보자!
제로베이스 사고에 방해가 되는 것은 ‘기존 관념’이다. 그 중에서도 가장 방해가 되는 것은 자기 자신이다. 자기 스스로 좁은 틀을 설정해 부정으로 치우쳐서는 안된다.
논리학의 가상세계에서는 전체의 집합이 명확히 정의되어 있다면, 그 중의 구성요소로서 ‘Not Out Factor(이것이 안되면, 무엇을 해도 절대로 안 되는 요소)’를 무엇인가 하나 찾아내서 사물을 부정하는 것이 비교적 용이하다.
일상생활이나 비즈니스에서 자의적으로 사고 틀을 설정하거나 대상을 한정했기 때문에, 상대에게 “어쨌든 안 되겠군요.”라고 말한 적이 있을 것이다. 즉, Not Out Factor와 비슷한 것을 지적한 셈이다. 그러면서도 “뭔가 이상하다”, “뭔가 빠져나갈 수 있을 것 같다”라고 느끼면서 “정말 안되는 것일까?”라고 의심을 품은 채 포기한 경험이 있을 것이다. 즉, 자신의 좁은 시야 내에서 때때로 부정적 요소가 크게 보이기 때문에 결국 전체도 부정적으로 바라본 경험은 누구에게나 흔히 있는 일이다.
특히 비즈니스 현장에서는 여러 가지가 복잡하게 얽혀 있기 때문에 처음부터 전체의 모습이 간단하게 보이지 않거나 정의가 불가능한 경우도 많다. 이때가 바로 제로베이스 사고로 생각할 것인가, 혹은 기존 관념에 집착할 것인가의 분기점이 된다.
해결이 어렵다고 처음부터 기존 관념에서 벗어나지 못하고 작은 틀 속에서 한정적으로 사고하기 때문에, 틀 밖에 있는 해결책을 보지 못하거나 최악의 경우에는 틀 속의 부정적 요소를 매우 사소한 것까지 열거하면서 시작하게 된다.
한편, “어쩌면 틀 밖에 해결 가능성이 있지 않을까?”라고 생각하는 제로베이스 사고에서는 자신의 좁은 테두리를 넘어서 생각하고자 하기 때문에 해결책을 찾아낼 가능성이 높다. 종래의 틀 이외에 가능성에 도전하는, 전향적이라는 의미에서 제로베이스 사고는 적극적 정신과 상통한다.
혹시 지금 비즈니스에서 무엇인가 해결해야 할 과제를 가지고 있다면 ‘이 과제를 해결하기 위한 구체적인 대안이 있다’는 전제 아래 제로베이스에서부터 생각해 보면 어떨까? 물론 처음에는 에너지를 많이 투입해야 하기 때문에 힘들 것이다. 그러나 제로베이스 사고를 실천하지 않으면 비즈니스에서 성공할 수 없다.
마치 경제학에서 핵심을 바라보기 위해 만물을 추상화하는 것과 같다. 명확한 통찰을 얻기 위해서, 고려해야할 변수 이외의 것은 고려하지 않는 것이다. 노동시장에서 노동 효율성과 비정규정책 사이의 관계를 증명하기 위해, 그 외의 요소, 노동조합 사회문화적 특성 등은 고려하지 않는다. 제로 베이스에서 고려해야할 변수만 고려한다.
디자인 사고
none
옵션 사고
none
DAIT사고
DEFINEARCHIMPLEMENTTEST 로, 요건정의 - 설계 - 실행 - 검증의 사고법
학습의 기본원리는 자신이 무엇을 이해하지 못했는지 구체적으로 인지하고 탐구하여 알게 되게 하는 것: 무지의 지
아래 공부법의 기본 원리는 가볍운 시작으로 전 범위의 루틴을 즐겁게 돌게하여 새로운 지식의 학습에 대한 벽을 허무는 것
아래의 독해법은 전공서적, 시험용 서적 등 시험을 목적으로한 학습이 필요로하는 독해법이다. 보통의 소설, 교양서적은 조건독해법을 따른다.
독해의 기본 디폴트 마인드는 한 번에 이해하겠다는 오만한 자세를 버리는 것이다. 최소 복수번 읽는 것이 당연하다는 겸손한 자세로 독해에 임한다.
연반추 독해법(전공서적, 시험용 서적 등 시험을 목적으로한 학습)
연반추 Soft Review 원리 란 부드럽게 반복해서 읽어나가는 것을 말한다. 학습자료를 스트레스 없이 편하게 복습하는 것으로 반복학습의 효율을 높이는 학습 원리이다.
1단계 : 3회 독파
1회 독파에서는 모르는 단어나, 모르는 내용을 표시하며 편하게 읽어나간다. 1회 독파에서는 전체 내용에서 무엇이 중요한 것인지 제대로 판단할 수 없기 때문에 중요단어 를 판단할 생각을 하지 않는다.
2-3회 독파에서는 중요단어 를 밑줄 긋기하며 편하게 책을 읽는다.
책 내용이 이해되지 않아도 그냥 가벼운 마음으로 물 흐르듯 읽는다. (읽다가 이해 되지 않는다고 뒤돌아 가지 않는다)
위의 방법으로 세 번 읽는다. 가장 중요한 주의 사항 : 이해하려 하지 마라
2단계 : 2회 독파
배경지식이 부족해 이해가 불가능한 개념들을 가볍게 찾아본다. (개념들을 완전히 이해하려고 하지마라. 개념들의 이해를 천천히 완전하게 해나간다)
핵심어중의 핵심어를 표시해나가면 읽는다.
이단계에서 왠만한 교양서적은 정리가 된다.
3단계
연필로 밑줄 그은 글과 표시한 핵심어를 중심으로 5차례 빠르게 속독한다.
이렇게 책 한권을 10회 독파하는 속도는 기존 공부법 3회 독파 속도보다 빠르다
재래식 공부법으로 3차례 독파조차 의지력 강한 소수만이 수행할수 있지만 이 학습법으론 쉽게 연반추할 수 있다.
조건 독해법(소설, 교양서적 등의 일상에서 글을 읽을 때 필요로 하는 독해법)
소설, 교양서적은 90%가 읽기 쉬운 부분이라면 10%정도는 한 번에 이해가 되지 않는 정도의 구성으로 이루어져 있다.
90%의 이해하기 쉬운 부분은 문장 전체를 덩어리로 읽어가며 훑듯이 빨리 읽는다. 예를 들어, '나는 사과를 좋아해' 라는 정도의 이해하기 쉬운 문장이 이어질 때, 그 부분을 한 글자 한 글자 읽어가며 음미할 필요는 없다는 것이다. 오히려 독해력이 감소한다.실제로 지각심리학에서 시각패턴 지각 중 독서능력을 연구하는 과학자들에 따르면, 유능한 독서가와 무능한 독서가는 눈동자 움직임에서도 실제로 차이가 나타난다고 한다. 극단적인 예로, 서구의 실독증(alexia) 환자들은 단어의 개개 알파벳 하나하나를 응시하면서 책을 읽는다. 반면 책을 빠르고 정확하게 읽는 사람들의 눈동자는 더 효율적으로 움직여서, 보다 넓게 자주 도약하면서 한번에 넓게 읽는 경향이 있다.
훑듯이 읽다보면 한 번에 머리에 들어오지 않는 문장이 등장한다. 10% 정도의 한 번에 흡수할 수 없는 문장이다. 이런 부분은 속도를 줄여 천천히 이해하며 읽는다. 프로그래밍의 if 조건절 처럼, 한 번에 머리에 들어오지 않는 문장이 발견될 때만 속도를 줄여 읽는 방식 때문에 조건 독해법이라 불린다.
속독가들이 한번 본 책을 나중에 다시 보면 중간중간 빼먹었던, 혹은 기억이 나지 않는 소소한 부분이 있음을 알게 된다. 전체적인 의미를 파악하고 넘어가거나 넘겨버리기 때문에 실제로 기억해둘 필요를 못느끼거나 읽지를 않고 넘어가는 부분이 생기는 경우가 있기 때문에 발생하는 문제점. 물론 속독을 하면서 오자까지 잡아내는 괴물도 있지만 예외로 칠 정도로 적은 경우다.
또한 소설이 아닌 전문 서적을 읽을 때는 크게 도움이 되지 않는다. 전문서적은 책을 단순히 읽는 것뿐 아니라 그 원리를 이해하고 나아가 적용, 연계까지 할 수 있어야 그 책을 읽었다고 할 수 있다. 스토리텔링 위주의 가벼운 문학에는 도움이 되겠지만 그 이상의 도서를 읽을 때는 도움이 안 된다는 것. 특히 대학교 전공서적, 학술논문, 헌법판례, 반박과 재반박이 왔다갔다하는 지극히 논쟁적인 주제를 다룬 글, 심오한 철학적 개념을 다룬 글, 충분한 배경지식이 요구되는 글 등, 고도의 지적 활동이 요구되는 독서에는 이미 읽는 속도라는 것이 사실상 별 의미가 없어진다. 심지어 인문학의 경우 세계 최고의 석학들도 기껏해야 한 구절 내지는 한 페이지 붙들고 몇 시간씩 끙끙대는 경우가 흔하다. 속독학원들에서 흔히 광고하는 내용이 대부분 꼬마아이가 큼지막한 글씨의 동화책을 파라라라락 넘기는 모습인 것도, 전문 서적에 적용하기는 무리가 있는 방법이기 때문이다. 물론 읽는 속도가 빠르다면 고도의 지적활동이 요구되는 독서에서도 어느 정도 도움이 되기는 할 것이다. 앞에서 언급했듯이 속독이 가능한 사람들은 책의 내용과 문장을 이해하는 속도가 빠른 편이기 때문.
그 외에도 내용에 대해 고찰하거나 사색하는 과정이 필요한 책의 경우에도 속독이 딱히 유용하다고 보기 힘들다. 이 때문에 책을 세세하게 읽고 머리속으로 장면을 그려보거나 고찰하기를 좋아하는 사람들은 속독하는 이들을 두고 낭만이 없다, 사색은 언제 하냐, 그게 무슨 책 읽는 거냐 등의 이유로 싫어하기도 한다.
수험생에게는 양날의 검이다. 인터넷 광고나 속독사이트 리뷰게시판을 보면 마치 속독(의미단위 읽기)이 마법의 묘약처럼 묘사되곤 한다. 하지만 실제로 체험해보면 효과가 있는 사람은 거의 없으며, 책을 많이 읽은 사람은 필요가 없을 수 도 있다.
속독이 효과적이라는 주장은 심리학자가 편찬한 '유혹하는 심리학(Scott Lilienfeld 외 3인, 타임북스, 2010)'에서 대표적인 대중심리학의 주장으로 뽑힌 바 있다. 또한 속독(skimming)이 특정 기술으로서의 의미가 없다는 연구 결과도 있다. 특정한 사람들이 텍스트를 다른 사람들보다 훨씬 빨리 읽어내는 것은 단순히 그 사람들이 교육 등의 외부 효과에 의해 특정한 텍스트에 다른 사람들보다 훨씬 더 익숙하며, 집중력과 이해 능력, 그리고 동체 시력이 좀 더 좋기 때문에 일어나는 결과이지 특별한 기술을 쓰고 있는 것이 아니라는 결론이 그것이다. 따라서 책 한 번 제대로 읽어보겠다고 무작정 속독학원 같은 곳에 등록하는 것은 될 수 있으면 자제하도록 하자.
# 구조화의 예
스타벅스 매출 = 객수 * 객단가
= (업소내의 자리수 * 시간당 가동율 * 시간당 회전율) * 객단가
시간당 가동율, 회전율, 객단가를 요일, 시간축으로 구조화
| 평일 | 주말
--------------------------------------------------------------------------------
6-9시 | 30석*0.2*1*500엔 | 30석*0.3*2/3*600엔
--------------------------------------------------------------------------------
9시-12시 | 30석*0.3*1*500엔 | 30석*0.5*2/3*600엔
--------------------------------------------------------------------------------
12시-15시 | 30석*0.5*1*500엔 | 30석*0.7*2/3*600엔
--------------------------------------------------------------------------------
15-18시 | 30석*0.5*1*500엔 | 30석*0.9*2/3*600엔
--------------------------------------------------------------------------------
18시-21시 | 30석*0.6*1*500엔 | 30석*0.9*2/3*600엔
--------------------------------------------------------------------------------
21시-24시 | 30석*0.2*1*500엔 | 30석*0.3*2/3*600엔
--------------------------------------------------------------------------------
# 가설사고의 예
주말에 가동율이 높고 회전율이 낮다는 가설의 근거는?
주말에는 시간이 많다 -> 카페를 더 많이 방문한다.
주말에는 시간이 많다 -> 카페에서 더 오래 앉아 있는다.
시간이 많으면 꼭 카페에 가는가? 다른 활동을 더 할 가능성은 없는가? 논리적 비약이 아닌가?
주말에는 시간이 많다 -> 집에 있는 시간이 길어진다 -> 답답하다 -> 외출을 한다
-> 날씨가 더워서 야외 활동보다는 실내활동을 선호한다 + 돈이 쓰고 싶지 않다 -> 카페를 방문한다
페르미추론의 어프로치의 유형
페르미추론의 5스텝
1. 전체확인
과제는 구체적으로 제시되지 않는 경우가 많다. 특히 실제 업무상의 과제는 더욱 그렇다. 때문에 그 과제에서의 키워드를 명확히하고, 목표를 가능한한 수치화하는 전처리 작업이 필요하다.이러한 전처리 작업을 확실히 하지 않으면 이후 문제에 어프로치 함에 있어 문제가 발생한다.
1년간 일본에서 팔리는 볼빅량은?
Q : 볼빅은 어떤 볼빅을 말하는거지? 500미리 말하는거야 1000미리 말하는거야?
Q : 양이라는건 물통의 갯수를 말하는거야 아니면 ml를 말하는거야?
등 각 용어를 명확히 하지 않으면, 문제해결의 방향이 정해지지 않는다.
2. 구조화
①사칙연산을 통한 구조화
사칙연산을 통한 구조화란 목적변수에 영향을 미치는 종속변수들을 사칙계산으로 나누어 구조화 하는 것이다.
A.계산식의 방향설정
・미시일때는 공급측면에서, 거시일때는 수요측면에서
예를들어 맥도날드 한 점포의 일년 수익을 묻는 문제에선 비교적 미시적인 시장이므로 공급측면에서 어프로치하고 1년에 팔리는 도요타 자동차의 대스는 이라는 문제에선 비교적 거시적인 시장이므로 수요측면에서 어프로치한다. 실제 케이스 면접이나 실전에서는 여러가지 어프로치로 추론할 수 있음을 보이는 것이 중요하다.
B. 사칙연산을 통한 구조화 : 비즈니스는 +-÷×를 통해 충분히 분해될 수 있다!
예1. 스타벅스의 하루 매출은?
매출 = 스타벅스 구매자수 * 1인당 평균 구매액
= [수요자 관점에서] (해당 스타벅스 점포의 주변의 유동인구 * 유동인구중 스타벅스 선택율) * 1인당 평균 구매액
= [공급자의 관점에서] (업소내의 자리수 * 시간당 가동율 * 시간당 회전율) * 1인당 평균 구매액
예2. 기업의 성장률은?
성장률 = a*경쟁상황변수 + b*고객매출변수 + c*시장외부변수 + d*대체시장영향력변수
사칙연산을 통한 구조화시 주의점
시장규모 예측의 가장 베이직은 volume X price. volume은 수요장 입장에서 분석하느냐, 공급자 입장에서 분석하느냐에 따라 다른 식으로 표현할 수 있음에 주의하자.
일반적으로 재화나 서비스의 전체시장 규모를 예측하는 문제가 케이스 면접에서 가장 빈번히 발생하는 주제다. 전체 시장 규모의 수식은 마크로 경제이므로 수요자 입장에서 접근하면 용이하다. 판매량 X 판매가격 = (전체국민 X 선택률 X 1인당 평균 구매갯수) X 판매가격 이다. 하지만, volume은 수요자 입장에서 분석하느냐, 공급자 입장에서 분석하느냐에 따라 달라(주로 마크로경제는 수요자 입장에서, 미크로경제는 공급자 입장에서)달라질 수 있음을 인지하고 실제 면접상황에서 당황하지 않길 바란다.
가령 영화관 시장 전체의 시장규모와 어떤 1점포의 영화관의 1년간 수익을 예측하는 페르미 추론은 다음과 같다.
영화관 전체의 시장규모(마크로 경제이므로 수요자 입장에서 분석)
= 판매량(volume) X 판매가격(price)
= (전체국민 X 1년에 1번 이상 영화관을 가는 사람의 비율 X 1인당 1년간 평균 영화시청 횟수) X 1장당 평균 판매가격
-> 이때 1년에 1번 이상 영화관을 가는 사람 비율과 1인당 1년 평균 영화시청 횟수는 국민을 어떠한 segment로 나누냐에 따라 달라짐(나이대와 성별로 나눌것)
A영화관 1년 수익예측(미크로 경제이므로 공급자 입장에서 분석)
= A영화관 한달 수익 X 12
= (A영화관 일주일 수익 X 한달 평균 주(週)의 갯수) X 12
= (일주일판매량(volume) X 판매가격(price)) X 한달 평균 주(週)의 갯수) X 12
= (스크린 갯수 X 스크린당 1주일에 상영하는 평균 영화수 X (스크린당 좌석 갯수 X 좌석의 평균 만석률) ) X 판매가격 X 한달 평균 주(週)의 갯수) X 12
-> 좌석의 평균 만석률은 요일에 따른 segment로 달라짐
축을 통한 구조화란 어프로치 설정에 의해 결정된 각 요소들을의미가 있는 축을 기준으로 나누는 작업이다. 이때,의미가 있는 축을 설정하는 기준이란 인수분해시 나누어진 요소들에게 영향을 줄 수 있는 축이다.
예를 들어, 사칙연산으로 구조화된 다음과 같은 식에서 부산에어의 1년 매출 = (seat수 * 혼잡율 * 일주일 중 운항횟수) * 52주 * 객단가 seat수, 혼잡율, 운항횟수, 객단가의 변수는 모든 운항에 대해 동일하지 않으며, 이는 시간축국내/국제선 축 에 의해 유의미하게 다른 값을 가진다.
# 매출을 구성하는 주요 축의 종류
age sex time area sku channel EL E/N busi natl
축을 통한 구조화시 주의점
구조화가 끝난 뒤 구체적인 수치를 산정할 때, 그 수치가 타당한 가설인지 인식한다 부산에어의 1년 매출 = (seat수 * 혼잡율 * 일주일 중 운항횟수) * 52주 * 객단가 의 식으로 분해후, 혼잡율을 계산한다.
국내 | 250석 * 0.5 * 100회 * 10만원
국제 | 500석 * 0.6 * 30회 * 40만원
위에서는 모든 국내선 비행기의 혼잡율은 평균 50%다 라는 가설을 세웠는데, 가설의 근거는 무엇인지인지 판단할 수 있어야 한다. 복수의 축을 통해 세부적으로 구조화를 거쳐 가설의 가능성을 산정할 수 있도록 한다.(시간적 우선순위, 동시발생 조건, 외생변수의 통제의 관점에서 인과관계의 타당성 검증이 가능하다)
★자신의 감각치를 통해서 가설을 세울시, 자신이 속한 특수한 상황에 유의한다 구조화가 끝난 뒤, 수치를 가정할 때 자신의 감각치를 통해 수치에 대한 가설을 세우는 것은 매우 흔한 일이다.
가령, A씨는 20-40대가 한달에 랍스타를 네번 먹는다고 가정했다. 이는 '나는 일주일에 한번은 먹으니까 20-40대는 한달에 네번 먹겠네' 라는 근거에서 나왔다. 하지만, 개인의 감각치라는 것은 그 개인이 속한 특수한 상황에서만 발생할 수 있는 것이다.
한 달에 랍스타를 네 번 먹는 것은 A씨가 갖고 있는 유복한 경제적 상황, 랍스타에 대한 개인적인 성향이 만들어낸 상황인 것이다. 따라서, 그러한 특수성을 고려해 좀 더 세부적으로 구조화 한 뒤 가설에 대한 근거를 세우는 것이 더 정확한 인과관계를 만들어 낸다. 20-40대를 경제도에 따라 상중하, 또 각각의 상중하를 랍스타를 좋아한다/안좋아한다 로 구조화 한 뒤 개인의 감각치를 적용하면 그나마 얼추 정확한 근거가 될 수 있다.
복수의 축을 통해 구조화를 세밀하게 할 수록 가설의 논리적 비약이 줄어든다.(보스턴 면접에서 느낀 점)
例1:부산에어의 매출은?
항공사의 1년 매출 = 객수 * 객단가
=[공급자 관점에서] (각노선의 자릿수 * 혼잡율 * 일주일 중 운항횟수) * 52주 * 객단가
국내/국제선이라는 구조화의 축은 노선 seat수, 혼잡율, 운항횟수, 요금에 영향을 미치는 축이 이라고
가설을 세웠다. 어느 정도 타당성이 보인다.
국내 | 250석 * 0.5 * 100회 * 10만원
국제 | 500석 * 0.6 * 30회 * 40만원
다음과 같은 반론을 예상할 수 있다.
- 모든 국내선은 혼잡율이 50%인가? 모든 국제선은 혼잡율이 60%인가? 이는 가설의 가능성은 몇% 인가?
혼잡율과 요금은 시간축에 따라 재구조화될 수 있다.
국제 국내
평일 | 6-12시 | 500석 * 0.3 * 2회 * 29만원 250석 * 0.5 * 15회 * 9만원
| 12시-18시 | 500석 * 0.6 * 10회* 32만원 250석 * 0.7 * 20회 * 10만원
| 18시-24시 | 500석 * 0.6 * 3회 * 30만원 250석 * 0.7 * 15회 * 11만원
주말 | 6-12시 | 500석 * 0.9 * 2회 * 36만원 250석 * 0.8 * 15회 * 15만원
| 12시-18시 | 500석 * 0.6 * 10회* 31만원 250석 * 0.6 * 20회 * 13만원
| 18시-24시 | 500석 * 0.3 * 3회 * 29만원 250석 * 0.4 * 15회 * 7만원
위와 같은 세부적인 구조화를 통해, 가설의 정확도를 높일 수 있다.
③MESE프레임워크를 통한 구조화
위에서 언급한대로 비즈니스 사이드는 구조화가 축의 설정에 따라 달라지므로 축설정이 중요하다. 그런데 문제는 대상에 대한 배경지식이 존재하지 않는 이상 어떤 의미있는 축을 선정할지 자체가 굉장히 까다롭다는 것이다. 이를 돕기 위한 것이 프레임워크이다. 일반적으로 사용되는 의미있는 축을 그때그때 대입해 사용할 수 있다.
프레임워크는 이미 MESE화 되어 있으므로 문제의 구조화에 있어 큰 도움이 됩니다. ppt자료를 만들때 레퍼런스가 있고 없고의 차이를 크게 경험해봤을 것이다. 레퍼런스는 요건에 따라 완벽하지는 않지만 사고에 큰 도움이 된다. 축의 프레임워크는 이러한 레퍼런스와 같다. 혹은 개발 경험이 있으신 분들은 외부 라이브러리를 사용하는 것이 얼마나 편리한지 알 것이다. 프레임워크는 외부 라이브러리를 사용하는 것과 같다. 보장된 로직을 사용함으로써 나의 부담을 줄이는 것이다.
매출은 객수*단가 = 인구*선택률*1인당구매개수*단가와 같이 구조화 될 수 있다. 웹어플리케이션은 레이어 라는 축으로 구조화하면 DB, 서버, 클라이언트 로 구조화 될 수 있다. 그렇다면 다음으로 승진이라는 개념은 어떻게 구조화할 수 있을까?
좀 막막하다. 승진이라는 개념은 한 시점에 발생하는 STOCK개념이 아니라 시간적 흐름에 의해 발생하는 FLOW개념이다보니 이를 STOCK 요소로 분해하려는 시도에서 머리가 말을 듣지 않는 것이다.
승진은 FLOW이기 때문에, 그 요소를 분해함에 있어서도 시간적 흐름에 따라 분해하면 된다. 이를 고객 여정 분석(customer journey analysis)라고 한다. 즉, 고객 여정 분석에 따르면 승진이라는 flow는 퍼포먼스 - 인사평가 - 인사권한자 승인 - 인사적용의 흐름으로 구성된다.
다른예로는, 엘리베이터의 사용을 편리하게 하기 위해서는, 웹사이트의 이용을 편리하게 하기 위해서는, 보조금 제도의 리스크시이레를 구조화하면 과 같은 flow의 과제를 분석할 시 프로세스 분석은 유효하게 사용된다.
시간적 FLOW와 STOCK의 구분이 어렵다면, 구조화의 대상이 동사이면 FLOW, 명사이면 STOCK이라고 생각보기.
➡고객수=eatIn+takeOut+delivery : 이를 평일/주말, 아침/낮/밤 6개의 시간순으로 더 세분화하여 ➡고객수={(eatIn평일 아침+eatIn평일 낮+eatIn평일 저녁+eatIn주말 아침+eatIn주말 낮+eatIn주말 저녁)+
(takeOut평일 아침+takeOut평일 낮+takeOut평일 저녁+takeOut주말 아침+takeOut주말 낮+takeOut주말 저녁)+ (delivery 평일 아침+delivery 평일 낮+delivery 평일 저녁+delivery 주말 아침+delivery 주말 낮+delivery 주말 저녁) ➡고객1인당 평균 매출 = 상품단가 * 구입수
도쿄역에서 편의점 이용자수
도쿄역 하루 유동인구 * 편의점 선택률 =(한차량당 탑승 승객 인수 * 하루 평균 만차율 * 1회운행시 차량 갯수 * 도쿄역 하차률 * 1시간당 운행횟수 * 도쿄역 로선갯수) * 하루 운행시간(12시간) * 편의점 선택률
일본 방문 관광객수(마크로매상추정)
여행가능한 총 해외 인구수 * 일본 선택률 = (각 대륙 여행가능 인구수) *
일본에 있는 솜인형 갯수(소유어프로치)
일본 인구 * 솜인형 보유율 * 솜인형 보유인 중 1인당 인형 개수
➡나이축과남녀 축으로 인구를 나누어 모델화 (일본전체인구, 츠보 인구피라미드 이용)
일본에 있는 피어싱의 갯수(소유어프로치)
일본 인구 * 피어싱 보유율 * 피어싱 보유인 중 1인당 피어싱 개수
➡나이축과 남녀 축으로 인구를 나누어 모델화 (일본전체인구, 츠보 인구피라미드 이용)
일본에 있는 자동차의 갯수(소유어프로치)
세대수 * 자동차 보유율 * 고양이 보유자중 1인당 보유중인 자동차 대수
➡세대주 나이와시골/도시부를 축으로 인구를 나누어 모델화 (세대수=일본전체인구/평균세대수, 츠보 인구피라미드 이용)
일본에 있는 고양이의 마릿수(소유어프로치)
일본 세대수* 고양이 보유율 * 고양이 보유자중 1인당 보유중인 고양이 마릿수
➡세대수별 비율과시골/도시부를 축으로 인구를 나누어 모델화 (세대수=일본전체인구/평균세대수, 츠보 인구피라미드 이용)
일본에 있는 쓰레기통 갯수(존재어프로치)
세대 소유 쓰레기통 + 법인소유 쓰레기통(학교 = 세대 소유 쓰레기통 + 회사 쓰레기통 + 학교 쓰레기통
일본에 있는 우체통의 갯수(존재어프로치)
일본 전체 면적 / 우체통 하나당 적용범위 ➡일본 면적 :38만 km2
-이중 1/4평지, 3/4 산지
-산지중 2/3 사람 사는 땅, 1/3사람 안사는 땅
➡우체통 하나당 적용범위는 성인 남성이 걷는 속도 4km에서 몇분만에 우체통 하나가 나오느냐로 계산, 예를 들어 30분 걸어서 한개가 나온다고 하면 4km * 1/2시간 = 2km이므로 반경 2km 당 한개씩 있다는 계산. 따라서, 2km*2km*3.14 = 12.56km2 당 1개가 존재
일본에 있는 편의점의 갯수 (존재어프로치)
일본 전체 면적 / 편의점 하나당 적용범위 ➡일본 면적 :38만 km2
-이중 1/4평지, 3/4 산지
-산지중 2/3 사람 사는 땅, 1/3사람 안사는 땅
-평지를 다시 1/3씩 대 중 소 도시로 나누고, 산지 중 사람 사는 땅을 1/3씩 대 중 소 도시로 나눔
일본에 있는 스타벅스의 갯수(존재어프로치)
우체통이나 편의점처럼 면적베이스로 고루 분포하는 것은 면적베이스로 계산하면 되지만, 스타벅스, 백화점과 같은 점포는 단순히 면적베이스로 계산하는 것보다 駅갯수 베이스로 계산하면 용이하다.
도시의 역수 * 역당 스타벅스 개수 + 도시가 아닌 곳의 역수 * 역당 스타벅스 개수
➡도시의 역수는 도쿄/도쿄이의의 도시를 축으로 나누어 모델화
= (도쿄의 역수 * 1/2) + (도쿄이외의 역수 * 1/3) + (도시가 아닌 곳의 역수 * 1/5)
➡도쿄의 인구 1500만, 도쿄의 역수 650720개. 수도권의 인구 2000만 그외도시 인구 (6000만-3500만)이기 때문에 인구비와 가중치를 곱하여 역수를 계산
➡도쿄 면적 : 가로 80 * 세로40 * 3/4(가장 왼쪽 산지제외) = 2400 (실제 2100)
➡15분당 하나의 역이 있다고 가정하면, 성인의 걸음속도 4km 이므로 1 * 1 * 3.14 이고 이를 2400에서 나누면 약 750개
➡2.5개 역당 1개의 스타벅스가 있다고 가정하면 약 300개의 스타벅스가 도쿄에 존재
※우체통의 갯수, 편의점 갯수, 스타벅스의 갯수 등 장소의 갯수를 구할 때 전국에고르게 퍼져있는 것이라면 면적을 통해서 계산하면 편하지만,
인구에 편중되어 펴져있는 경우라면 단순 면적을 통해서 구하면 왜곡이 많이 발생하므로도쿄인구를 기준으로 관계식을 세우면 편리하다.
가령, 도쿄의 소방서의 갯수를 130개(역수 650/5) 라고 하면, 수도권인구:수도권소방서갯수 = 도쿄인구(1500만):도쿄소방서갯수(130개)와 같은 관계식으로 풀면, 인구가 어느 정도 반영된 장소의 갯수가 도출되게 되므로 왜곡이 적다. 소방서는 인구에 비례하지 않고 사람이 살지 않는 곳에도 존재한다.
1. 도쿄 편의점 갯수 - 대략 5분걸어서 1개 나오므로 1/12 * 4 = 1/3 - 1/3*1/3*3.14 ≒1/3km2당 1개 - 도쿄면적 2400km2 이므로 도쿄 편의 점갯수 7200개
2. 도쿄외 도시 7200 * 3 * 0.9 = 18900개 ≒ 19000개
3. 그외 7200 * 4 * 0.8 = 19600개 ≒ 20000개
따라서 약 47000개
부동산 갯수
부동산 수요 / 부동산 1개당 공급 1. 부동산 수요 - 세대별로 생각해서 일본에 약 4000만세대 - 세대수 * 1년간 부동산 선택률 1인가구 |1200만|0.1 2인가구 |1200만|0.05 3인가구 | 800만| 0.02 4인가구 | 800만| 0.01 120+60+40+8 = 228만
2. 부동산 공급 = 부동산 1개당 1년 맡는 부동산 계약수 한달 평균 4건이라고 하면 1년에 48건
3. 228만 / 50건 = 45600점포(실제10만개라는데 ;)
도쿄 인구
도쿄 23구 인구 + 23구외 인구 1. 도쿄 23구 인구 = 면적 * 인구비 도쿄 23구는 전체 2400km2중 약 1/4로 생각해서 600km2 100m * 100m에 약 100명이 산다고 하면 0.01km2:100명 = 600km2:6,000,000명
2. 도쿄 23구외 인구= 면적 * 인구비 도쿄 23구 외 면적은 전체 1800km2 100m * 100m에 약 50명이 산다고 하면 0.01km2:50명 = 1800km2:9,000,000명
따라서, 1500만명
山手線のつり革の数(ADL)
야마노테선 손잡이수 = 열차의 갯수 * 열차당 손잡이 갯수
1. 열차당 손잡이 갯수 한 차당 손잡이 갯수 * 열차수
①한 차당 손잡이 갯수 열차내의 자리 앞에 손잡이가 있으므로, 자릿수 만큼의 손잡이 + 그 사이사이에 있는 손잡이 수(그림으로 나타내면 편함) ->(4+6+6+4+3+3+3+3+3)*2 = 70
② 열차수 = 11량
따라서, 열차당 손잡이 갯수=70*11=770개
2.야마노테선 열차의 갯수 열차가 5분에 한 대 온다고 가정하고, 각 역마다 5분 정도의 거리가 떨어져 있으므로, 각 역당 한대의 열차가 지나고 있다고 생각하면 됨.
야마노테센의 역의 갯수는 시부야~이케부크로까지 8개 이므로 8개*4 = 약 32개역
따라서, 32개의 열차가 동시에 달리고 있고, 하나의 열차는 한번의 일주후 한 타임만큼 쉰다고하면
64개의 열차가 존재함을 추정할수 있음
따라서, 야마노테선 손잡이수 = 열차의 갯수 * 열차당 손잡이 갯수 = 64개 * 770개
도시의 구성요소★
1. 시민
2. 활동 - 게데스 : 생산, 생활, 위락 - 르 꼬르뷔제(CIAM) : 주거, 근로, 여가, 교통
3. 토지와 시설 - 자연물 - 인공물 - 건축시설 : 주거·상업·공업·공공 시설 - 교통시설 : 도로, 철도, 항만, 공항 등 - 공간시설 : 공원, 녹지, 오픈스페이스 등
일본에 있는 크리닝점의 갯수는
클리닝점의 갯수 = 전체수요 / 1점포당 공급 1. 전체수요 세대수 * 1달간 선택률 * 1달간 1인당 맡기는 옷의 갯수