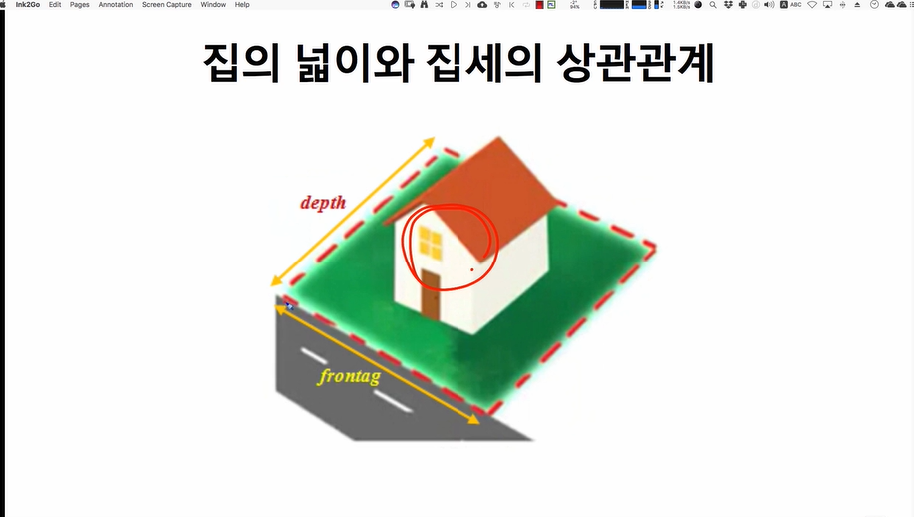
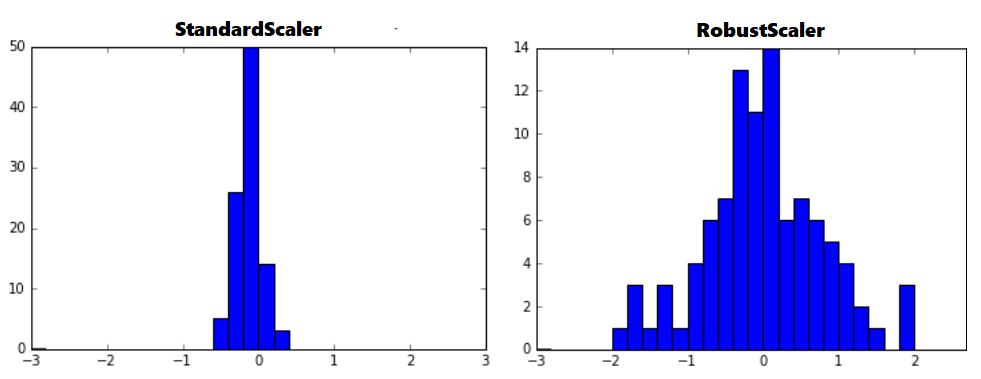
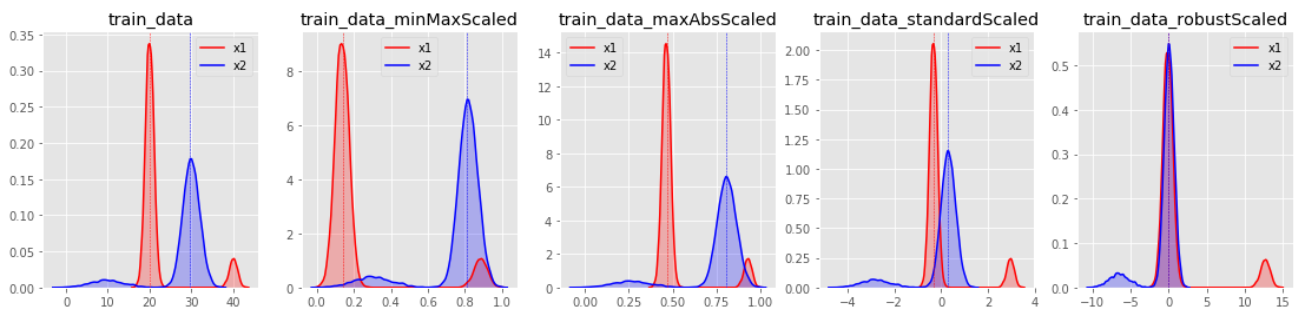
데이터를 모델링하기 전에는 반드시스케일링과정을 거쳐야 한다. 스케일링을 통해다차원의 값들을 비교 분석하기 쉽게만들어주며, 자료의오버플로우(overflow)나 언더플로우(underflow)를 방지하고, 독립 변수의 공분산 행렬의 조건수(condition number)를 감소시켜최적화 과정에서의 안정성 및 수렴 속도를 향상시킨다.
특히 k-means 등 거리 기반의 모델에서는 스케일링이 매우 중요하다.
회귀분석시 조건수라는 개념이 있는데 그 내용은 아래와 같다.
회귀분석에서의 조건수
고유값(Eigenvalue)과 관련된 조건수(Condition Number)의 관계를 나타내는 산식은c = condeig(A)이다.
A의 고유값에 대한 조건수의 벡터를 반환한다. 이 조건수는 좌고유벡터와 우고유벡터 사이 각도의 코사인의 역수이다..라고 하는데,
복잡한 얘기는 생략하고 핵심만 파악해보자.
함수의조건수(condition number)는 argument에서의작은 변화의 비율에 대해 함수가 얼마나 변화할 수 있는지에 대한 argument measure이다.
조건수가 크면 약간의 오차만 있어도 해가 전혀 다른 값을 가진다. 따라서 조건수가 크면 회귀분석을 사용한 예측값도 오차가 커지게 된다.
회귀분석에서 조건수가 커지는 경우는 크게 두 가지가 있다.
1) 변수들의 단위 차이로 인해 숫자의 스케일이 크게 달라지는 경우. 이 경우에는 스케일링(scaling)으로 해결한다.
2) 다중 공선성 즉, 상관관계가 큰 독립 변수들이 있는 경우, 이 경우에는 변수 선택이나 PCA를 사용한 차원 축소 등으로 해결한다.
그리고 다음과 같은 경우에는 로그 함수 혹은 제곱근 함수 등을 사용하여 변환된 변수를 사용하면 회귀 성능이 향상될 수도 있다.
독립 변수나 종속 변수가 심하게 한쪽으로 치우친 분포를 보이는 경우 독립 변수와 종속 변수간의 관계가 곱셈 혹은 나눗셉으로 연결된 경우 종속 변수와 예측치가 비선형 관계를 보이는 경우
대부분 우리가 다루는 데이터 중금액처럼 큰 수치 데이터에 로그를 취하게 되는 이유이기도 하다.
보통 이런 데이터는 선별적으로 로그를 취한 후 모델링 전 전반적으로 스케일링을 적용한다.(in my opinion)
그렇다면 어떤 스케일링 기법을 적용해야할까?
스케일링의 종류
Scikit-Learn에서는 다양한 종류의 스케일러를 제공하고 있다. 그중 대표적인 기법들이다.
L2 regularization은 Ridge reregularization이라 불리고
L1 regularization은 Lasso reregularization이라 불린다
・위식을 보면 왜 regularization을 위해 추가적인 θ값을 붙였는지 이해할 수 있는데
learning rate α < 1
the number of traing dataset m > 10
generally λ < m
이 되므로, λ가 커질 수록 θi값은 감소하게 된다.
・θi값이 작아지면 작아질 수록 변곡점이 평탄해지므로, θi값을 가능한한 작게 만드는 것이 regularization의 목적임을 잊지말자.
・위 그래프는 정규화가 필요한 이유와 그 효과를 설명하기 위한 그래프이다.
・Outlet_identifier_Out027과 Ouutlet_Type_Supermarket_Type3 feature의 계수가 다른 계수에 비해 월등히 큰것을 알 수 있는데, 이는 위의 두 계수에 의해 결과값이 널뛰기를 한다는 것을 의미한다. 따라서, 계수의 크기를 적당히 낮춰주어야할 필요성이 있다.
모델을 학습하려면 모델의 손실을 줄이기 위한 좋은 방법이 필요합니다. 반복 방식은 손실을 줄이는 데 사용되는 일반적인 방법 중 하나로 매우 간편하고 효율적입니다.
To train a model, we need a good way to reduce the model’s loss. An iterative approach is one widely used method for reducing loss, and is as easy and efficient as walking down a hill.
학습 목표(**Learning Objectives)**
반복 방식을 사용하여 모델을 학습하는 방법을 알아봅니다.
Discover how to train a model using an iterative approach.
전체 경사하강법과 다음과 같은변형된 방식을 이해합니다.
Understand full gradient descent and some variants, including:
미니 배치 경사하강법
mini-batch gradient descent
확률적 경사하강법
stochastic gradient descent
학습률을 실험합니다.
Experiment with learning rate.
드디어 손실 줄이기(Reducing Loss) 단원의 마지막 강의인 확률적 경사하강법까지 왔네요.
글 밖에 없어 지루해 보이지만, 같이 살펴보도록 하겠습니다.
확률적 경사하강법(Stochastic Gradient Descent)
먼저 배치(batch) 에 대해서 설명하네요.
경사하강법에서배치는 단일 반복에서 기울기를 계산하는 데 사용하는 예의 총 개수입니다. 지금까지는 배치가 전체 데이터 세트라고 가정했습니다. 하지만 Google 규모의 작업에서는 데이터 세트에 수십억, 수천억 개의 예가 포함되는 경우가 많습니다. 또한 대개 Google 데이터 세트에는 엄청나게 많은 특성이 포함되어 있습니다. 따라서 배치가 거대해질 수 있습니다. 배치가 너무 커지면 단일 반복으로도 계산하는 데 오랜 시간이 걸릴 수 있습니다.
In gradient descent, abatchis the total number of examples you use to calculate the gradient in a single iteration. So far, we've assumed that the batch has been the entire data set. When working at Google scale, data sets often contain billions or even hundreds of billions of examples. Furthermore, Google data sets often contain huge numbers of features. Consequently, a batch can be enormous. A very large batch may cause even a single iteration to take a very long time to compute.
배치(batch) 는 용어집(Gloassary) 에서 더 쉽게 풀어 써놔서, 용어집에 있는 내용을 가져와 보겠습니다.
배치(batch)
모델 학습의 반복 1회, 즉 경사 업데이트 1회에 사용되는 예의 집합입니다.
The set of examples used in one iteration (that is, one gradient update) of model training.
제 나름 더 풀어보자면, 그래프 상에서 1회 이동 하는데 사용되는 데이터, 엑셀로 따지자면 행의 갯수라고 할 수 있습니다.
사진1. 처럼 딱 한 번 이동하는데 쓰이는 데이터라는 말이죠.
사진1. 기울기 벡터
이걸 여러번 해야하는데, 그때마다 데이터를 굉장히 많이 불러온다면 시간이 엄청 오래걸리겠죠.
다음 내용으로 넘어가 보겠습니다.
무작위로 샘플링된 예가 포함된 대량의 데이터 세트에는 중복 데이터가 포함되어 있을 수 있습니다. 실제로 배치 크기가 커지면 중복의 가능성도 그만큼 높아집니다. 적당한 중복성은 노이즈가 있는 기울기를 평활화하는 데 유용할 수 있지만, 배치가 거대해지면 예측성이 훨씬 높은 값이 대용량 배치에 비해 덜 포함되는 경향이 있습니다.
A large data set with randomly sampled examples probably contains redundant data. In fact, redundancy becomes more likely as the batch size grows. Some redundancy can be useful to smooth out noisy gradients, but enormous batches tend not to carry much more predictive value than large batches.
앞서 배치에 전체 데이터를 사용하는 것에는 문제가 있다는 것을 이야기 했습니다.
그래서 여기서는 무작위로 데이터를 일부 뽑아냈을 경우의 문제점을 이야기하고 있습니다.
무작위로 데이터를 뽑아 낼 때 중복 데이터를 뽑아낼 가능성이 있고, 적당한 중복은 도움이 될 수 있다고 합니다.
하지만, 무작위로 뽑아낸 데이터가 너무 많아지면 정확도를 높이는데 영향을 미칠 수 있는 유의미한 데이터의 비중이 낮아지게 된다고 하네요.
중복에 관한 내용은 특성이 한 개 일때를 가정하고 설명한 내용입니다.
강의 자료 제일 밑에 있는 글을 미리 보겠습니다.
간단한 설명을 위해 단일 특성에 대한 경사하강법에 중점을 두었습니다. 물론 경사하강법은 여러 개의 특성을 갖는 특성 세트에도 사용 가능합니다.
To simplify the explanation, we focused on gradient descent for a single feature. Rest assured that gradient descent also works on feature sets that contain multiple features.
특성이 여러 개 있을 때는 중복 데이터는 그냥 제거하면 되죠.
특성이 한 개 일때는 특히나 카테고리컬 데이터라면, 중복되는게 엄청 많아지겠죠.
이 내용은 추후에 실습을 하면서 직접 해봐야 잘 느껴질 것 같습니다.
여기까지의 내용은 결국배치크기가 너무 크면 안좋다!라는걸 말하고 있습니다.
배치 크기가 너무 크면 안좋다는 걸 알았습니다.
그러면 배치 크기를 조절해서 학습하는게 경사하강법 변형된 방식의 핵심이겠네요.
다음 내용을 보겠습니다.
만약에 훨씬 적은 계산으로 적절한 기울기를 얻을 수 있다면 어떨까요? 데이터 세트에서 예를 무작위로 선택하면 (노이즈는 있겠지만) 훨씬 적은 데이터 세트로 중요한 평균값을 추정할 수 있습니다.**확률적 경사하강법(SGD)**은 이 아이디어를 더욱 확장한 것으로서, 반복당 하나의 예(배치 크기 1)만을 사용합니다. 반복이 충분하면 SGD가 효과는 있지만 노이즈가 매우 심합니다. '확률적(Stochastic)'이라는 용어는 각 배치를 포함하는 하나의 예가 무작위로 선택된다는 것을 나타냅니다.
What if we could get the right gradient on average for much less computation? By choosing examples at random from our data set, we could estimate (albeit, noisily) a big average from a much smaller one.**Stochastic gradient descent (SGD)**takes this idea to the extreme--it uses only a single example (a batch size of 1) per iteration. Given enough iterations, SGD works but is very noisy. The term "stochastic" indicates that the one example comprising each batch is chosen at random.
노이즈가 많아서 기울기가 최소값이 되는 구간까지 가는데 여러번 반복이 필요하지만, 계산이 빨라서 더 빨리 도착하겠네요.
일단은 이런게 있구나 하면서 넘어가도록 하겠습니다.
**미니 배치 확률적 경사하강법(미니 배치 SGD)**는 전체 배치 반복과 SGD 간의 절충안입니다. 미니 배치는 일반적으로 무작위로 선택한 10개에서 1,000개 사이의 예로 구성됩니다. 미니 배치 SGD는 SGD의 노이즈를 줄이면서도 전체 배치보다는 더 효율적입니다.
**Mini-batch stochastic gradient descent (mini-batch SGD)**is a compromise between full-batch iteration and SGD. A mini-batch is typically between 10 and 1,000 examples, chosen at random. Mini-batch SGD reduces the amount of noise in SGD but is still more efficient than full-batch.
・위 두식을 보면 single gradient descent와 full-batch gradient descent의 차이를 알 수 있는데,
single gradient descent(왼쪽)은 트레이닝 값(x)을 하나 넣고 최저값을 찾아간다.
full-batch gradient descent(오른쪽)은 트레이닝값을 한번에 모두 이용하여 최저값을 찾아간다.
・gradient descent : 한번에 1개의 트레이닝 데이터만을 사용해 w값을 업데이트
・full-batch gradient descent : 전체의 트레이닝 데이트터를 한번에 이용해 w값을 업데이트
・앞에서 배웠던 내용은 모두 Full-batch gradient descent 였다.
**배치(batch)**
모델 학습의 반복 1회, 즉 경사 업데이트 1회에 사용되는 트레이닝 데이터의 집합입니다.
The set of examples used in one iteration (that is, one gradient update) of model training.
・n은 feature의 개수, m은 트레이닝 데이터의 개수를 의미하므로 WtXi는 모든 데이터 셋이다.
・모든 데이터에 관하여 한번에 wi의 값을 업데이트 하기 때문에 업데이트 횟수가 감소된다.
・local optmizion이 되는 단점이 존재한다. 예를 들어 3차 함수와 같은 경우에 최저값의 변곡점이 아닌 그보다 큰 변곡점의 값(local optmizion)을 반환할 수 도 있다.
・feature가 10개, 트레이닝 데이터가 3억개일 때, 총 30억개의 데이터 한번에 이용해서 업데이트를 시행하기 때문에 메모리가 부족한 문제 발생한다.
・X : 모든 트레이닝 데이터
・트레이닝 데이터를 랜덤으로 셔플
・트레이닝 데이터에서 하나하나를 빼내 feature w값을 업데이트 시킴 (gredient descent)
\*full-batch gradient descent에서는 모든 트레이닝 데이터를 한번에 이용해 w값을 업데이트
・총 데이터가 10000건 있다고 하면, full-batch는 10000
・batch-size : 한 번에 학습되는 데이터의 개수. batch-size를 100으로 가정
・full-batch를 모두 실행하기 위해선 배치를 100번 돌려야함.
・full-batch가 한번 돌면 1epoch이라함.
・hyper-parameter : 사람이 직접 선정해야하는 값. 러닝레이트 같은거
・하나의 트레이닝 데이터를 사용 : gradient descent
트레이닝 데이터 전체를 한번에 사용 : full-batch gradient descent
트레이닝 데이터 전체를 몇 개의 덩어리로 나누어서 사용 : mini-batch stochastic gradient descent