




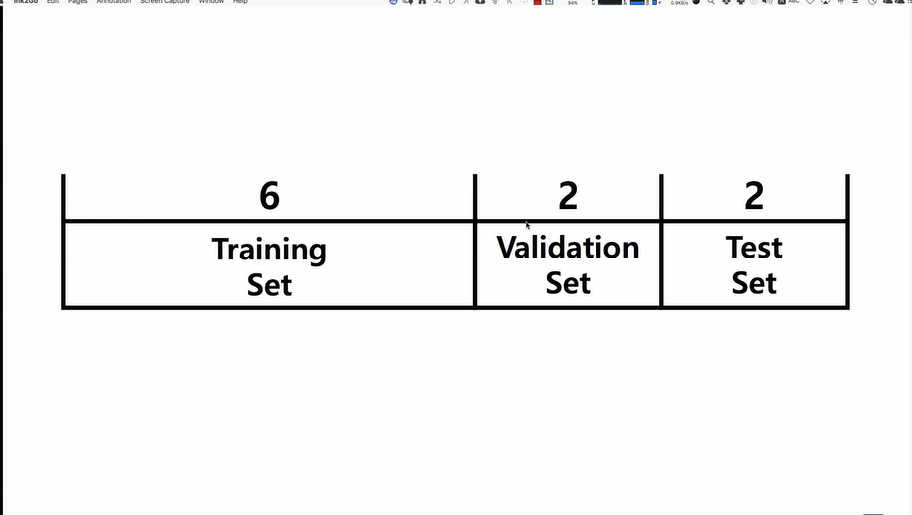
・validation :중간중간에 제대로 만들어지고 있는지를 확인하기 위해서 사용
validation을 안쓸때도 많음



・cross validation
학습데이터를 k번 나누어, test와 training을 실시
구체적으로는 k개로 나눈 데이터를 각각 1,2,3,..k라고 하면
1번 데이터셋 이외의 데이터로 모델을 만든후 1번데이터셋으로 데이터를 테스트하고,
2번 데이터셋 이외의 데이터로 모델을 만든후 2번데이터셋으로 데이터를 테스트하고,
...
k번 데이터셋 이외의 데이터로 모델을 만든후 k번데이터셋으로 데이터를 테스트하고,
의 과정을 반복함
이후에 각 모델의 결과의 평균값으로 모델을 확정
・KFold는 데이터를 뽑아오는게 아니고 인덱스를 뽑아오는 것임


・총 506개의 데이터를 가지고 있는 X에 대하여, KFold를 실시하면 위와 같은 결과가 나오는데 suffle=False이므로 이해하기 쉽다.
TEST데이터 셋이 0~50 / 51 ~ 101 / 102 ~ 152 / .. 순으로 51개씩 균일하게 인덱스가 나뉘어져 있고 그 외의 데이터가 TRAIN데이터 셋으로 인덱싱 된 것을 확인할 수 있다.


・train_index, train_index는 벡터
・X[train_index], y[train_index]는 메트릭스

・사실 위의 코드는 sklearn 프레임웤 안에 포함되어 있다. cross_val_score함수를 사용하면 쉽게 cross validation을 사용할 수 있다.
・이때 scoring='neg_mean_squared_error' 이므로 mse의 마이너스 값이 스코어링 된다. 본래 mse는 작을 수록 좋지만, 마이너스가 붙었으므로 클수록 좋은 스코어링이 된다.
・cv값은 숫자가 들어와도 되지만 kFold 객체가 들어와도 된다.
from sklearn.model\_selection import cross\_val\_score
import numpy as np
lasso\_regressor = Lasso(warm\_start=False)
ridge\_regressor = Ridge()
kf = KFold(n\_splits=10, shuffle=True)
lasso\_scores = cross\_val\_score(lasso\_regressor, X, y, cv=kf, scoring='neg\_mean\_squared\_error')
ridge\_scores= cross\_val\_score(ridge\_regressor, X, y, cv=kf, scoring='neg\_mean\_squared\_error')
[np.mean(lasso\_scores),](np.mean(lasso_scores),) [np.mean(ridge\_scores)](np.mean(ridge_scores))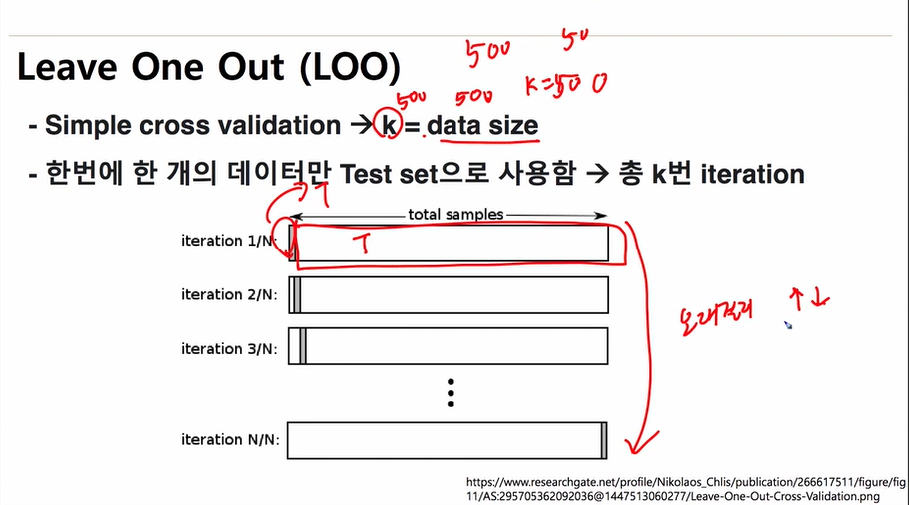



・box plot으로 나타내보면 Lasso 보다 ridge의 정확도가 높은것을 알 수 있지만, 데이터가 더 퍼져있다는 단점이 있다.







'C Lang > machine learing' 카테고리의 다른 글
| 9-2. Sigmoid function (0) | 2019.05.08 |
|---|---|
| 9-1. logistic regression overview (0) | 2019.05.08 |
| 8-6. polynomial regression (0) | 2019.05.06 |
| 8-5. sklearn Linear Model family (0) | 2019.05.06 |
| data processing, type of scalers (0) | 2019.05.06 |